Clear Sky Science · pt
Análise preditiva do engajamento estudantil em disciplinas de educação física universitária com base em um algoritmo transformador multimodal
Por que isso importa para estudantes e professores
As aulas esportivas universitárias deveriam aumentar a aptidão física, formar hábitos saudáveis de exercício e melhorar o ânimo, mas muitas academias e campos ainda registram baixa frequência e participação desanimada. Este estudo demonstra como dados de dispositivos vestíveis, câmeras em sala e breves retornos escritos podem ser combinados para estimar automaticamente o quanto os alunos estão realmente engajados durante as aulas de educação física, oferecendo aos professores uma visão mais rápida e objetiva do que checklists tradicionais ou pesquisas de fim de semestre.
Transformando aulas esportivas em fluxos de dados ricos
Em cursos modernos de educação física, os alunos frequentemente usam dispositivos que monitoram frequência cardíaca, passos e movimento, enquanto câmeras registram atividades em grupo e plataformas online coletam mensagens e comentários curtos. Os pesquisadores aproveitam um grande conjunto de dados nacional que reúne esses fluxos para 1.000 estudantes universitários ao longo de milhares de horas de aula. Cada fatia de dez minutos da aula é rotulada por especialistas treinados como de participação baixa, média ou alta, com base em como os alunos se movem, o esforço físico que demonstram e o que relatam sobre a aula. Essas fatias rotuladas tornam-se o terreno de treinamento para um modelo computacional que aprende a ler o engajamento a partir de dados brutos em vez de impressões fragmentadas.
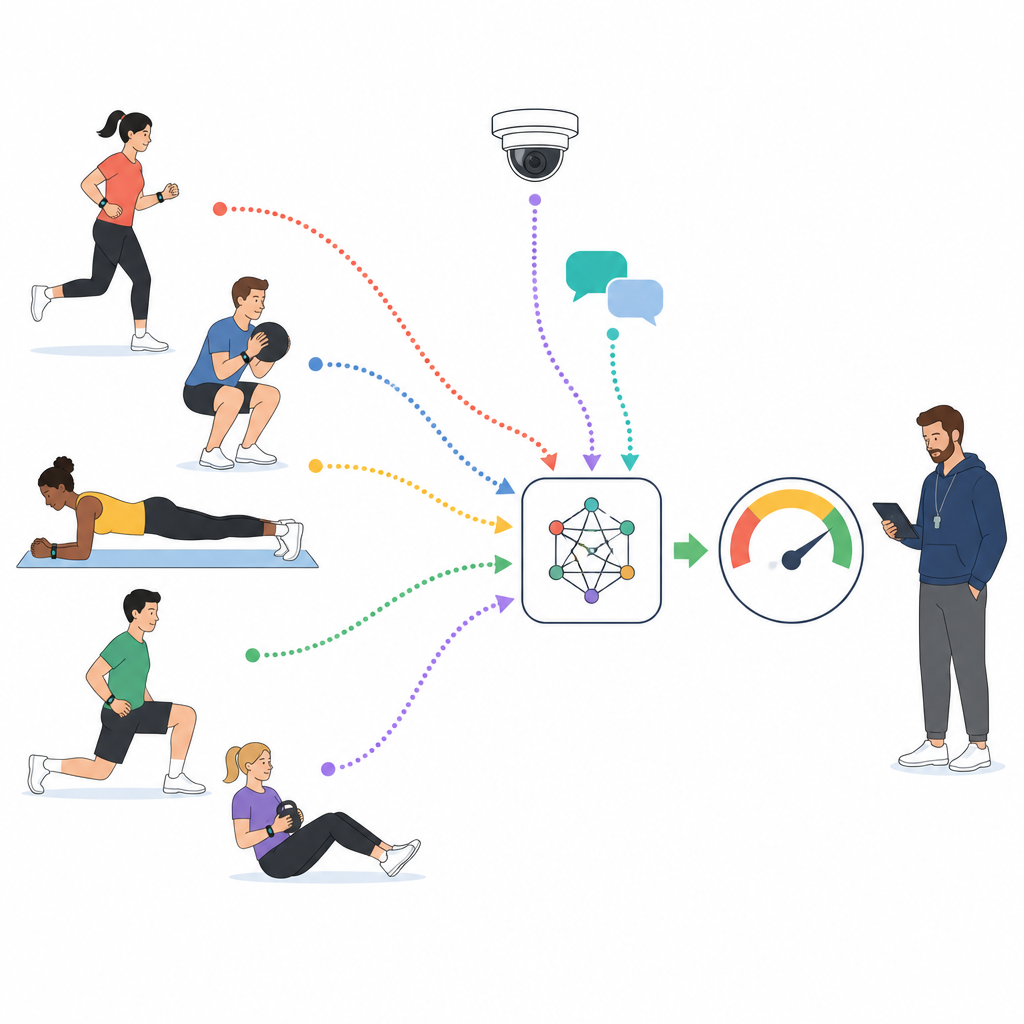
Ensinando um modelo a ler corpo, rosto e palavras
