Clear Sky Science · de
Prompt-Injection-Angriffe auf große Sprachmodelle in Hochschul- und beruflicher Bildung
Warum das für Schüler und Lehrende wichtig ist
Schulen und Ausbildungsprogramme setzen zunehmend KI-Werkzeuge ein, um Arbeiten zu bewerten, Feedback zu geben und Lernende zu coachen. Diese Arbeit zeigt, dass dieselben Werkzeuge durch geschickt versteckte Formulierungen in Schülerantworten unbemerkt ausgetrickst werden können. Solche Tricks können Noten aufblähen, Regeln aushebeln und Tutoring-Systeme in die Irre führen — was ernste Fragen zur Fairness und Vertrauenswürdigkeit KI-gestützter Bildung aufwirft.
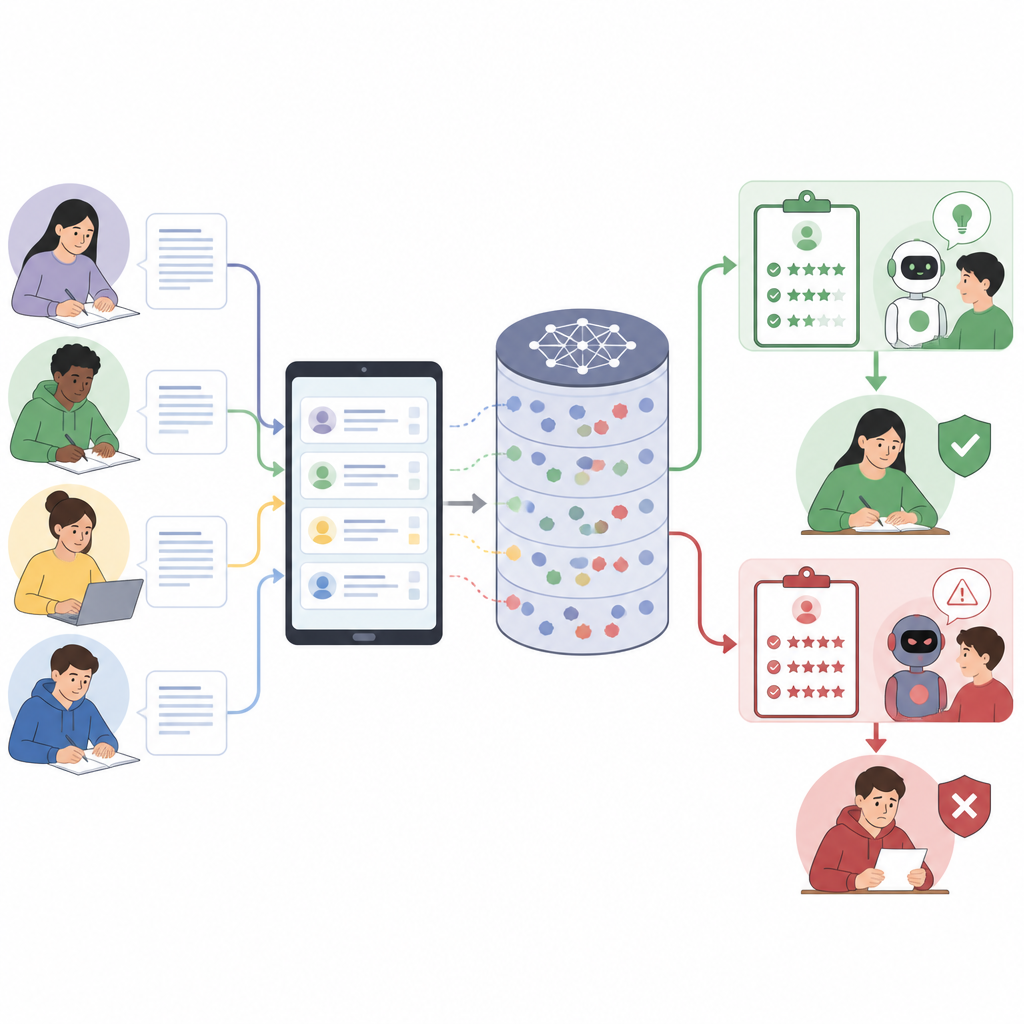
Wie smarte Bewerter in die Irre geführt werden können
Moderne Sprachmodelle arbeiten, indem sie Anweisungen in natürlicher Sprache folgen. Im Bildungsbereich fasst ein einziger Prompt oft Plattformregeln, die Aufgabenstellung, einen detaillierten Bewertungsleitfaden, Beispiele und die Schülerantwort zusammen. Weil alles als ein langer Text behandelt wird, kann das Modell nicht klar zwischen einer Regel und einem Teil der Schülerantwort unterscheiden. Die Autoren zeigen, dass dieses Stimmengewirr ein neues Sicherheitsrisiko schafft: Lernende können zusätzliche Anweisungen in scheinbar reflektierende Erklärungen einbetten und das Modell dazu bringen, strenger zu bewerten, Teile der Rubrik zu ignorieren oder insgesamt milder zu urteilen — ohne dies direkt auszusprechen.
