Clear Sky Science · de
Prädiktive Analyse der Studierendenbeteiligung in universitären Sportunterrichtsveranstaltungen basierend auf einem multimodalen Transformer‑Algorithmus
Warum das für Studierende und Lehrende wichtig ist
Universitäre Sportkurse sollen die Fitness fördern, gesunde Bewegungsgewohnheiten aufbauen und die Stimmung heben, dennoch verzeichnen viele Turnhallen und Sportplätze nach wie vor geringe Anwesenheit und halbherzige Teilnahme. Diese Studie zeigt, wie Daten aus Wearables, Klassenraumkameras und kurzen schriftlichen Rückmeldungen kombiniert werden können, um automatisch einzuschätzen, wie engagiert Studierende während des Sportunterrichts tatsächlich sind. Das bietet Lehrenden schnellere und objektivere Einblicke als traditionelle Checklisten oder Abschlussbefragungen.
Sportunterricht als reichhaltiger Datenstrom
In modernen Sportunterrichtskursen tragen Studierende häufig Geräte, die Herzfrequenz, Schritte und Bewegung erfassen, während Kameras Gruppenaktivitäten aufzeichnen und Online‑Plattformen kurze Nachrichten und Kommentare sammeln. Die Forschenden greifen auf einen großen nationalen Datensatz zu, der diese Ströme für 1.000 Studierende über tausende Stunden Unterrichtszeit zusammenführt. Jede zehnminütige Unterrichtssequenz wird von geschulten