Clear Sky Science · fr
Analyse prédictive de l’engagement des étudiants dans les cours d’éducation physique universitaire basée sur un algorithme transformeur multimodal
Pourquoi c’est important pour les étudiants et les enseignants
Les cours de sport universitaires sont censés améliorer la condition physique, favoriser de bonnes habitudes d’exercice et améliorer le moral, et pourtant de nombreux gymnases et terrains affichent encore une faible fréquentation et une participation tiède. Cette étude montre comment des données provenant de dispositifs portables, de caméras de classe et de courts retours écrits peuvent être combinées pour estimer automatiquement le degré d’engagement réel des étudiants pendant les cours d’éducation physique, offrant aux enseignants un aperçu plus rapide et plus objectif que les listes de contrôle traditionnelles ou les enquêtes de fin de semestre.
Transformer les cours de sport en flux de données riches
Dans les cours d’éducation physique modernes, les étudiants portent souvent des appareils qui suivent la fréquence cardiaque, les pas et les mouvements, tandis que des caméras captent les activités de groupe et que des plateformes en ligne recueillent de courts messages et commentaires. Les chercheurs exploitent un vaste jeu de données national qui rassemble ces flux pour 1 000 étudiants universitaires sur des milliers d’heures de cours. Chaque tranche de dix minutes de cours est annotée par des experts formés comme présentant une participation faible, moyenne ou élevée, en fonction des mouvements des étudiants, de l’effort fourni par le corps et de ce qu’ils disent sur la séance. Ces tranches étiquetées servent de terrain d’entraînement pour un modèle informatique qui apprend à lire l’engagement à partir de données brutes plutôt qu’à partir d’impressions éparses.
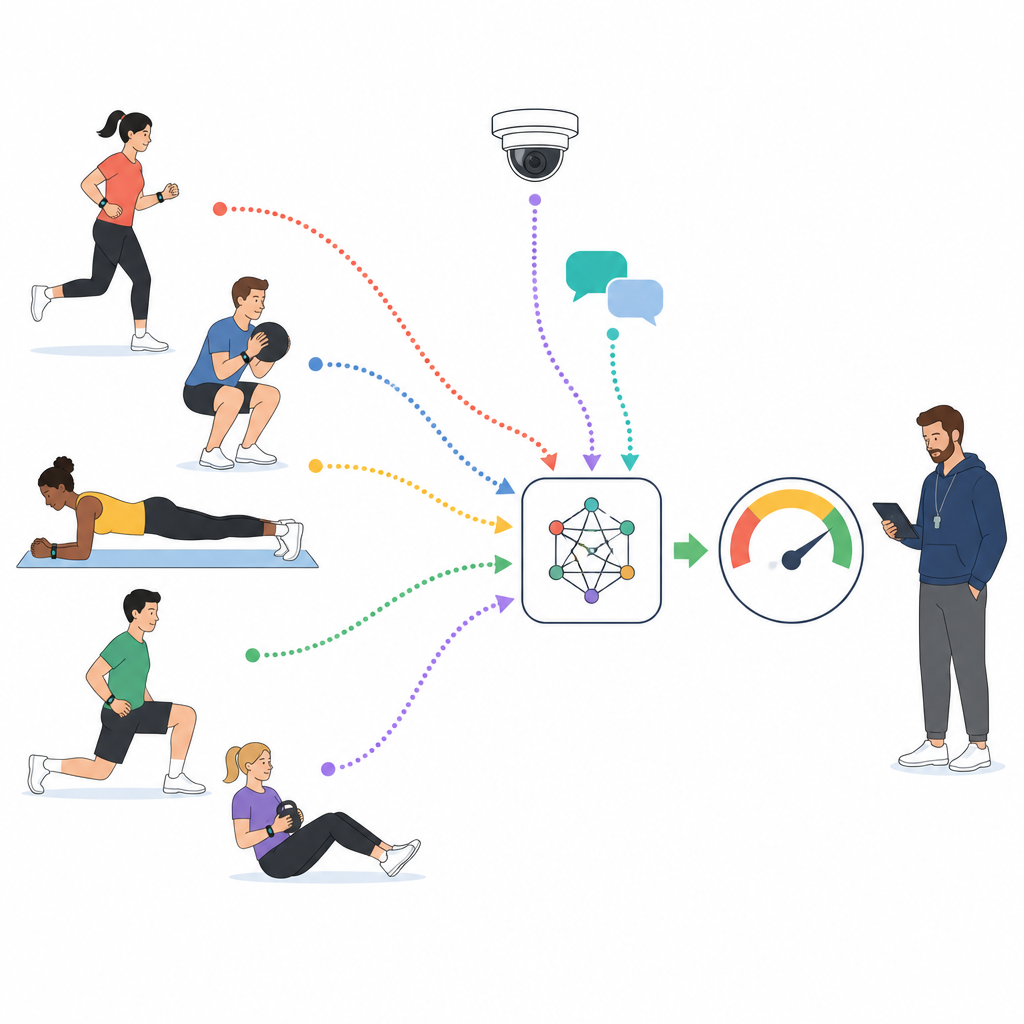
Apprendre au modèle à lire le corps, le visage et les mots
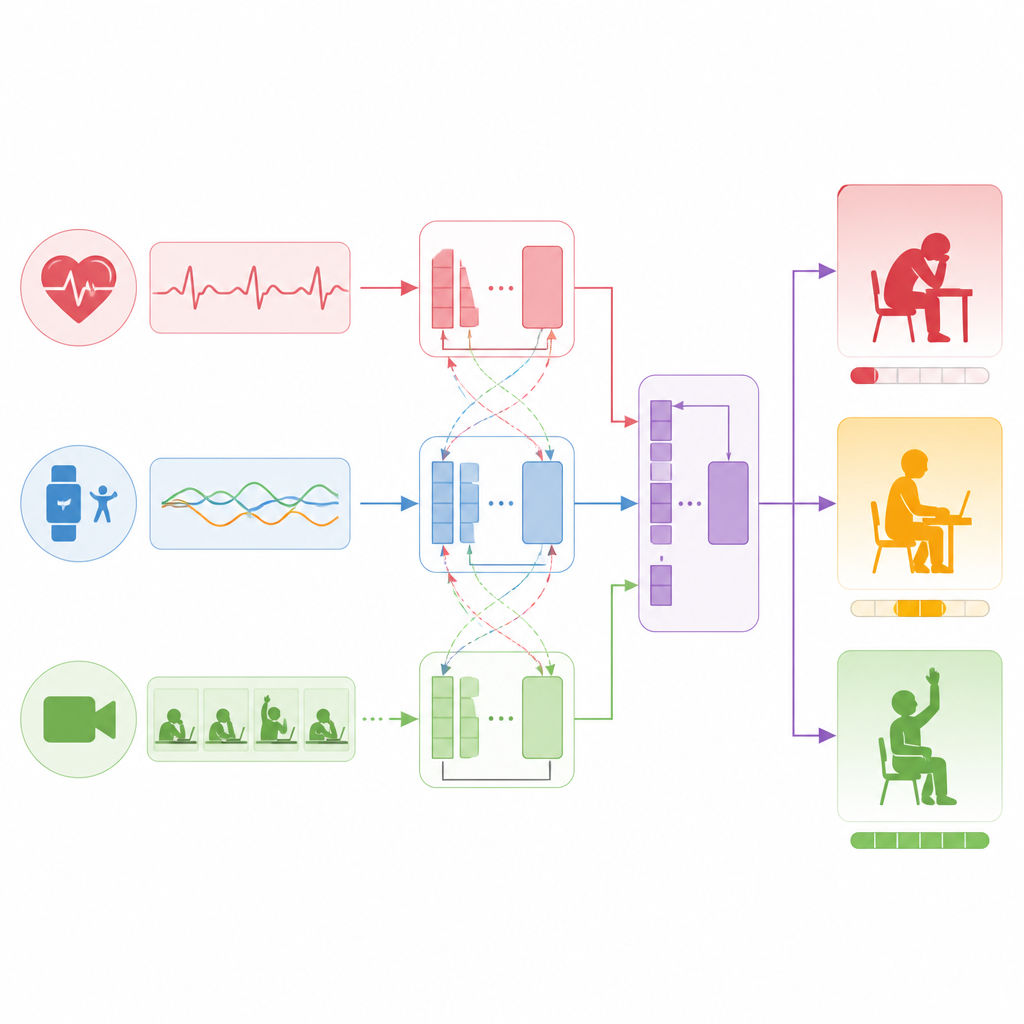
