Clear Sky Science · es
Análisis predictivo del compromiso estudiantil en cursos universitarios de educación física basado en un algoritmo transformador multimodal
Por qué esto importa para estudiantes y profesores
Las clases universitarias de deporte deberían mejorar la forma física, fomentar buenos hábitos de ejercicio y elevar el ánimo; sin embargo, muchos gimnasios y campos siguen registrando baja asistencia y participación poco entusiasta. Este estudio muestra cómo los datos de dispositivos ponibles, cámaras de aula y comentarios breves por escrito pueden combinarse para estimar automáticamente cuánto se involucran los estudiantes durante las clases de educación física, ofreciendo a los docentes una visión más rápida y objetiva que las listas de control tradicionales o las encuestas de fin de curso.
Convertir las clases deportivas en flujos de datos ricos
En los cursos modernos de educación física, los estudiantes a menudo llevan dispositivos que registran la frecuencia cardíaca, los pasos y el movimiento, mientras que las cámaras capturan actividades grupales y las plataformas en línea recogen mensajes y comentarios cortos. Los investigadores aprovechan un gran conjunto de datos nacional que integra estas corrientes para 1.000 estudiantes universitarios durante miles de horas de clase. Cada segmento de diez minutos de clase es etiquetado por expertos entrenados como de baja, media o alta participación, en función de cómo se mueven los estudiantes, cuánto esfuerzo físico realizan y qué dicen sobre la lección. Estos fragmentos etiquetados se convierten en el terreno de entrenamiento para un modelo informático que aprende a leer el compromiso a partir de datos crudos en lugar de impresiones dispersas.
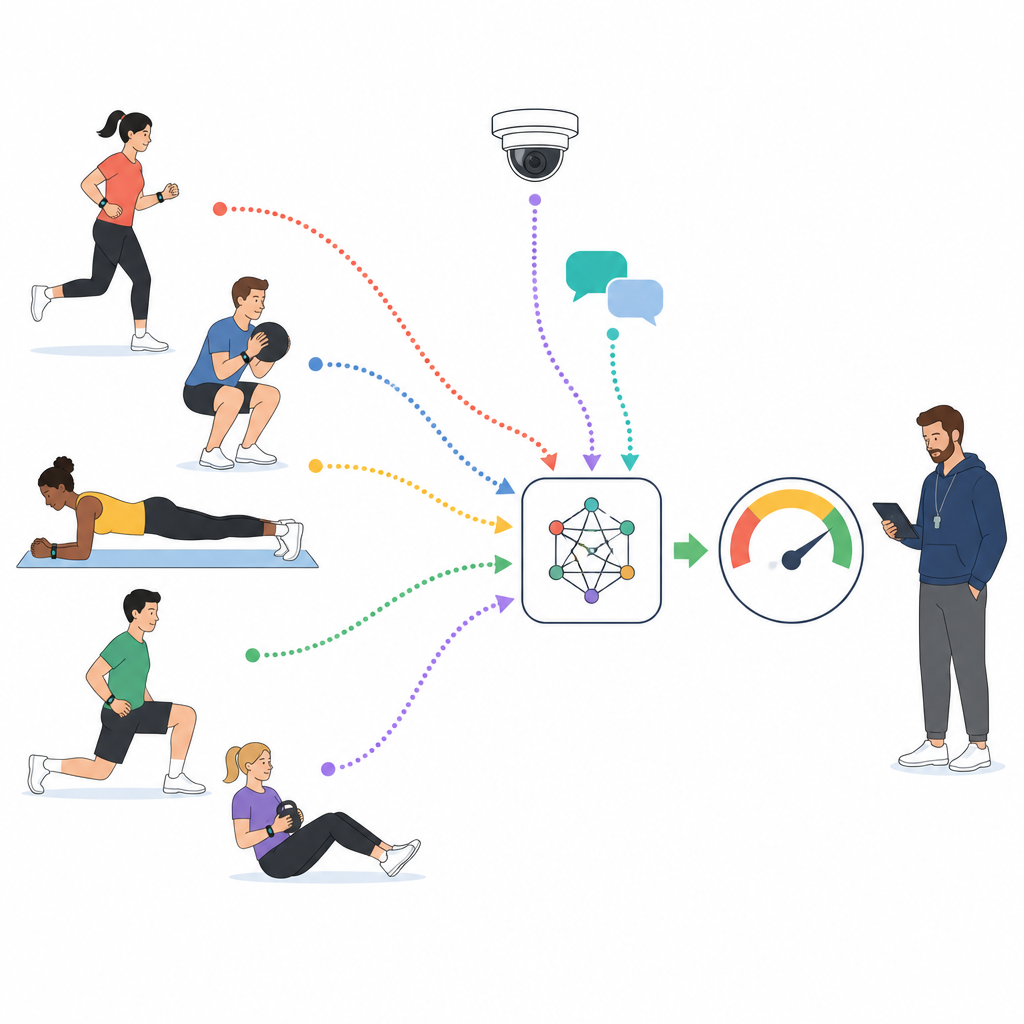
Enseñar a un modelo a leer el cuerpo, la cara y las palabras
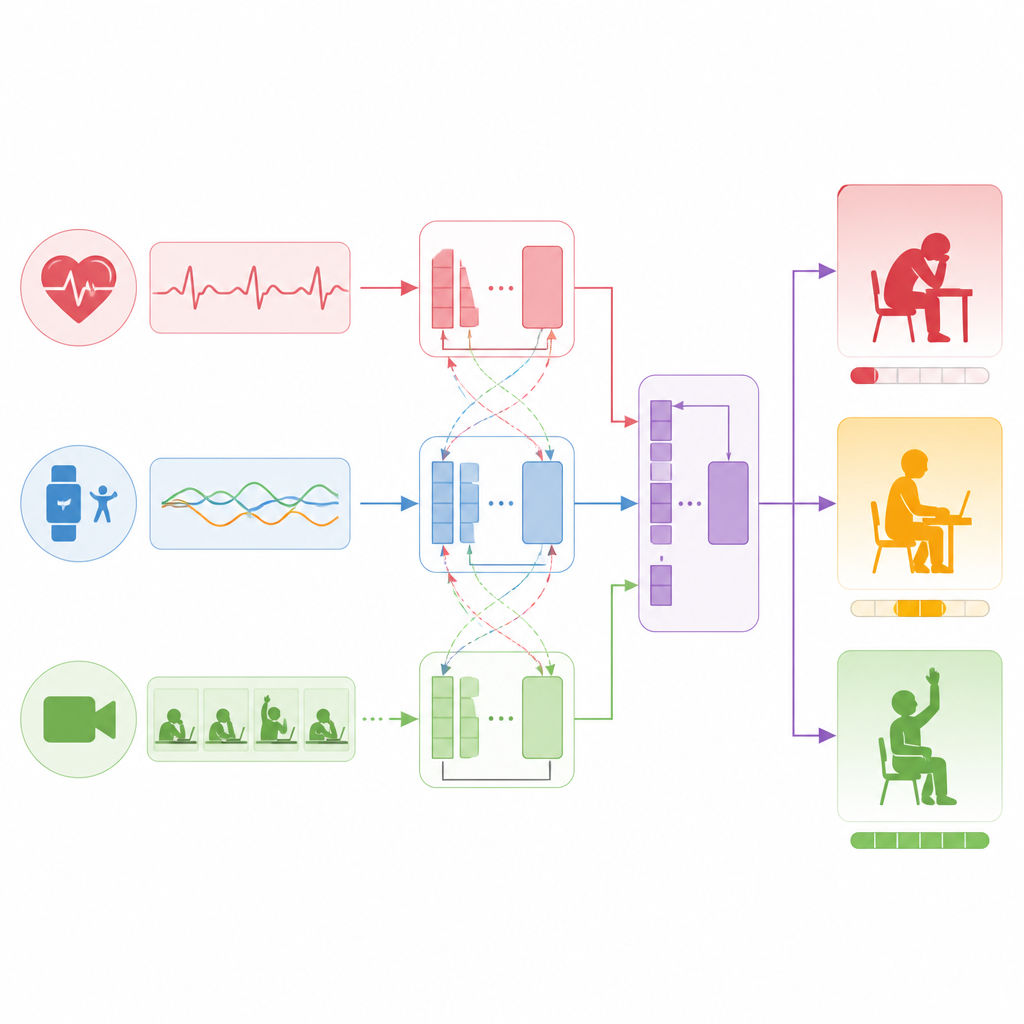
