Clear Sky Science · it
Valutazione comparativa di modelli di machine learning per la previsione della viscosità di soluzioni polimeriche nel recupero migliorato del petrolio
Perché è importante prevedere la “densità” dei fluidi nei giacimenti
Estrarre le ultime gocce da un giacimento invecchiato è sorprendentemente complesso. Gli ingegneri spesso addensano l’acqua iniettata con polimeri speciali in modo che spinga il petrolio in modo uniforme invece di frastagliarlo attraverso percorsi preferenziali, lasciando combustibile prezioso indietro. Ma regolare quanto «densa» debba essere una soluzione polimerica richiede solitamente centinaia di test di laboratorio a diverse temperature, concentrazioni saline, velocità di flusso e dosaggi chimici. Questo studio mostra come il machine learning moderno possa apprendere da quegli esperimenti e predire istantaneamente la viscosità delle soluzioni polimeriche, aiutando a progettare operazioni di recupero più efficienti e a rischio minore.
Come fluidi più densi aiutano a muovere il petrolio ostinato
All’inizio della produzione un giacimento lascia fluire il petrolio relativamente facilmente. Col tempo, il petrolio rimanente resta intrappolato nelle porosità della roccia e non si muove bene con il semplice flooding idrico. Se l’acqua iniettata è troppo «sottile» rispetto al petrololio, essa scorre attraverso i percorsi più facili, bypassando gran parte del greggio residuo. L’aggiunta di polimeri rende l’acqua iniettata più viscosa, permettendo una spinta più uniforme, migliorando la ragione di sweep del giacimento e aumentando il recupero totale. Il problema è che il comportamento dei polimeri è molto sensibile alle condizioni: una maggiore concentrazione di solito aumenta la viscosità, temperature più alte e forze di taglio più intense (flussi più veloci) tendono a diminuirla, e i sali disciolti possono indebolire o riorganizzare le catene polimeriche. Poiché questi fattori interagiscono in modi complessi e non lineari, le formule semplici spesso falliscono.
Costruire un dataset ricco da esperimenti di laboratorio
Gli autori si sono concentrati su un polimero ampiamente usato (SAV10, un tipo di HPAM) e hanno raccolto 1.079 misure della sua viscosità in condizioni realistiche di giacimento. Hanno variato quattro ingredienti principali: concentrazione di polimero (da 1.000 a 4.000 parti per milione), temperatura (25–80 °C), contenuto salino che imita l’acqua di mare araba e le sue diluizioni, e la velocità di flusso, espressa come tasso di taglio. Come prevedibile, soluzioni più viscose si osservavano a bassa temperatura, bassa salinità, alta concentrazione e flusso delicato; tutti i campioni hanno mostrato comportamento di «shear‑thinning», diventando meno viscosi quando agitati o pompati più velocemente. Prima della modellazione il team ha pulito e standardizzato i dati, verificato la presenza di outlier ed esaminato le correlazioni. La concentrazione ha mostrato il legame positivo più forte con la viscosità, mentre temperatura, taglio e salinità tendevano a ridurla, ma non in modo lineare semplice.
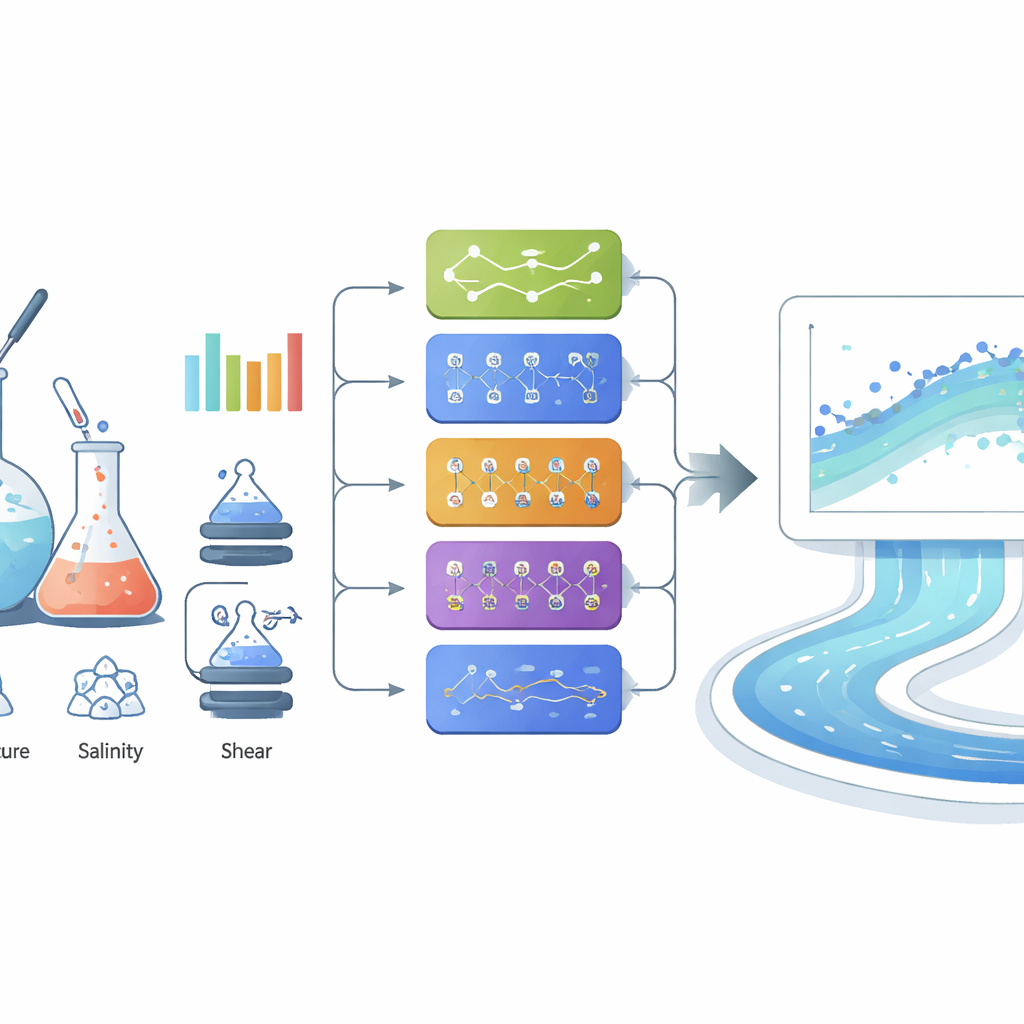
Mettere alla prova molti metodi di apprendimento
