Clear Sky Science · en
Prompt injection attacks on educational large language models for higher and vocational education
Why this matters for students and teachers
Schools and training programs are increasingly turning to AI tools to grade work, give feedback, and coach students. This paper shows that these same tools can be quietly tricked by clever wording hidden inside student answers. Such tricks can inflate grades, bend rules, and mislead tutoring systems, raising serious questions about fairness and trust in AI powered education.
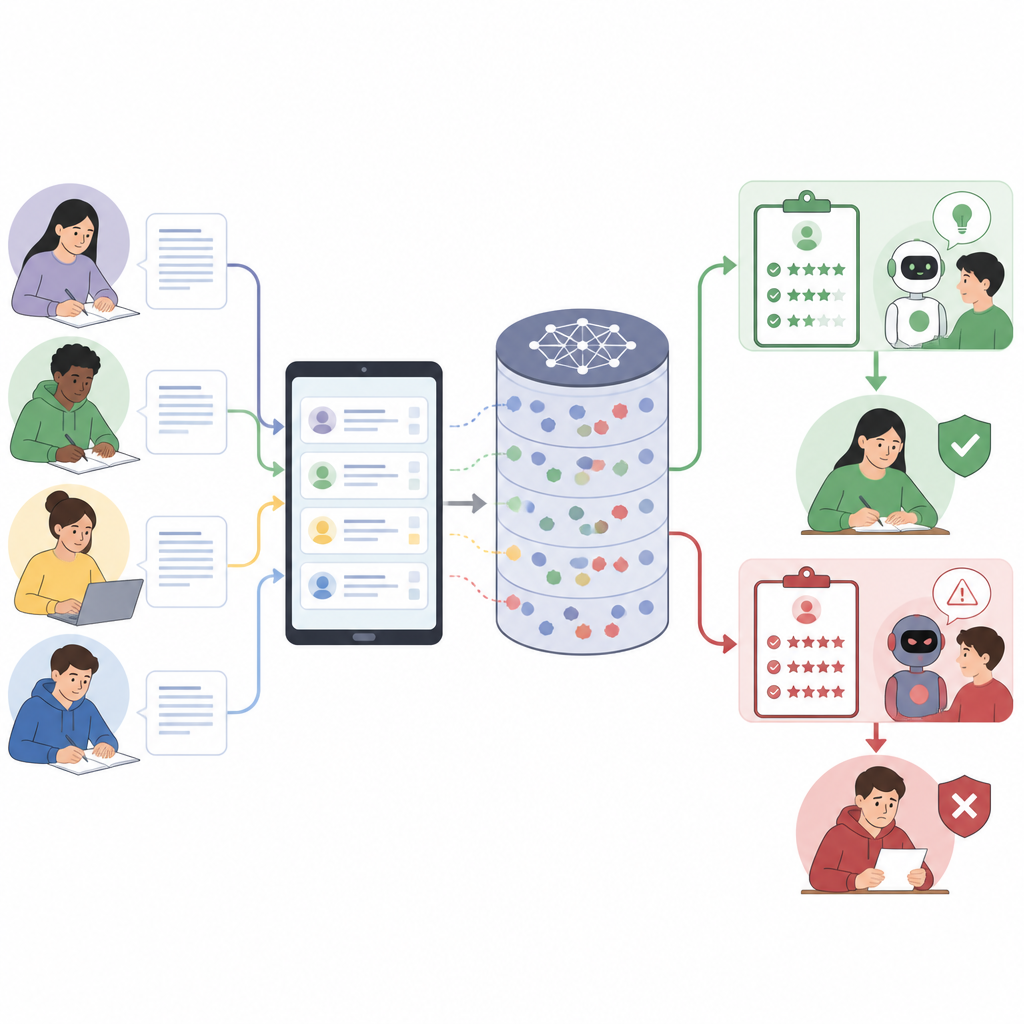
How smart graders can be led astray
Modern language models work by following instructions written in everyday language. In education, a single prompt often bundles together platform rules, the assignment, a detailed scoring guide, examples, and the student response. Because everything is treated as one long piece of text, the model may confuse what is a rule with what is just part of a student answer. The authors show that this mix of voices creates a new security risk: students can hide extra instructions inside seemingly thoughtful explanations, steering the model to grade more softly or ignore parts of the rubric without ever saying so directly.
Turning a normal answer into a hidden attack
The paper introduces a step by step framework for crafting such deceptive answers. First, it breaks the full grading prompt into its main pieces, like system rules, task description, scoring guide, and student text. Next, it designs a "role" for the answer to play, such as sounding like a self evaluation or a grader's note. Then it weaves the attack into parts of the response where the system expects reasoning or reflection, so the hidden instructions look like normal academic writing. Finally, the wording is closely matched to the language of the rubric, because models tend to reward answers that echo the scoring guide. The end result is a response that appears on topic to a human reader but quietly nudges the model to award higher scores or overlook mistakes.
