Clear Sky Science · pl
Analiza predykcyjna zaangażowania studentów na zajęciach wychowania fizycznego na uczelni oparta na multimodalnym algorytmie transformera
Dlaczego to ma znaczenie dla studentów i nauczycieli
Zajęcia sportowe na uczelni powinny poprawiać kondycję, kształtować dobre nawyki ćwiczeniowe i poprawiać nastrój, a mimo to wiele sal gimnastycznych i boisk notuje niską frekwencję i udział na pół gwizdka. To badanie pokazuje, jak dane z urządzeń ubieralnych, kamer w sali i krótkich informacji pisemnych można połączyć, by automatycznie oszacować, jak naprawdę zaangażowani są studenci podczas zajęć wychowania fizycznego, dając nauczycielom szybszy i bardziej obiektywny wgląd niż tradycyjne listy kontrolne czy ankiety semestralne.
Przekształcanie zajęć sportowych w bogate strumienie danych
W nowoczesnych kursach wychowania fizycznego studenci często noszą urządzenia rejestrujące tętno, kroki i ruch, kamery rejestrują aktywności grupowe, a platformy online zbierają krótkie wiadomości i komentarze. Badacze sięgają do dużego krajowego zbioru danych, który łączy te strumienie dla 1 000 studentów uczelni na tysiącach godzin zajęć. Każdy dziesięciominutowy fragment zajęć jest oznaczany przez wyszkolonych ekspertów jako wykazujący niskie, średnie lub wysokie uczestnictwo, na podstawie tego, jak studenci się poruszają, jak intensywnie pracują ich ciała i co mówią o lekcji. Te oznakowane fragmenty stanowią materiał treningowy dla modelu komputerowego, który uczy się odczytywać zaangażowanie z surowych danych zamiast z przypadkowych wrażeń.
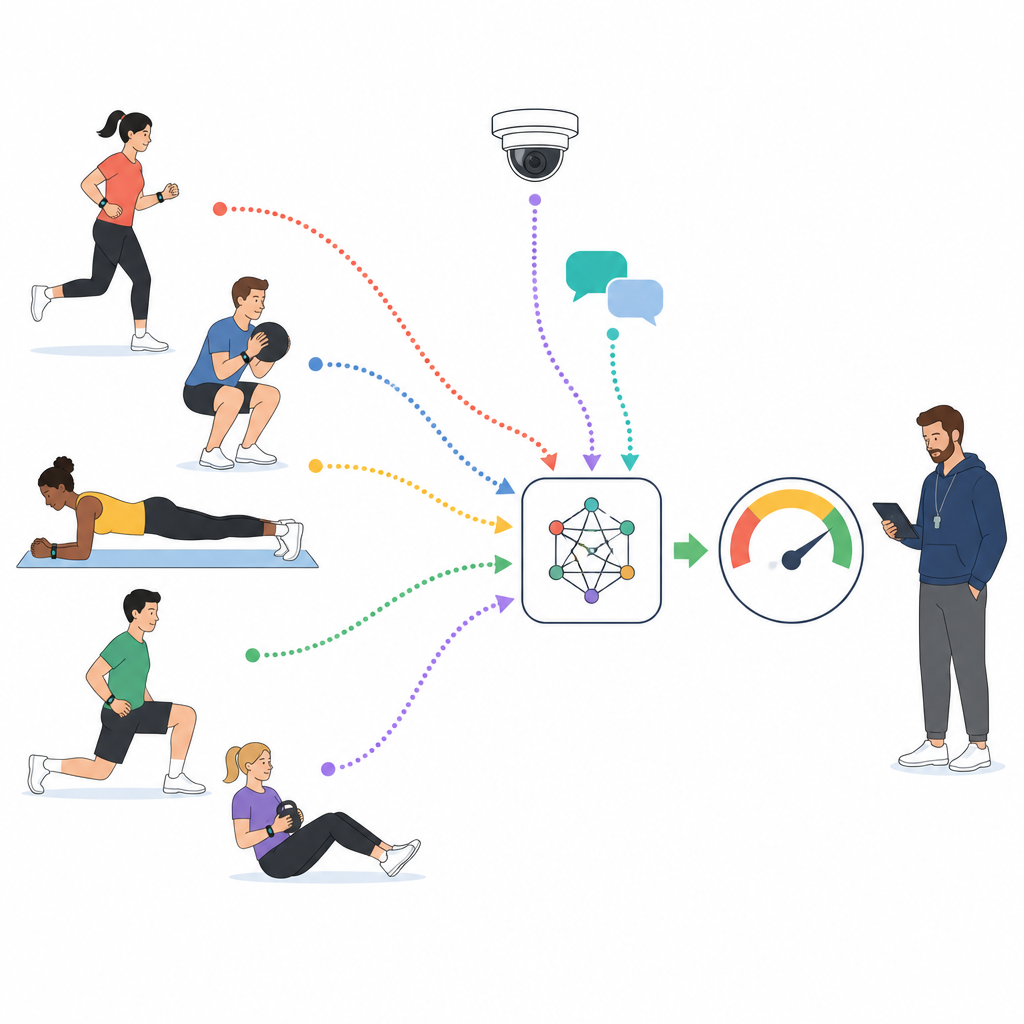
Nauczanie modelu odczytywania ciała, twarzy i słów
