Clear Sky Science · sv
Prediktiv analys av studentengagemang i universitetskurser i idrott utifrån en multimodal transformeralgoritm
Varför detta är viktigt för studenter och lärare
Universitetsidrott ska öka konditionen, skapa goda träningsvanor och förbättra humöret, men många gym och planer ser fortfarande låg närvaro och halvhjärtat deltagande. Denna studie visar hur data från wearables, klassrumskameror och korta skriftliga omdömen kan kombineras för att automatiskt uppskatta hur engagerade studenter faktiskt är under idrottslektioner, vilket ger lärare snabbare och mer objektiv insikt än traditionella checklistor eller sluttermsenkäter.
Förvandla idrottslektioner till rika datakanaler
I moderna idrottskurser bär studenter ofta enheter som mäter puls, steg och rörelse, medan kameror fångar gruppaktiviteter och onlineplattformar samlar korta meddelanden och kommentarer. Forskarna använder en stor nationell datamängd som förenar dessa strömmar för 1 000 universitetsstudenter över tusentals timmar lektionstid. Varje tio minuters segment av lektionen märks av utbildade experter som visar låg, medel eller hög närvaro, baserat på hur studenter rör sig, hur ansträngda deras kroppar är och vad de säger om lektionen. Dessa märkta segment blir träningsmaterial för en datormodell som lär sig av rådata istället för utspridda intryck.
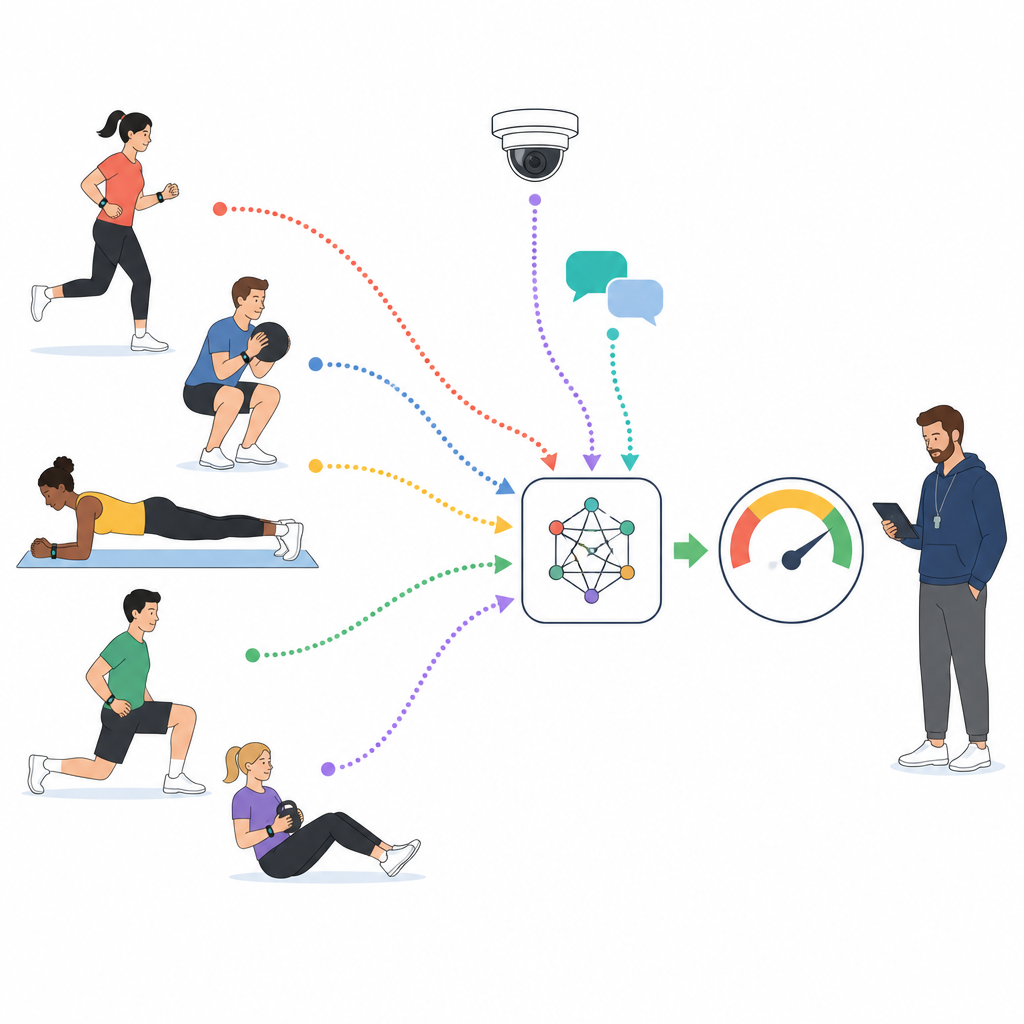
Att lära en modell att läsa kropp, ansikte och ord
