Clear Sky Science · de
Vergleichende Bewertung von Machine‑Learning‑Modellen zur Vorhersage der Viskosität von Polymerlösungen bei der verstärkten Ölrückgewinnung
Warum die Vorhersage der Fließdicke in Ölfeldern wichtig ist
Das Herausholen der letzten Tropfen Öl aus einem alternden Feld ist überraschend kompliziert. Ingenieure verdicken das injizierte Wasser häufig mit speziellen Polymeren, damit es das Öl gleichmäßig verdrängt, statt sich in Fingern zu verhalten und wertvolles Rohöl zurückzulassen. Die richtige Abstimmung der „Dicke“ dieser Polymerlösungen erfordert jedoch meist Hunderte von Labortests unter verschiedenen Temperaturen, Salzgehalten, Strömungsraten und Chemikaliendosen. Diese Studie zeigt, wie moderne Machine‑Learning‑Methoden aus diesen Experimenten lernen und dann sofort die Polymer‑Viskosität vorhersagen können, was die Planung effizienterer und risikoärmerer Ölrückgewinnungsprojekte unterstützt.
Wie dicke Flüssigkeiten hartnäckiges Öl mobilisieren
Zu Beginn der Förderung fließt Öl relativ leicht. Mit der Zeit bleibt Öl zurück, das in Gesteinsporen eingeschlossen ist und sich bei normaler Wasserflutung kaum bewegt. Ist das injizierte Wasser gegenüber dem Öl zu dünn, durchzieht es die leichtesten Wege und umgeht große Teile des verbleibenden Öls. Durch Zugabe von Polymeren lässt sich das injizierte Wasser verdicken, sodass es gleichmäßiger verdrängt, die Durchspülung des Gesteins verbessert und die Gesamtgewinnung erhöht. Problematisch ist, dass sich das Verhalten der Polymere stark an die Bedingungen anpasst: Höhere Konzentration macht die Lösung in der Regel dicker, höhere Temperatur und stärkere Scherung (schnellere Strömung) dünnen sie normalerweise aus, und gelöste Salze können die Polymerketten entweder schwächen oder umformen. Weil diese Faktoren auf komplexe, nichtlineare Weise interagieren, versagen einfache Formeln oft.
Aufbau eines umfangreichen Datensatzes aus Laborversuchen
Die Autoren konzentrierten sich auf ein weit verbreitetes Polymer (SAV10, eine Form von HPAM) und erstellten 1.079 Messungen seiner Viskosität unter realistischen Ölfeldbedingungen. Sie variierten vier Haupteinflussgrößen: Polymerkonzentration (von 1.000 bis 4.000 Teilen pro Million), Temperatur (25–80 °C), Salzgehalt, der arabisches Meerwasser und dessen Verdünnungen nachbildet, und die Strömungsrate, ausgedrückt als Scherrate. Wie zu erwarten, traten dickere Lösungen bei niedriger Temperatur, geringer Salzkonzentration, hoher Konzentration und sanfter Strömung auf; alle Proben zeigten ein Scherverdünnungsverhalten und wurden weniger viskos, wenn sie schneller gerührt oder gepumpt wurden. Vor der Modellierung bereinigte und standardisierte das Team die Daten, prüfte Ausreißer und untersuchte Korrelationen. Die Konzentration zeigte den stärksten positiven Zusammenhang mit der Viskosität, während Temperatur, Scherung und Salzgehalt tendenziell eine Verringerung bewirkten, jedoch nicht in linearer Weise.
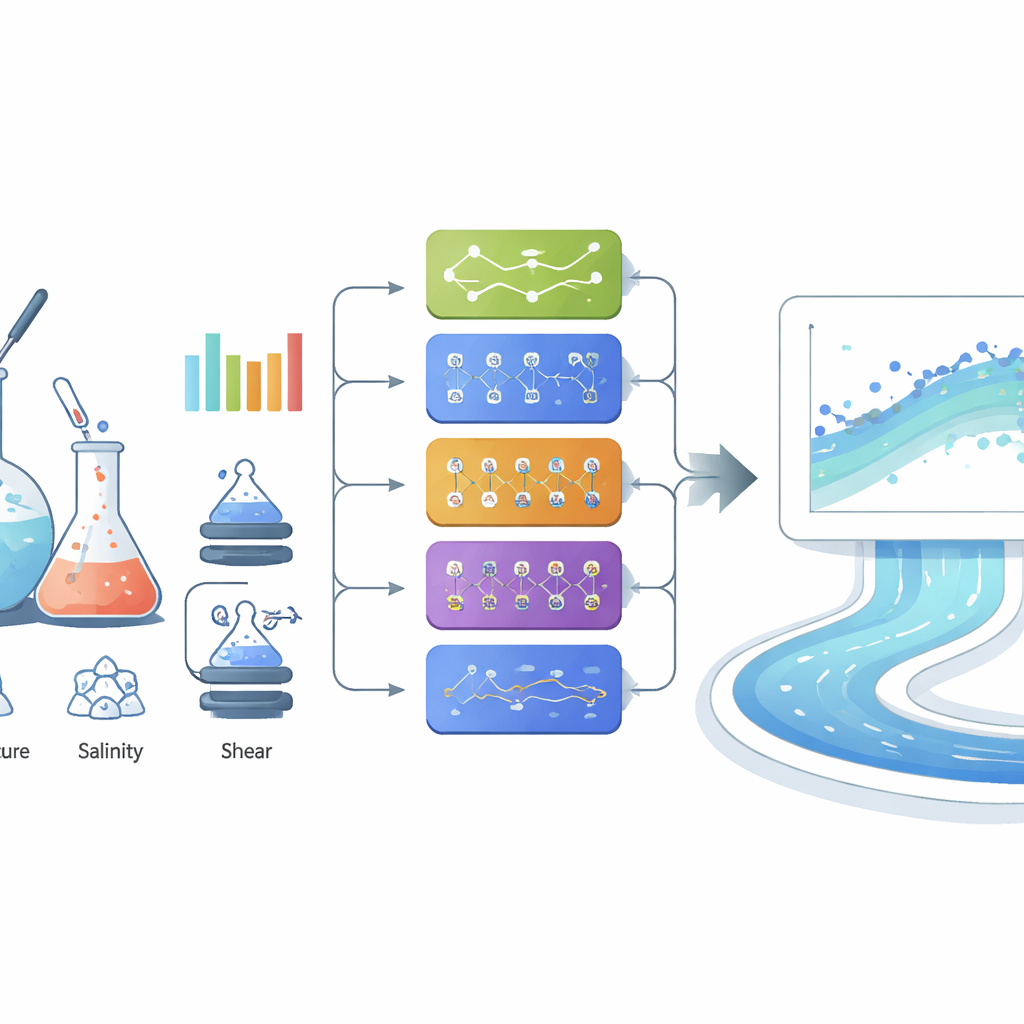
Viele Lernverfahren im Vergleich
