Clear Sky Science · es
Evaluación comparativa de modelos de aprendizaje automático para la predicción de la viscosidad de soluciones poliméricas en recuperación mejorada de petróleo
Por qué importa predecir la «espesor» de los fluidos en yacimientos petrolíferos
Extraer las últimas gotas de petróleo de un yacimiento envejecido resulta sorprendentemente difícil. Los ingenieros suelen espesar el agua inyectada con polímeros especiales para que empuje el petróleo de forma uniforme en lugar de «buscar» los caminos más fáciles y dejar combustible valioso atrás. Pero ajustar cuán “espesas” deben ser estas soluciones poliméricas normalmente exige cientos de ensayos de laboratorio bajo distintas temperaturas, niveles de salinidad, velocidades de flujo y dosis químicas. Este estudio muestra cómo el aprendizaje automático moderno puede aprender de esos experimentos y predecir al instante la viscosidad de los polímeros, ayudando a diseñar proyectos de recuperación de petróleo más eficientes y con menos riesgo.
Cómo los fluidos más viscosos ayudan a mover el petróleo resistente
Cuando se explota un yacimiento por primera vez, el petróleo fluye con relativa facilidad. Con el tiempo, lo que queda queda atrapado en los poros de la roca y no se mueve bien con el riego convencional. Si el agua inyectada es demasiado delgada en comparación con el petróleo, atraviesa los caminos más fáciles y evita gran parte del crudo remanente. Añadir polímeros espesa el agua inyectada, permitiéndole empujar de forma más uniforme, mejorar la barrida de la roca y aumentar la recuperación total. La pega es que el comportamiento del polímero es muy sensible a las condiciones: una mayor concentración generalmente aumenta la viscosidad, temperaturas más altas y esfuerzos cortantes más fuertes (flujo más rápido) suelen reducirla, y las sales disueltas pueden debilitar o modificar las cadenas poliméricas. Como estos factores interactúan de formas complejas y no lineales, las fórmulas simples a menudo fallan.
Construyendo un conjunto de datos rico a partir de experimentos de laboratorio
Los autores se centraron en un polímero de uso extendido (SAV10, un tipo de HPAM) y generaron 1.079 mediciones de su viscosidad bajo condiciones realistas de yacimiento. Variaron cuatro ingredientes principales: concentración de polímero (de 1.000 a 4.000 partes por millón), temperatura (25–80 °C), contenido salino que imita el agua de mar del Golfo Arábigo y sus diluciones, y tasa de flujo expresada como velocidad de corte. Como era de esperar, las soluciones más viscosas aparecieron a baja temperatura, baja salinidad, alta concentración y flujo suave; todas las muestras mostraron comportamiento de «shear‑thinning», volviéndose menos viscosas al agitarse o bombearse más rápido. Antes del modelado, el equipo limpió y estandarizó los datos, comprobó valores atípicos y examinó correlaciones. La concentración mostró la relación positiva más fuerte con la viscosidad, mientras que temperatura, corte y salinidad tendieron a reducirla, pero no de forma lineal simple.
Poniendo a prueba muchos métodos de aprendizaje
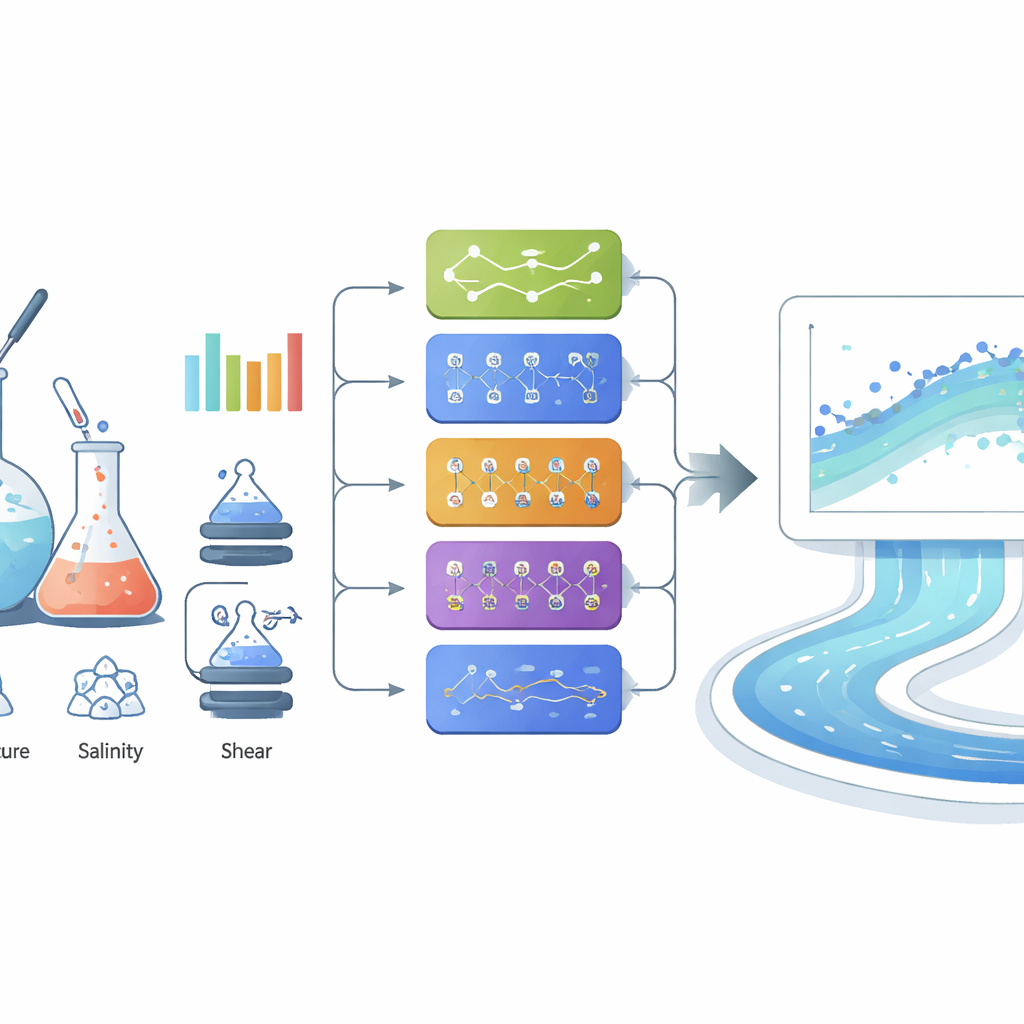