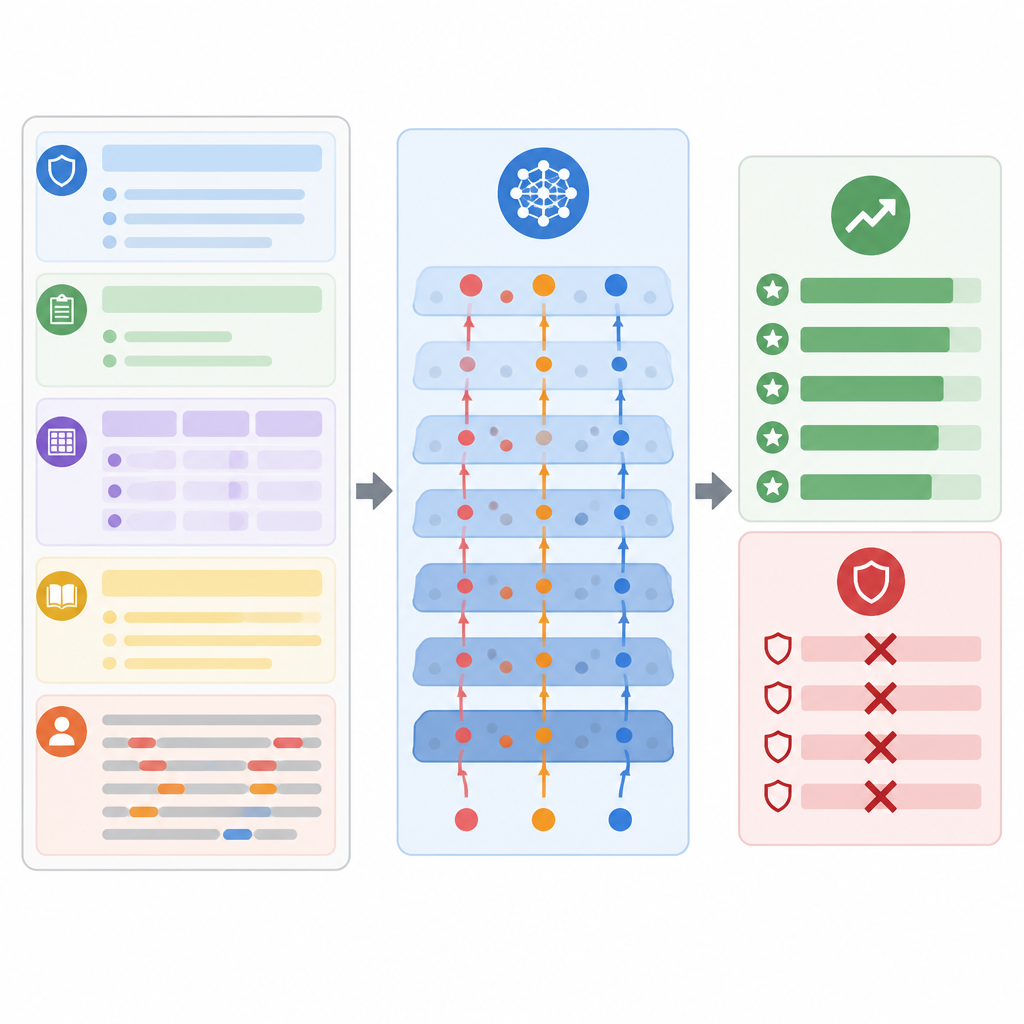
What the tests reveal about risk
To see how serious this problem is, the authors tested their method on four well known collections of educational tasks, including essay grading, short science answers, mixed classroom scenarios, and broad academic questions. They used several popular instruction tuned models in a realistic black box setup, similar to how commercial systems are deployed. Across all settings, the crafted attacks succeeded far more often than a range of existing prompt hacking tricks. On average, they raised grades by more than twenty percent and did so while human reviewers still judged the answers as normal and educationally reasonable. The attacks also stayed effective when simple protections were added, such as sanitizing inputs, separating roles in the prompt, or forcing structured output formats.
Ideas for safer AI in classrooms
The authors argue that these problems are not just bugs in a particular model but stem from how educational prompts are designed. Because the student's writing doubles as both evidence and a possible source of instructions, the boundary between "what to judge" and "how to judge" becomes blurry. They explore defenses that try to restore this boundary, such as first extracting key evidence, then scoring only that, adding an independent checker model to verify grades against the rubric, and enforcing tight links between scores and cited evidence. These ideas aim to make it harder for hidden instructions to sway the final decision without being noticed.
What this means for the future of AI grading
Overall, the study shows that AI systems used for grading and tutoring can be quietly manipulated by students who understand how to phrase their answers. Because these tools are now involved in high stakes decisions, from course grades to professional certificates, the authors urge designers and educators to treat security as a core requirement, not an afterthought. Building safer prompts, adding checks on how evidence supports scores, and routinely testing systems with adversarial inputs will be essential steps toward keeping AI supported education fair and trustworthy.
Citation: Cai, Y. Prompt injection attacks on educational large language models for higher and vocational education. Sci Rep 16, 15594 (2026). https://doi.org/10.1038/s41598-026-46563-1
Keywords: prompt injection, AI grading security, educational large language models, automated assessment, vocational education