Zamiast polegać na jednym źródle informacji, badanie buduje warstwowy model, który traktuje czujniki, tekst i wideo jako równe źródła. Dla sygnałów z czujników, takich jak tętno i przyspieszenie, sieć przetwarzająca sekwencje uczy się rozpoznawać wzorce, np. utrzymujący się wysiłek czy powtarzające się wybuchy aktywności. Dla komentarzy studenckich i krótkich refleksji model językowy kondensuje całe zdania do zwartej reprezentacji, kodującej postawę i ton. Dla klipów wideo inna sieć dzieli każdą klatkę na łatki i uczy się, jak wyrazy twarzy, postura ciała i wzorce ruchu rozwijają się w czasie. Wszystkie trzy strumienie są następnie tłumaczone do wspólnej przestrzeni liczbowej, aby model mógł je skutecznie porównywać i łączyć.
Jak model łączy sygnały z zaangażowaniem
Rdzeniem podejścia jest technika pozwalająca różnym strumieniom danych zwracać na siebie uwagę. Najpierw model wzmacnia każdy strumień indywidualnie, ucząc się wewnętrznej struktury, takiej jak trendy w tętnie czy kluczowe momenty w wideo. Następnie łączy strumienie, zadając pytania typu: które okresy w danych z czujników odpowiadają pisemnym wzmiankom o zmęczeniu, lub które segmenty wideo pokrywają się z językiem sugerującym ekscytację. Ucząc się takich powiązań między modalnościami, system buduje scalony obraz tego, co dzieje się z każdym studentem w ciągu dziesięciominutowego okna. Wreszcie ten zbiorczy obraz zasila prostą warstwę wyjściową, która generuje zarówno ciągły wynik zaangażowania, jak i kategorię w trzech poziomach.
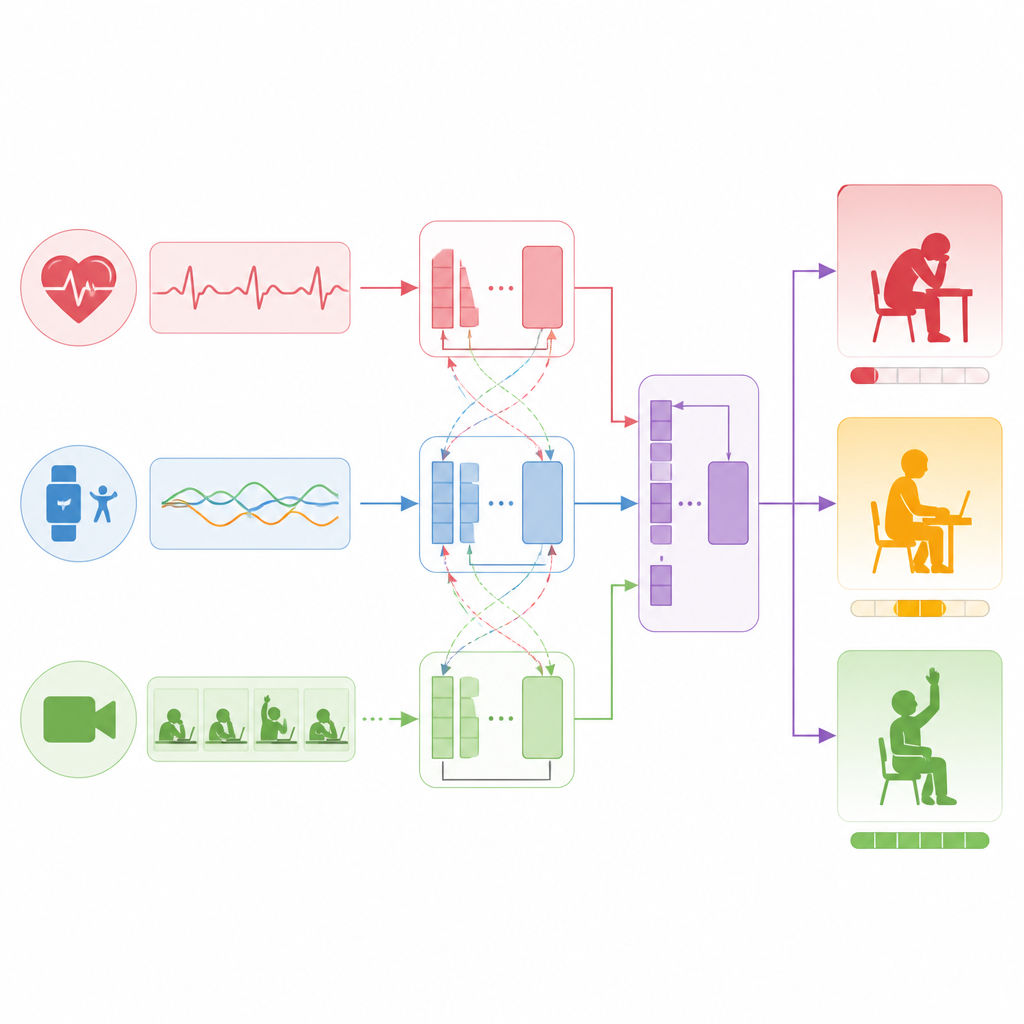
Jak system sprawdza się w praktyce