Die Forschenden behandelten die Viskositätsvorhersage als datengetriebene Aufgabe und verglichen systematisch verschiedene Machine‑Learning‑Methoden. Sie begannen mit vertrauten Werkzeugen — linearer Regression, Support‑Vector‑Machines, Entscheidungsbäumen und mehreren neuronalen Netzen — und fanden heraus, dass flexiblere Modelle deutlich bessere Ergebnisse lieferten als einfache lineare Anpassungen. Ein „breites“ neuronales Netz mit einer einzigen versteckten Schicht von 100 Neuronen sagte die Viskositäten bereits mit ausgezeichneter Genauigkeit voraus und stimmte über den gesamten Bereich eng mit den Messwerten überein. Anschließend bewerteten sie eine Reihe fortgeschrittener Methoden, so genannte Ensemble‑Modelle, die die Stärken vieler Entscheidungsbäume oder gebooteter Lerner kombinieren, sowie die Gauß‑Prozess‑Regression, eine probabilistische Methode, die zusätzlich Unsicherheitsabschätzungen liefert. Einige dieser fortgeschrittenen Modelle lieferten sehr gute Ergebnisse mit sehr kleinen Vorhersagefehlern, selbst bei hohen Viskositäten, wo viele traditionelle Ansätze versagen.
Warum gestapelte Modelle die treffendsten Vorhersagen lieferten
Um die letzte Genauigkeit herauszuholen, bauten die Forscher ein „Stacking“‑Ensemble auf, das drei der besten Einzelmodelle (Extra Trees, XGBoost und CatBoost) mit einem einfachen Meta‑Modell darüber kombiniert. Jedes Basismodell lernte leicht unterschiedliche Aspekte, wie Konzentration, Scherung, Temperatur und Salzgehalt die Viskosität beeinflussen; das Meta‑Modell erlernte anschließend, wie ihre Ausgaben zu gewichten sind. Dieses gestackte System brachte die beste Leistung und zeigte eine nahezu perfekte Übereinstimmung zwischen vorhergesagten und gemessenen Viskositäten sowie sehr niedrige durchschnittliche Fehler, auch für die zähflüssigsten Fälle, die für die Feldplanung am wichtigsten sind. Explainable‑AI‑Werkzeuge wie Permutations‑Wichtigkeit und SHAP‑Analysen bestätigten, dass die Polymerkonzentration die dominierende Steuergröße ist, gefolgt von Scherrate, Temperatur und Salzgehalt — eine Reihenfolge, die mit den grundlegenden Prinzipien der Polymerphysik übereinstimmt.
Was das für die künftige Planung der Ölrückgewinnung bedeutet
Für den Laien lautet die Kernbotschaft: Die Studie verwandelt einen langsamen, trial‑and‑error‑Laborprozess in eine schnelle, datengetriebene Vorhersagemaschine. Einmal trainiert, kann das gestackte Modell sofort abschätzen, wie dick eine Polymerlösung bei neuen Kombinationen von Salz, Temperatur, Strömung und Konzentration sein wird, ohne für jeden Fall neue Experimente durchführen zu müssen. Das beschleunigt das Screening von Förderoptionen, senkt Kosten und reduziert Unsicherheiten bei der Planung von Polymer‑Flooding‑Projekten. Obwohl die vorliegende Arbeit auf einem spezifischen Polymer und Labordaten basiert, könnte derselbe Ansatz auf andere Chemien und Zusatzstoffe ausgeweitet werden und Ingenieure letztlich dabei unterstützen, maßgeschneiderte intelligente Flüssigkeiten für anspruchsvollere Lagerstätten zu entwickeln — weniger basierend auf Vermutungen, mehr auf erlernten Mustern in den Daten.
Zitation: Belkhir, S.A., Pakeer, A.A., Shakeel, M. et al. Comparative assessment of machine learning models for polymer solution viscosity prediction in enhanced oil recovery. Sci Rep 16, 10442 (2026). https://doi.org/10.1038/s41598-026-41045-w
Schlüsselwörter: Polymer‑Flooding, Viskositätsvorhersage, Machine Learning, verstärkte Ölrückgewinnung, Ensemble‑Modelle