I stället för att förlita sig på en enda informationskälla bygger studien en flerskiktsmodell som behandlar sensorer, text och video som jämlika partners. För sensorsignaler som puls och acceleration lär ett sekvensbehandlande nätverk att känna igen mönster som uthållig ansträngning eller upprepade aktivitetsutbrott. För studentkommentarer och korta reflektioner destillerar en språklig modell hela meningar till kompakta representationer som kodar attityd och ton. För videoklipp bryter ett annat nätverk ner varje bildruta i patchar och lär sig hur ansiktsuttryck, kroppshållning och rörelsemönster utvecklas över tid. Alla tre strömmar översätts sedan till ett gemensamt numeriskt rum så att modellen effektivt kan jämföra och kombinera dem.
Hur modellen kopplar signaler till engagemang
Kärnan i tillvägagångssättet är en teknik som låter olika datakanaler uppmärksamma varandra. Först stärker modellen varje kanal individuellt och lär sig intern struktur, såsom trender i puls eller nyckelögonblick i en video. Därefter länkar den kanalerna och ställer frågor som vilka tidsperioder i sensordatan som matchar skriftliga omnämnanden av trötthet, eller vilka videosegment som sammanfaller med språk som tyder på entusiasm. Genom att lära sig dessa korskopplingar bygger systemet en sammanslagen bild av vad som händer med varje student under ett tio minuters fönster. Slutligen matas denna kombinerade bild in i ett enkelt utgångsskikt som producerar både en kontinuerlig engagemangspoäng och en tredelad kategori.
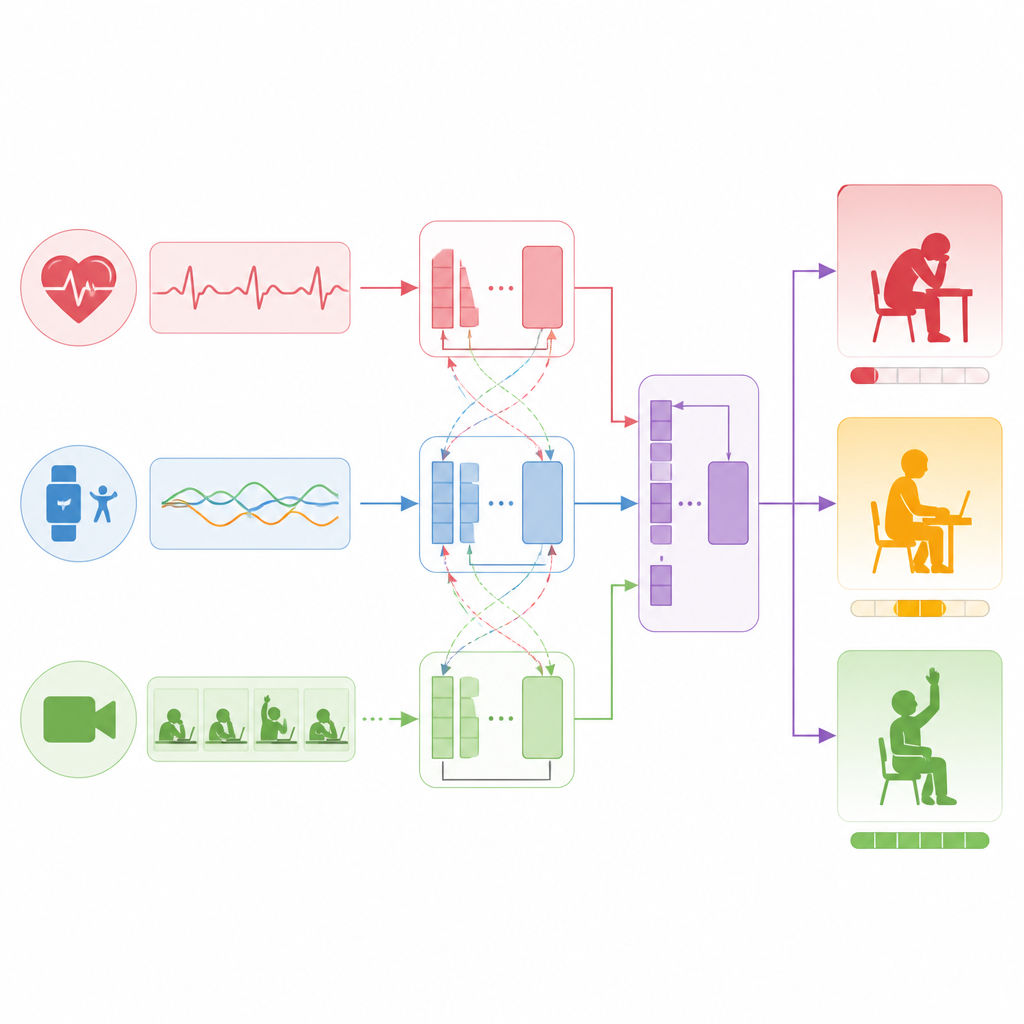
Hur väl systemet fungerar i praktiken