Gdy badacze porównują swój multimodalny model z szeregiem istniejących metod używających tylko czujników, tylko wideo lub tylko dwóch typów danych, zauważają wyraźne korzyści. Nowy system zmniejsza błąd predykcji o ponad jedną piątą w porównaniu z silną metodą opartą wyłącznie na czujnikach i osiąga ponad 90 procent trafności w klasyfikacji poziomów zaangażowania. Co ważne, działa wystarczająco szybko, by być użytecznym podczas zajęć — potrzebuje około dwóch dziesiątych sekundy, by przetworzyć dziesięć minut danych dla jednego studenta. Testy, w których stopniowo usuwano jeden typ danych, pokazują, że wszystkie trzy źródła są wartościowe; największy wkład ma wideo, następnie tekst, a potem czujniki. Dodatkowa analiza wewnętrznych wzorców uwagi modelu sugeruje, że skupia się on na sensownych wskazówkach, takich jak łączenie rosnącego tętna z aktywnym ruchem i późniejszym zmęczeniem.
Co to może oznaczać dla przyszłych zajęć sportowych
Autorzy dochodzą do wniosku, że starannie zaprojektowany system multimodalny może dostarczać terminowych i stosunkowo dokładnych obrazów zaangażowania studentów na zajęciach wychowania fizycznego, przesuwając ocenę z powierzchownych wrażeń w stronę ciągłego, opartego na danych wglądu. Choć podejście zależy od kamer i urządzeń ubieralnych oraz rodzi pytania o prywatność i sprawiedliwość, wskazuje na przyszłość, w której nauczyciele otrzymują informacje w czasie rzeczywistym o tym, kiedy studenci są skupieni, podekscytowani lub odpływają, i mogą dostosowywać zajęcia na miejscu zamiast czekać na ankiety pod koniec semestru.
Cytowanie: Li, J. Predictive analysis of student engagement in university physical education courses based on a multimodal transformer algorithm. Sci Rep 16, 15123 (2026). https://doi.org/10.1038/s41598-026-45928-w
Słowa kluczowe: zaangażowanie studentów, wychowanie fizyczne, uczenie multimodalne, model transformer, czujniki ubieralne