I ricercatori hanno quindi trattato la previsione della viscosità come un compito guidato dai dati e hanno confrontato sistematicamente diversi metodi di machine learning. Hanno iniziato con strumenti noti—regressione lineare, macchine a vettori di supporto, alberi decisionali e diverse reti neurali—e hanno scoperto che i modelli più flessibili performavano molto meglio dei semplici adattamenti lineari. Una rete neurale «ampia» con un singolo strato nascosto di 100 neuroni già prediceva le viscosità con ottima accuratezza, corrispondendo da vicino ai valori misurati su tutto l’intervallo. Successivamente hanno valutato una serie di metodi più avanzati noti come modelli ensemble, che combinano i punti di forza di molti alberi decisionali o learner potenziati, insieme alla regressione a processo gaussiano, un metodo probabilistico che fornisce anche stime di incertezza. Diversi di questi modelli avanzati hanno dato risultati eccellenti, con errori di previsione molto piccoli anche alle alte viscosità, dove molti approcci tradizionali falliscono.
Perché lo stacking ha dato le previsioni più affilate
Per ottenere l’ultima parte di accuratezza, il team ha costruito un ensemble di tipo «stacking» che fonde tre dei migliori modelli individuali (Extra Trees, XGBoost e CatBoost) usando un semplice meta‑modello sovrastante. Ogni modello base ha appreso aspetti leggermente diversi di come concentrazione, taglio, temperatura e salinità influenzano la viscosità; il meta‑modello ha poi imparato a pesare i loro output. Questo sistema impilato ha fornito le prestazioni migliori in assoluto, con un’accoppiata quasi perfetta tra viscosità previste e misurate e un errore medio molto basso, inclusi i casi più viscosi che sono i più importanti per la progettazione di campo. Strumenti di Explainable‑AI, come l’importanza per permutazione e l’analisi SHAP, hanno confermato che la concentrazione del polimero è il fattore dominante, seguita dal tasso di taglio, dalla temperatura e dalla salinità—un ordine che concorda con la fisica fondamentale dei polimeri.
Cosa significa per la progettazione futura del recupero del petrolio
Per il lettore non specialista, il punto essenziale è che lo studio trasforma un processo di laboratorio lento e di tentativi in un motore di previsione veloce e basato sui dati. Una volta addestrato, il modello impilato può stimare istantaneamente quanto sarà viscosa una soluzione polimerica sotto nuove combinazioni di salinità, temperatura, flusso e concentrazione, senza eseguire ogni volta nuovi esperimenti. Questo può accelerare il confronto delle opzioni di recupero, ridurre i costi e diminuire l’incertezza nella pianificazione di progetti di polymer flooding. Pur essendo il lavoro attuale basato su un polimero specifico e su dati a scala di laboratorio, lo stesso approccio potrebbe essere esteso ad altre chimiche e additivi, aiutando infine gli ingegneri a progettare fluidi mirati per giacimenti più difficili, facendo meno affidamento sul tentativo e più sull’apprendimento dai dati.
Citazione: Belkhir, S.A., Pakeer, A.A., Shakeel, M. et al. Comparative assessment of machine learning models for polymer solution viscosity prediction in enhanced oil recovery. Sci Rep 16, 10442 (2026). https://doi.org/10.1038/s41598-026-41045-w
Parole chiave: iniezione di polimeri, previsione della viscosità, machine learning, recupero migliorato del petrolio, modelli ensemble