Plutôt que de s’appuyer sur une seule source d’information, l’étude construit un modèle en couches qui traite les capteurs, le texte et la vidéo comme des partenaires égaux. Pour les signaux de capteurs tels que la fréquence cardiaque et l’accélération, un réseau de traitement de séquences apprend à repérer des motifs comme un effort soutenu ou des pics répétés d’activité. Pour les commentaires et courtes réflexions des étudiants, un modèle de langage distille des phrases entières en représentations compactes qui codent l’attitude et le ton. Pour les clips vidéo, un autre réseau découpe chaque image en patchs et apprend comment les expressions faciales, la posture corporelle et les schémas de mouvement se déroulent dans le temps. Les trois flux sont ensuite traduits dans un espace numérique partagé afin que le modèle puisse les comparer et les combiner efficacement.
Comment le modèle relie les signaux à l’engagement
Le cœur de l’approche est une technique qui permet aux différents flux de données de prêter attention les uns aux autres. D’abord, le modèle renforce chaque flux individuellement, apprenant des structures internes comme les tendances de la fréquence cardiaque ou les moments clés d’une vidéo. Ensuite, il met en relation les flux, posant des questions telles que quelles périodes du signal capteur correspondent à des mentions écrites de fatigue, ou quels segments vidéo s’alignent avec un langage suggérant de l’enthousiasme. En apprenant ces liens croisés, le système construit une image fusionnée de ce qui se passe avec chaque étudiant pendant une fenêtre de dix minutes. Enfin, cette image combinée alimente une couche de sortie simple qui produit à la fois un score d’engagement continu et une catégorie à trois niveaux.
Quelle est l’efficacité du système en pratique