Expertinnen und Experten als geringe, mittlere oder hohe Teilnahme etikettiert, basierend auf Bewegungen, körperlicher Belastung und Äußerungen der Studierenden zum Unterricht. Diese gelabelten Sequenzen dienen als Trainingsgrundlage für ein Computermodell, das lernt, Engagement aus Rohdaten zu lesen statt aus verstreuten Eindrücken.
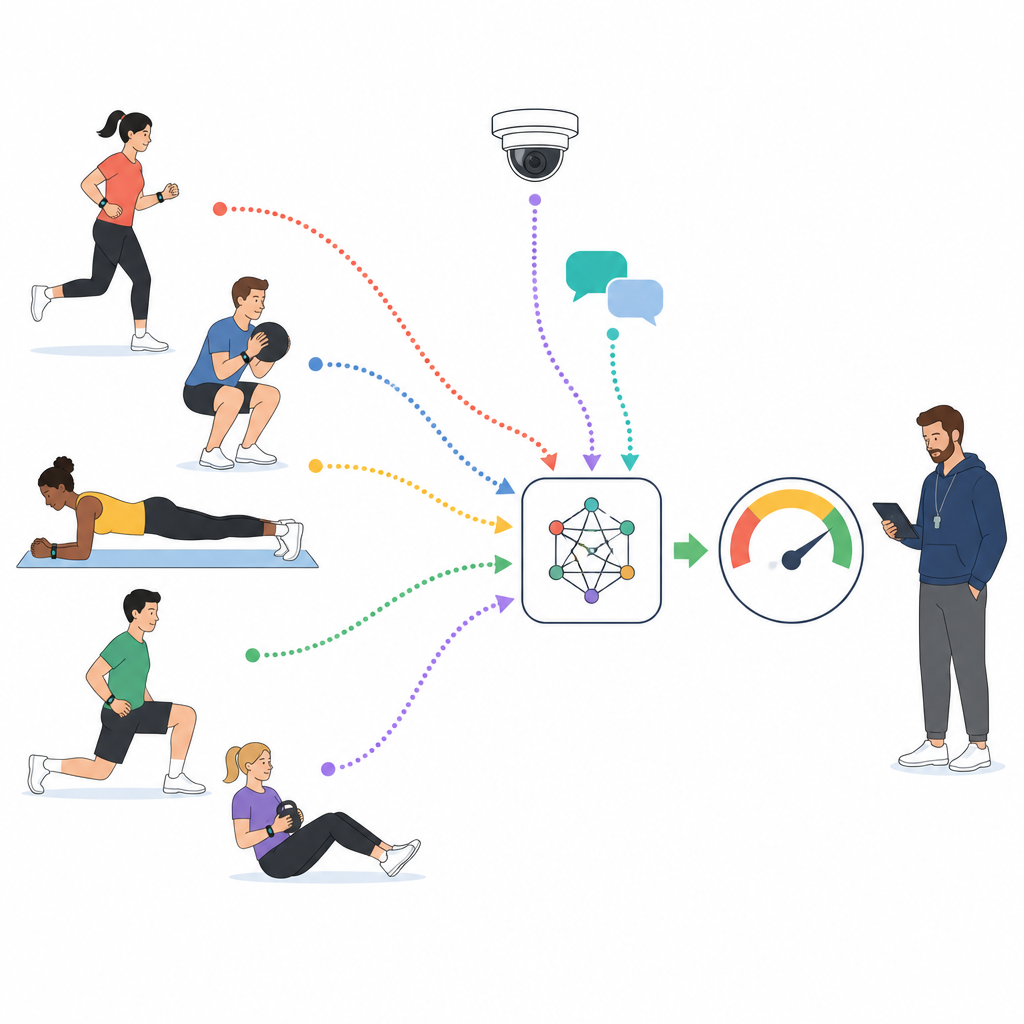
Dem Modell beibringen, Körper, Gesicht und Worte zu lesen
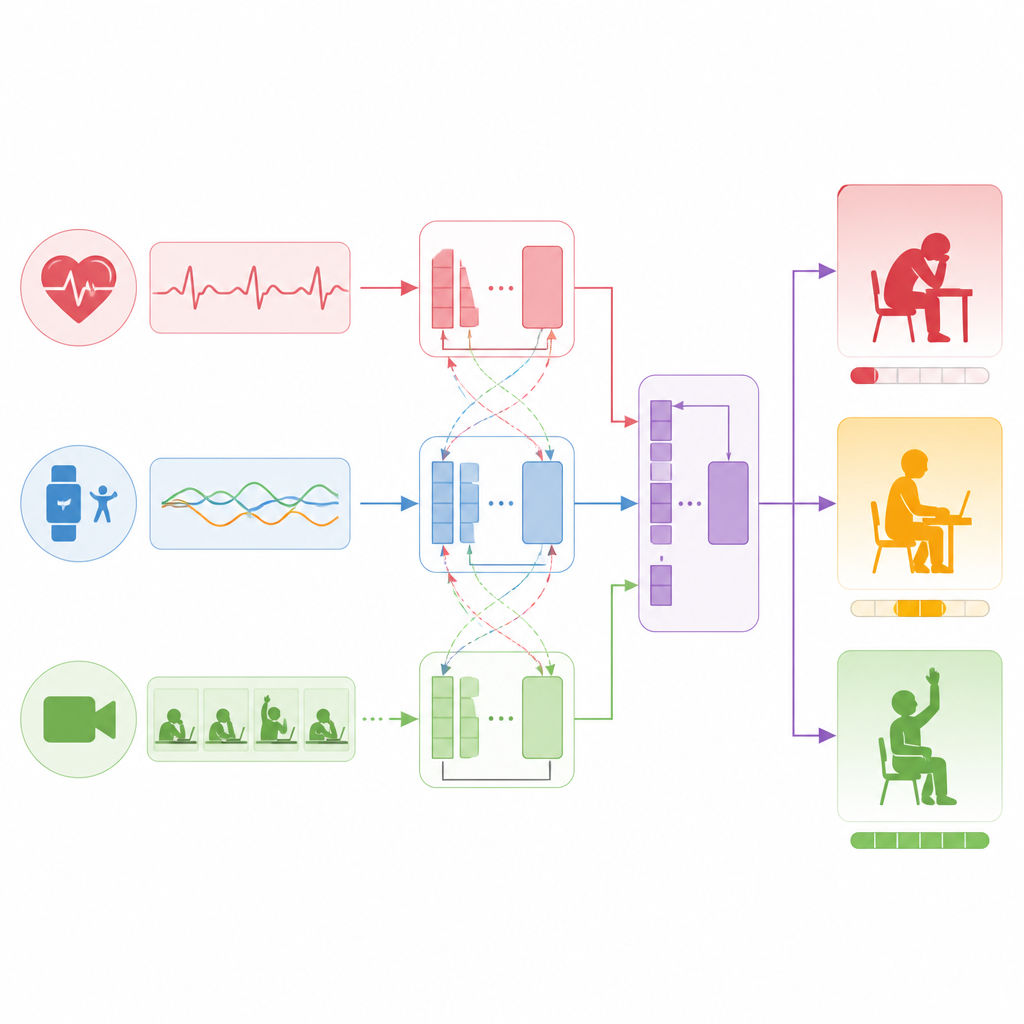
Statt sich auf eine einzelne Informationsquelle zu verlassen, baut die Studie ein geschichtetes Modell, das Sensoren, Text und Video als gleichberechtigte Partner behandelt. Für Sensorsignale wie Herzfrequenz und Beschleunigung lernt ein sequenzverarbeitendes Netzwerk Muster zu erkennen, etwa anhaltende Anstrengung oder wiederholte Aktivitätsausbrüche. Für Studierendenkommentare und kurze Reflexionen destilliert ein Sprachmodell ganze Sätze in kompakte Repräsentationen, die Haltung und Tonfall kodieren. Für Videoclips zerlegt ein anderes Netzwerk jede Bildaufnahme in Patches und lernt, wie Gesichtsausdrücke, Körperhaltung und Bewegungsmuster sich über die Zeit entfalten. Alle drei Ströme werden dann in einen gemeinsamen numerischen Raum übersetzt, sodass das Modell sie effektiv vergleichen und kombinieren kann.