Los investigadores trataron la predicción de la viscosidad como una tarea guiada por datos y compararon sistemáticamente distintos métodos de aprendizaje automático. Empezaron con herramientas familiares —regresión lineal, máquinas de vectores de soporte, árboles de decisión y varias redes neuronales— y comprobaron que los modelos más flexibles superaban con creces a los ajustes lineales simples. Una red neuronal “ancha” con una sola capa oculta de 100 neuronas ya predijo viscosidades con excelente precisión, coincidiendo estrechamente con los valores medidos en todo el rango. A continuación evaluaron un conjunto de métodos más avanzados conocidos como modelos ensemble, que combinan las fortalezas de muchos árboles de decisión o aprendices potenciados, junto con la regresión por procesos Gaussianos, un método probabilístico que además aporta estimaciones de incertidumbre. Varios de estos modelos avanzados funcionaron extremadamente bien, con errores de predicción muy reducidos incluso a viscosidades altas, donde muchos enfoques tradicionales fallan.
Por qué apilar modelos dio las predicciones más precisas
Para extraer el último punto de precisión, el equipo construyó un ensemble por “stacking” que mezcla tres de los mejores modelos individuales (Extra Trees, XGBoost y CatBoost) usando un meta‑modelo sencillo encima. Cada modelo base aprendió aspectos ligeramente distintos de cómo la concentración, el corte, la temperatura y la salinidad influyen en la viscosidad; el meta‑modelo aprendió entonces a ponderar sus salidas. Este sistema apilado ofreció el mejor rendimiento de todos, con una coincidencia casi perfecta entre viscosidades predichas y medidas y un error medio muy bajo, incluso en los casos más viscosos que son los más relevantes para el diseño en campo. Herramientas de IA explicable, como la importancia por permutación y el análisis SHAP, confirmaron que la concentración de polímero es el factor dominante, seguido por la tasa de corte, la temperatura y la salinidad —un orden que concuerda con la física básica de los polímeros.
Qué significa esto para el diseño futuro de recuperación de petróleo
Para un lector no especializado, la conclusión es que el estudio transforma un proceso de laboratorio lento y por prueba y error en un motor de predicción rápido y basado en datos. Una vez entrenado, el modelo apilado puede estimar al instante cuán viscosa será una solución polimérica bajo nuevas combinaciones de sal, temperatura, flujo y concentración, sin necesidad de realizar nuevos experimentos cada vez. Eso puede acelerar la evaluación de opciones de recuperación, reducir costes y disminuir la incertidumbre al planificar proyectos de inundación con polímeros. Aunque el trabajo actual se basa en un polímero específico y datos a escala de laboratorio, el mismo enfoque podría extenderse a otras químicas y aditivos, ayudando a los ingenieros a diseñar fluidos inteligentes para yacimientos más difíciles, apoyándose menos en conjeturas y más en patrones aprendidos de los datos.
Cita: Belkhir, S.A., Pakeer, A.A., Shakeel, M. et al. Comparative assessment of machine learning models for polymer solution viscosity prediction in enhanced oil recovery. Sci Rep 16, 10442 (2026). https://doi.org/10.1038/s41598-026-41045-w
Palabras clave: inundación con polímeros, predicción de viscosidad, aprendizaje automático, recuperación mejorada de petróleo, modelos ensemble