Lorsque les chercheurs comparent leur modèle multimodal à une série de méthodes existantes n’utilisant que des capteurs, uniquement la vidéo ou seulement deux types de données, ils constatent des gains nets. Le nouveau système réduit l’erreur de prédiction de plus d’un cinquième par rapport à une référence solide basée uniquement sur les capteurs et atteint plus de 90 % de précision dans la classification des niveaux d’engagement. Fait important, il le fait assez rapidement pour être utile pendant les cours, nécessitant environ deux dixièmes de seconde pour traiter dix minutes de données pour un étudiant. Des tests retirant un type de données à la fois montrent que les trois sources sont utiles, la vidéo contribuant le plus, suivie du texte puis des capteurs. Une analyse supplémentaire des schémas d’attention internes du modèle suggère qu’il se concentre sur des indices sensés, tels que l’association d’une hausse de la fréquence cardiaque avec un mouvement actif puis une fatigue ultérieure.
Ce que cela pourrait signifier pour les futurs cours de sport
Les auteurs concluent qu’un système multimodal soigneusement conçu peut fournir des images opportunes et assez précises de l’implication des étudiants en éducation physique, faisant évoluer l’évaluation des impressions approximatives vers une vision continue et fondée sur les données. Bien que l’approche dépende de caméras et de dispositifs portables et soulève des questions de confidentialité et d’équité, elle ouvre la voie à un avenir où les enseignants reçoivent des retours en temps réel sur les moments où les étudiants sont concentrés, enthousiastes ou distraits, et peuvent ajuster les activités sur le moment plutôt que d’attendre les enquêtes de fin de semestre.
Citation: Li, J. Predictive analysis of student engagement in university physical education courses based on a multimodal transformer algorithm. Sci Rep 16, 15123 (2026). https://doi.org/10.1038/s41598-026-45928-w
Mots-clés: engagement des étudiants, éducation physique, apprentissage multimodal, modèle transformeur, capteurs portables