Em vez de depender de uma única fonte de informação, o estudo constrói um modelo em camadas que trata sensores, texto e vídeo como parceiros equivalentes. Para sinais de sensores como frequência cardíaca e aceleração, uma rede de processamento de sequências aprende a identificar padrões como esforço sustentado ou explosões repetidas de atividade. Para comentários e breves reflexões dos estudantes, um modelo de linguagem destila sentenças inteiras em representações compactas que codificam atitude e tom. Para clipes de vídeo, outra rede divide cada quadro em patches e aprende como expressões faciais, postura corporal e padrões de movimento se desenrolam ao longo do tempo. Todas as três streams são então traduzidas para um espaço numérico compartilhado para que o modelo possa compará‑las e combiná‑las de forma eficaz.
Como o modelo conecta sinais ao engajamento
O cerne da abordagem é uma técnica que permite que diferentes fluxos de dados prestem atenção uns aos outros. Primeiro, o modelo fortalece cada fluxo individualmente, aprendendo estruturas internas como tendências na frequência cardíaca ou momentos-chave em um vídeo. Em seguida, ele vincula os fluxos, fazendo perguntas como quais períodos de tempo nos dados do sensor correspondem a menções escritas de cansaço, ou quais segmentos de vídeo coincidem com linguagem que sugere empolgação. Ao aprender essas conexões cruzadas, o sistema constrói uma imagem fundida do que está acontecendo com cada aluno durante uma janela de dez minutos. Por fim, essa imagem combinada alimenta uma camada de saída simples que produz tanto uma pontuação contínua de engajamento quanto uma categoria de três níveis.
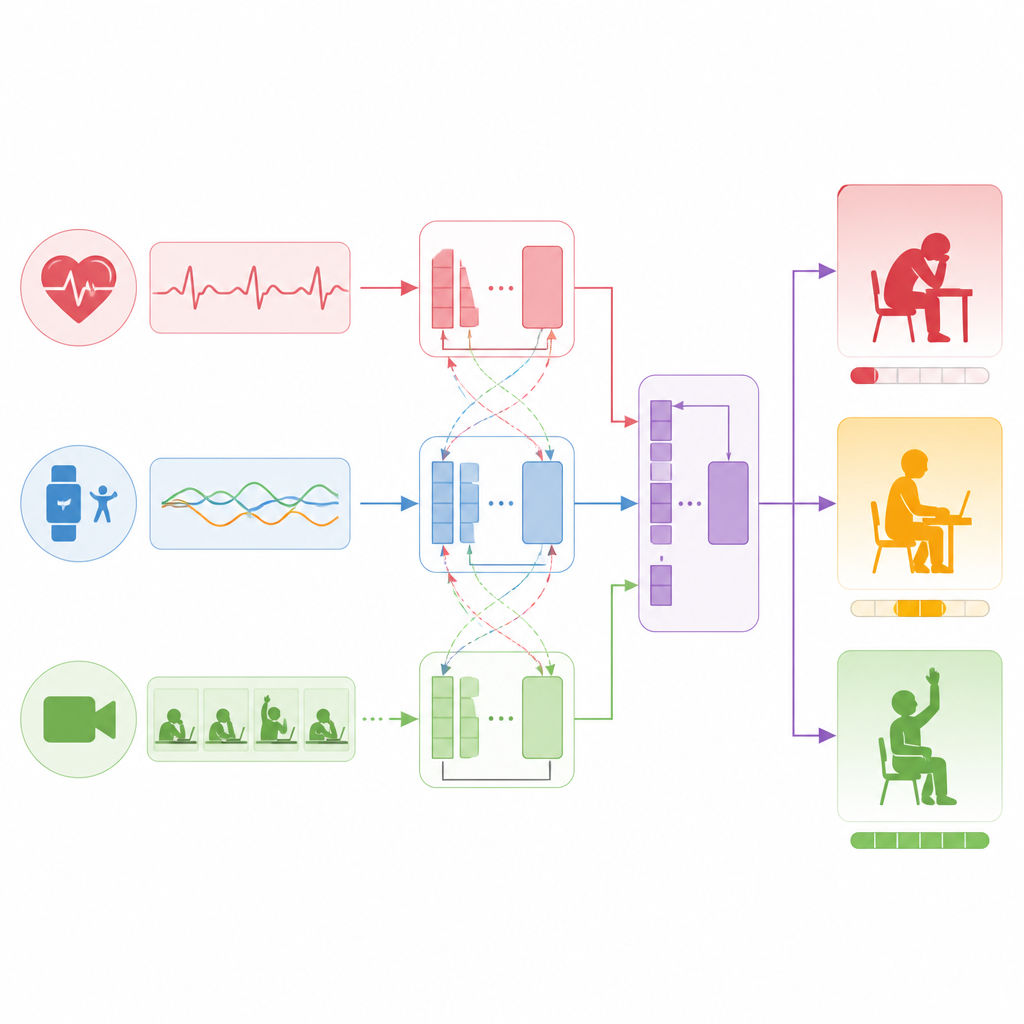
Como o sistema funciona na prática