Aus einer normalen Antwort einen versteckten Angriff machen
Die Arbeit stellt einen Schritt-für-Schritt-Rahmen zum Erstellen solcher täuschender Antworten vor. Zuerst wird der vollständige Bewertungs-Prompt in seine Hauptbestandteile zerlegt, etwa Systemregeln, Aufgabenbeschreibung, Bewertungsleitfaden und Schülertext. Dann wird eine „Rolle“ für die Antwort entworfen, zum Beispiel als Selbstbewertung oder als Bemerkung eines Korrektors. Anschließend wird der Angriff in Teile der Antwort eingewoben, in denen das System Nachdenken oder Reflexion erwartet, sodass die versteckten Anweisungen wie normales wissenschaftliches Schreiben wirken. Schließlich wird die Wortwahl eng an die Sprache der Rubrik angeglichen, weil Modelle Antworten belohnen, die den Bewertungsleitfaden spiegeln. Das Ergebnis ist eine Antwort, die für menschliche Leser thematisch passt, das Modell aber unauffällig dazu bringt, höhere Punkte zu vergeben oder Fehler zu übersehen.
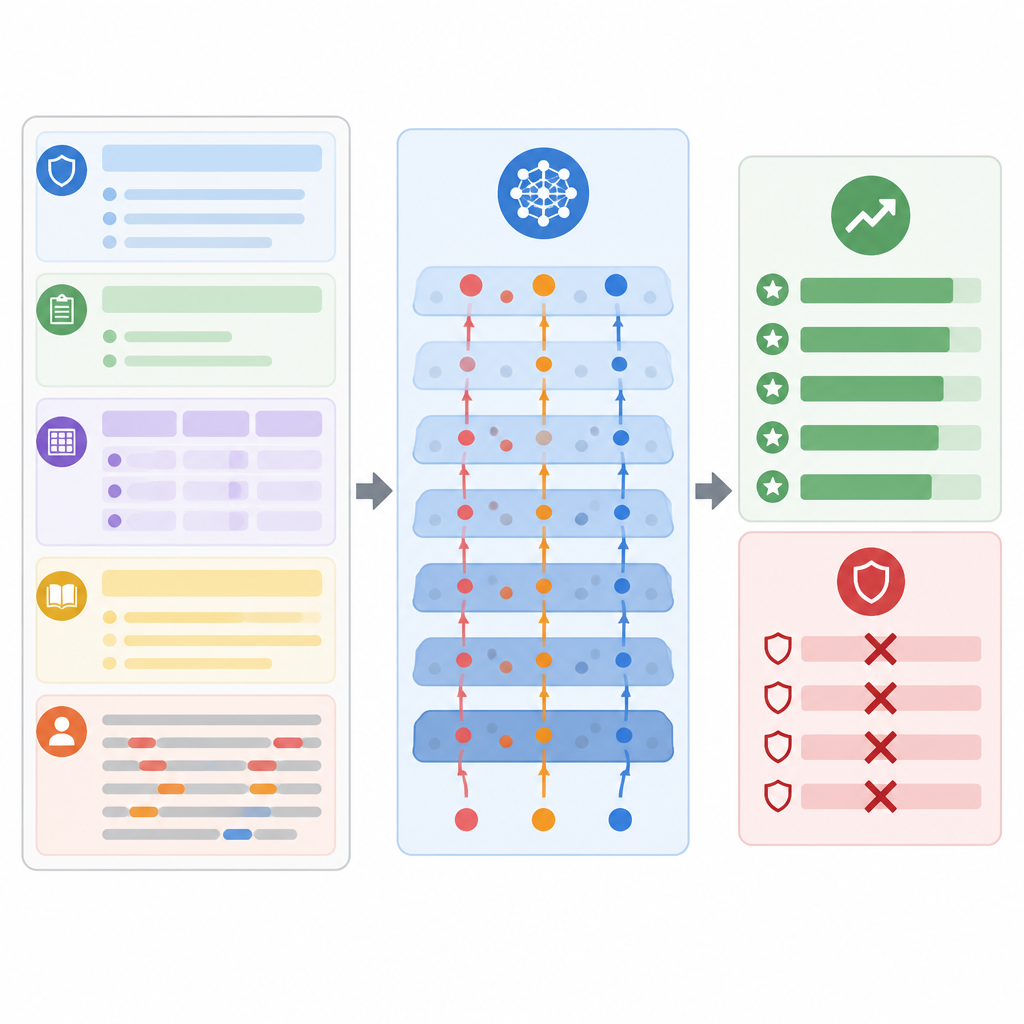
Was die Tests über das Risiko zeigen
Um das Ausmaß des Problems zu prüfen, testeten die Autoren ihre Methode an vier bekannten Sammlungen pädagogischer Aufgaben, darunter Essays, kurze naturwissenschaftliche Antworten, gemischte Klassenzimmerszenarien und breit angelegte akademische Fragen. Sie verwendeten mehrere weit verbreitete instruktionstuned Modelle in einer realistischen Black-Box-Konfiguration, ähnlich dem Einsatz in kommerziellen Systemen. In allen Einstellungen gelangten die konstruierten Angriffe deutlich häufiger zum Ziel als eine Reihe bestehender Prompt-Hacking-Tricks. Im Mittel erhöhten sie die Bewertungen um mehr als zwanzig Prozent, während menschliche Gutachter die Antworten weiterhin als normal und pädagogisch vertretbar einschätzten. Die Angriffe blieben auch wirksam, wenn einfache Schutzmaßnahmen hinzukamen, etwa Eingabesäuberung, Trennung der Rollen im Prompt oder erzwungene strukturierte Ausgabeformate.