En lugar de depender de una única fuente de información, el estudio construye un modelo por capas que trata a sensores, texto y vídeo como socios equivalentes. Para las señales de los sensores, como la frecuencia cardíaca y la aceleración, una red de procesamiento de secuencias aprende a detectar patrones como esfuerzo sostenido o ráfagas repetidas de actividad. Para los comentarios y reflexiones breves de los estudiantes, un modelo de lenguaje destila frases enteras en representaciones compactas que codifican actitud y tono. Para los clips de vídeo, otra red divide cada fotograma en parches y aprende cómo las expresiones faciales, la postura corporal y los patrones de movimiento se desarrollan en el tiempo. Las tres corrientes se traducen luego a un espacio numérico compartido para que el modelo pueda compararlas y combinarlas de forma eficaz.
Cómo el modelo conecta señales con el compromiso
El núcleo del enfoque es una técnica que permite a las distintas corrientes de datos prestarse atención entre sí. Primero, el modelo refuerza cada corriente de forma individual, aprendiendo estructuras internas como tendencias en la frecuencia cardíaca o momentos clave en un vídeo. A continuación, enlaza las corrientes, planteando preguntas como qué periodos temporales en los datos de sensores coinciden con menciones escritas de sentirse cansado, o qué segmentos de vídeo se alinean con lenguaje que sugiere entusiasmo. Al aprender estos vínculos cruzados, el sistema construye una imagen fusionada de lo que ocurre con cada estudiante durante una ventana de diez minutos. Finalmente, esta imagen combinada alimenta una capa de salida simple que produce tanto una puntuación continua de compromiso como una categoría de tres niveles.
Qué tan bien funciona el sistema en la práctica