Quando os pesquisadores comparam seu modelo multimodal com uma série de métodos existentes que usam apenas sensores, apenas vídeo ou apenas dois tipos de dados, eles encontram ganhos claros. O novo sistema reduz o erro de previsão em mais de um quinto em comparação com uma linha de base forte baseada apenas em sensores e alcança mais de 90% de acurácia na classificação dos níveis de engajamento. Importante, faz isso rápido o suficiente para ser útil durante a aula, precisando de cerca de dois décimos de segundo para processar dez minutos de dados de um aluno. Testes que removem um tipo de dado por vez mostram que todas as três fontes são valiosas, com o vídeo contribuindo mais, seguido pelo texto e depois pelos sensores. Análises adicionais dos padrões internos de atenção do modelo sugerem que ele foca em pistas sensatas, como ligar aumento da frequência cardíaca a movimento ativo e fadiga subsequente.
O que isso pode significar para futuras aulas esportivas
Os autores concluem que um sistema multimodal cuidadosamente projetado pode fornecer imagens oportunas e razoavelmente precisas do envolvimento dos alunos na educação física, deslocando a avaliação de impressões aproximadas para insights contínuos orientados por dados. Embora a abordagem dependa de câmeras e dispositivos vestíveis e suscite questões de privacidade e equidade, aponta para um futuro em que professores recebem feedback em tempo real sobre quando os alunos estão focados, empolgados ou dispersos, e podem ajustar as atividades imediatamente em vez de esperar por pesquisas de fim de semestre.
Citação: Li, J. Predictive analysis of student engagement in university physical education courses based on a multimodal transformer algorithm. Sci Rep 16, 15123 (2026). https://doi.org/10.1038/s41598-026-45928-w
Palavras-chave: engajamento estudantil, educação física, aprendizado multimodal, modelo transformador, sensores vestíveis