Clear Sky Science · sv
Jämförande bedömning av maskininlärningsmodeller för prediktion av viskositet i polymerkemilösningar vid förbättrad oljeutvinning
Varför det spelar roll att förutsäga vätskors tjocklek i oljefält
Att få ut de sista dropparna olja ur ett åldrande fält är överraskande komplicerat. Ingenjörer gör ofta injicerat vatten tjockare med speciella polymerer så att det trycker oljan jämnare istället för att ”fingerbilda” genom den och lämna kvar värdefullt bränsle. Men att ställa in hur “tjock” dessa polymerlösningar bör vara kräver vanligtvis hundratals laboratorietester under olika temperaturer, salthalter, flödeshastigheter och kemiska doser. Denna studie visar hur modern maskininlärning kan lära från dessa experiment och sedan omedelbart förutsäga polymerens tjocklek (viskositet), vilket hjälper till att utforma mer effektiva och mindre riskfyllda oljeåtervinningsprojekt.
Hur tjocka vätskor hjälper till att flytta svåråtkomlig olja
När ett reservoar först tappas ut flyter oljan relativt lätt. Med tiden blir det som återstår instängt i bergporerna och rör sig dåligt vid normalt vattenflöde. Om det injicerade vattnet är för tunt i förhållande till oljan så slingrar det sig genom de lättaste banorna och kringgår stora delar av den kvarvarande råoljan. Tillsats av polymerer gör det injicerade vattnet tjockare, vilket gör att det kan trycka jämnare, förbättra genomströmningen av berget och öka total återvinning. Problemet är att polymerers beteende är mycket känsligt för förhållanden: högre koncentration ökar generellt viskositeten, högre temperatur och kraftigare skjuvning (snabbare flöde) brukar tunna ut den, och lösta salter kan antingen försvaga eller omforma polymerkedjorna. Eftersom dessa faktorer interagerar på komplexa, icke‑linjära sätt misslyckas enkla formler ofta.
Att bygga en rik datamängd från laboratorieexperiment
Författarna fokuserade på en allmänt använd polymer (SAV10, en typ av HPAM) och skapade 1 079 mätningar av dess viskositet under realistiska olje‑fältsförhållanden. De varierade fyra huvudingredienser: polymerkoncentration (från 1 000 till 4 000 delar per miljon), temperatur (25–80 °C), saltinnehåll som efterliknar arabisk havsvatten och dess utspädningar, samt flödeshastighet uttryckt som skjuvhastighet. Som väntat uppträdde tjockare lösningar vid låg temperatur, låg salthalt, hög koncentration och lugnt flöde; alla prover visade ”skjuv‑tunnande” beteende och blev mindre viskösa när de rördes om eller pumpades snabbare. Innan modellering rensade teamet och standardiserade data, kontrollerade avvikare och undersökte korrelationer. Koncentrationen visade starkast positiv koppling till viskositet, medan temperatur, skjuvning och salthalt tenderade att minska den, men inte i en enkel rak linje.
Att testa många inlärningsmetoder
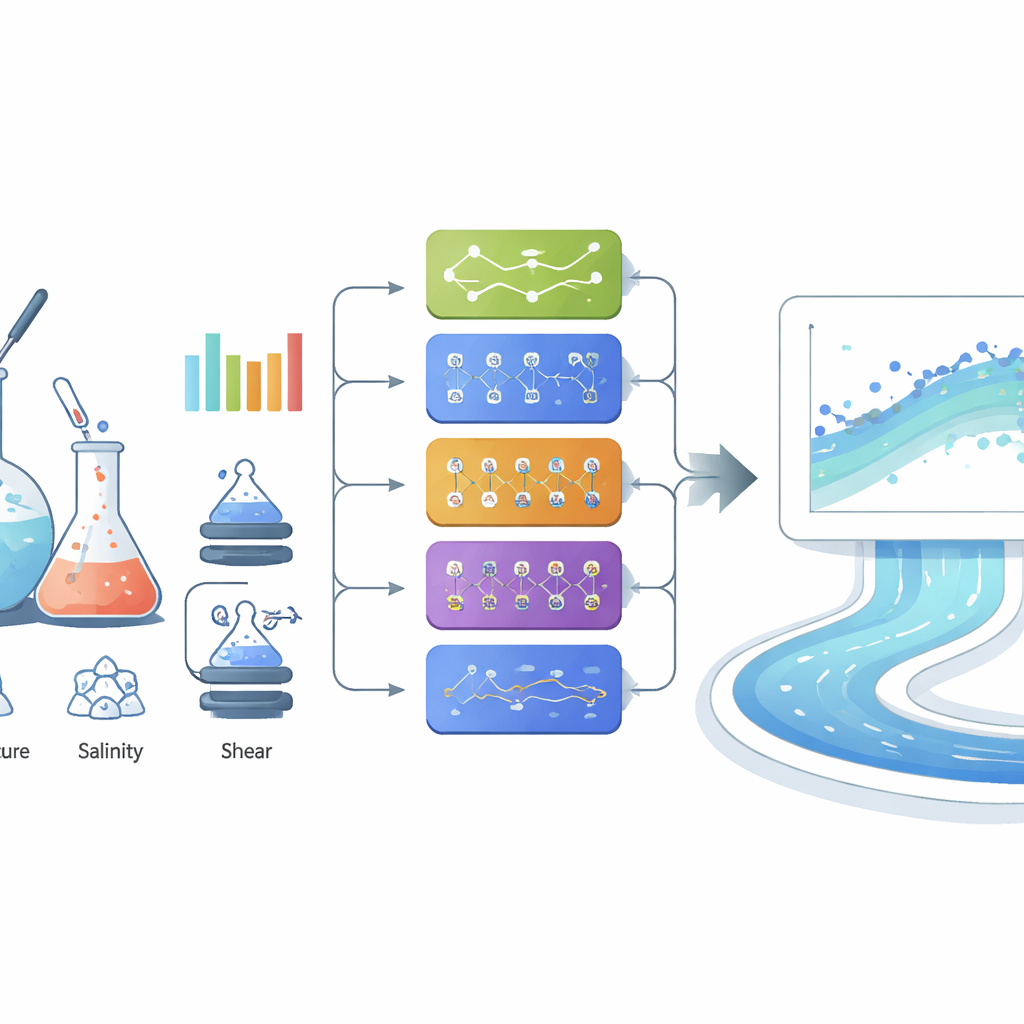