Cuando los investigadores comparan su modelo multimodal con una variedad de métodos existentes que usan solo sensores, solo vídeo o apenas dos tipos de datos, encuentran mejoras claras. El nuevo sistema reduce el error de predicción en más de una quinta parte en comparación con una sólida línea base que usa solo sensores y alcanza más del 90 por ciento de precisión en la clasificación de los niveles de compromiso. Es importante que lo haga con la suficiente rapidez como para ser útil durante la clase, necesitando unos dos décimos de segundo para procesar diez minutos de datos de un estudiante. Pruebas que eliminan un tipo de dato a la vez muestran que las tres fuentes son valiosas, con el vídeo aportando más, seguido por el texto y luego los sensores. Un análisis adicional de los patrones de atención internos del modelo sugiere que se centra en señales sensatas, como relacionar el aumento de la frecuencia cardíaca con el movimiento activo y la fatiga posterior.
Qué podría significar esto para futuras clases de deporte
Los autores concluyen que un sistema multimodal bien diseñado puede ofrecer imágenes oportunas y bastante precisas de la implicación estudiantil en educación física, desplazando la evaluación de impresiones aproximadas hacia una visión continua impulsada por datos. Si bien el enfoque depende de cámaras y dispositivos ponibles y plantea cuestiones de privacidad y equidad, apunta a un futuro en el que los docentes reciban retroalimentación en tiempo real sobre cuándo los estudiantes están concentrados, entusiasmados o desconectándose, y puedan ajustar las actividades en el momento en lugar de esperar las encuestas de fin de semestre.
Cita: Li, J. Predictive analysis of student engagement in university physical education courses based on a multimodal transformer algorithm. Sci Rep 16, 15123 (2026). https://doi.org/10.1038/s41598-026-45928-w
Palabras clave: compromiso estudiantil, educación física, aprendizaje multimodal, modelo transformador, sensores ponibles