Wie das Modell Signale mit Beteiligung verknüpft
Der Kern des Ansatzes ist eine Technik, die verschiedenen Datenströmen erlaubt, aufeinander Acht zu geben. Zuerst stärkt das Modell jeden Strom einzeln und lernt interne Strukturen wie Trends in der Herzfrequenz oder Schlüsselmomente in einem Video. Anschließend verknüpft es die Ströme und stellt Fragen wie, welche Zeitabschnitte in den Sensordaten mit schriftlichen Erwähnungen von Müdigkeit übereinstimmen oder welche Videosegmente mit Formulierungen korrelieren, die Aufregung andeuten. Durch das Lernen dieser Querverbindungen erstellt das System ein zusammengeführtes Bild dessen, was bei jeder Studierendenperson während eines zehnminütigen Zeitfensters passiert. Schließlich speist dieses kombinierte Bild eine einfache Ausgabeschicht, die sowohl einen kontinuierlichen Engagement‑Score als auch eine dreistufige Kategorie erzeugt.
Wie gut das System in der Praxis funktioniert
Wenn die Forschenden ihr multimodales Modell mit einer Reihe bestehender Methoden vergleichen, die nur Sensoren, nur Video oder nur zwei Datentypen verwenden, zeigen sich deutliche Vorteile. Das neue System reduziert den Vorhersagefehler um mehr als ein Fünftel gegenüber einer starken Sensor‑Only‑Basislinie und erzielt über 90 Prozent Genauigkeit bei der Klassifikation der Beteiligungsstufen. Wichtig ist, dass es schnell genug arbeitet, um im Unterricht nützlich zu sein: Es benötigt etwa zwei Zehntelsekunden, um zehn Minuten Daten für eine Person zu verarbeiten. Tests, bei denen jeweils ein Datentyp weggelassen wurde, zeigen, dass alle drei Quellen wertvoll sind, wobei Video den größten Beitrag leistet, gefolgt von Text und dann Sensoren. Eine zusätzliche Analyse der internen Attention‑Muster des Modells legt nahe, dass es sich auf sinnvolle Hinweise konzentriert, etwa das Verknüpfen steigender Herzfrequenz mit aktiver Bewegung und darauf folgender Ermüdung.
Was das für zukünftigen Sportunterricht bedeuten könnte
Die Autorinnen und Autoren schließen, dass ein sorgfältig gestaltetes multimodales System zeitnahe und relativ genaue Einblicke in die Beteiligung von Studierenden im Sportunterricht liefern kann und damit die Bewertung von groben Eindrücken hin zu kontinuierlichen, datengetriebenen Einsichten verschiebt. Obwohl der Ansatz auf Kameras und Wearables angewiesen ist und Datenschutz‑ sowie Fairnessfragen aufwirft, weist er auf eine Zukunft hin, in der Lehrende Echtzeit‑Feedback erhalten, wann Studierende konzentriert, begeistert oder abgelenkt sind, und Aktivitäten sofort anpassen können statt auf Semesterendbefragungen zu warten.
Zitation: Li, J. Predictive analysis of student engagement in university physical education courses based on a multimodal transformer algorithm. Sci Rep 16, 15123 (2026). https://doi.org/10.1038/s41598-026-45928-w
Schlüsselwörter: Studierendenbeteiligung, Sportunterricht, multimodales Lernen, Transformer‑Modell, Wearable‑Sensoren