När forskarna jämför sin multimodala modell med en rad befintliga metoder som endast använder sensorer, endast video eller bara två datatyper finner de tydliga förbättringar. Det nya systemet minskar prediktionsfelet med mer än en femtedel jämfört med en stark sensorbasserad referensmodell och når över 90 procent noggrannhet i klassificering av engagemangsnivåer. Viktigt är att det gör detta tillräckligt snabbt för att vara användbart under lektionstid — det tar cirka två tiondelar av en sekund att bearbeta tio minuters data för en student. Tester som tar bort en datatyp i taget visar att alla tre källor är värdefulla, där video bidrar mest, följt av text och sedan sensorer. Ytterligare analys av modellens interna attention-mönster tyder på att den fokuserar på rimliga ledtrådar, såsom att koppla stigande puls till aktiv rörelse och senare trötthet.
Vad detta kan innebära för framtida idrottslektioner
Författarna drar slutsatsen att ett omsorgsfullt utformat multimodalt system kan ge tidsnära och ganska precisa bilder av studenters delaktighet i idrott, och flytta utvärdering från grova intryck mot kontinuerlig, datadriven insikt. Även om tillvägagångssättet är beroende av kameror och wearables och väcker frågor kring integritet och rättvisa, pekar det mot en framtid där lärare får realtidsfeedback om när studenter är fokuserade, uppspelta eller frånvarande, och kan justera aktiviteter på plats i stället för att vänta på slutet-av-terminen-enkäter.
Citering: Li, J. Predictive analysis of student engagement in university physical education courses based on a multimodal transformer algorithm. Sci Rep 16, 15123 (2026). https://doi.org/10.1038/s41598-026-45928-w
Nyckelord: studentengagemang, idrottsundervisning, multimodalt lärande, transformermodell, wearable-sensorer