Forskarna betraktade därefter viskositetsprognosen som en datadriven uppgift och jämförde systematiskt olika maskininlärningsmetoder. De började med välkända verktyg — linjär regression, supportvektormaskiner, beslutsträd och flera neurala nätverk — och fann att mer flexibla modeller klarade sig långt bättre än enkla linjära passningar. Ett ”brett” neuralt nätverk med ett dolt lager om 100 neuroner förutsade redan viskositeter med utmärkt noggrannhet och matchade mätta värden väl över hela intervallet. Därefter utvärderade de en uppsättning mer avancerade metoder kända som ensemblemodeller, vilka kombinerar styrkorna hos många beslutsträd eller boostade inlärande metoder, tillsammans med Gaussisk processregression, en probabilistisk metod som också ger osäkerhetsuppskattningar. Flera av dessa avancerade modeller presterade mycket bra, med mycket små prognosfel även vid höga viskositeter där många traditionella tillvägagångssätt fallerar.
Varför staplade modeller gav de skarpaste prognoserna
För att klämma ut den sista noggrannheten byggde teamet en ”stacking”‑ensemble som blandade tre av de bästa individuella modellerna (Extra Trees, XGBoost och CatBoost) genom en enkel meta‑modell ovanpå. Varje basmodell lärde sig något olika aspekter av hur koncentration, skjuvning, temperatur och salthalt påverkar viskositet; meta‑modellen lärde sig sedan hur deras utsignaler ska viktas. Detta staplade system gav den starkaste prestationen av alla, med en nästan perfekt överensstämmelse mellan predicerade och uppmätta viskositeter och mycket låg genomsnittlig felmarginal, även för de mest viskösa fallen som är viktigast för fältdesign. Förklarande AI‑verktyg, såsom permutation importance och SHAP‑analys, bekräftade att polymerkoncentration är den dominerande faktorn, följd av skjuvhastighet, temperatur och salthalt — en ordning som överensstämmer med grundläggande polyerfysik.
Vad detta innebär för framtida utformning av oljeåtervinning
För en lekmannaläsare är slutsatsen att studien förvandlar en långsam, prövande laboratorieprocess till en snabb, datadriven förutsägelsemaskin. När det staplade modellen väl är tränad kan den omedelbart uppskatta hur tjock en polymerlösning blir under nya kombinationer av salt, värme, flöde och koncentration, utan att varje gång behöva köra nya experiment. Det kan snabba upp genomgång av återvinningsalternativ, sänka kostnader och minska osäkerhet vid planering av polymerinjektionsprojekt. Medan det aktuella arbetet bygger på en specifik polymer och laboratoriedata i liten skala, kan samma angreppssätt utvidgas till andra kemier och tillsatser, och i slutändan hjälpa ingenjörer att skräddarsy smarta vätskor för tuffare reservoarer — med mindre gissande och mer lärda mönster från data.
Citering: Belkhir, S.A., Pakeer, A.A., Shakeel, M. et al. Comparative assessment of machine learning models for polymer solution viscosity prediction in enhanced oil recovery. Sci Rep 16, 10442 (2026). https://doi.org/10.1038/s41598-026-41045-w
Nyckelord: polymerinjektion, viskositetsprognos, maskininlärning, förbättrad oljeåtervinning, ensemblemodeller