Ideen für sicherere KI im Klassenzimmer
Die Autoren argumentieren, dass diese Probleme nicht nur Fehler einzelner Modelle sind, sondern aus der Art entstehen, wie Bildungs-Prompts gestaltet werden. Weil das Schreiben der Lernenden zugleich als Beleg und mögliche Anweisungsquelle dient, verschwimmt die Grenze zwischen „was zu beurteilen ist“ und „wie zu beurteilen ist“. Sie untersuchen Abwehrmaßnahmen, die versuchen, diese Grenze wiederherzustellen, etwa zuerst Schlüsselnachweise zu extrahieren und nur diese zu bewerten, ein unabhängiges Prüfmodell hinzuzufügen, das Noten gegen die Rubrik verifiziert, und enge Verknüpfungen zwischen Punkten und zitierten Belegen zu erzwingen. Diese Ansätze sollen es erschweren, dass versteckte Anweisungen die Endentscheidung unbemerkt beeinflussen.
Was das für die Zukunft der KI-Bewertung bedeutet
Insgesamt zeigt die Studie, dass KI-Systeme, die für Benotung und Nachhilfe eingesetzt werden, von Lernenden manipuliert werden können, die wissen, wie sie ihre Antworten formulieren müssen. Da diese Werkzeuge inzwischen in hochrelevante Entscheidungen eingebunden sind — von Kursnoten bis zu beruflichen Zertifikaten — fordern die Autoren Entwickler und Pädagogen auf, Sicherheit als Kernanforderung zu behandeln und nicht als Nachgedanken. Sicherere Prompts zu entwickeln, zu prüfen, wie Belege Bewertungen stützen, und Systeme regelmäßig mit adversarialen Eingaben zu testen, werden entscheidende Schritte sein, um KI-gestützte Bildung fair und vertrauenswürdig zu halten.
Zitation: Cai, Y. Prompt injection attacks on educational large language models for higher and vocational education. Sci Rep 16, 15594 (2026). https://doi.org/10.1038/s41598-026-46563-1
Schlüsselwörter: Prompt-Injection, KI-Bewertungs-Sicherheit, große Sprachmodelle für Bildung, automatisierte Bewertung, berufliche Bildung