Clear Sky Science · fr
Évaluation comparative de modèles d’apprentissage automatique pour la prédiction de la viscosité des solutions de polymère en récupération assistée du pétrole
Pourquoi il est important de prévoir l’épaisseur des fluides dans les gisements pétroliers
Extraire les dernières gouttes d’un gisement vieillissant est étonnamment complexe. Les ingénieurs épaississent souvent l’eau injectée avec des polymères spécifiques afin qu’elle pousse le pétrole de manière homogène au lieu de former des doigts et de laisser du carburant précieux derrière elle. Mais régler la « viscosité » de ces solutions de polymère exige généralement des centaines de tests en laboratoire sous différentes températures, teneurs en sel, débits et doses chimiques. Cette étude montre comment l’apprentissage automatique moderne peut apprendre de ces expériences puis prédire instantanément la viscosité des polymères, aidant à concevoir des projets de récupération du pétrole plus efficaces et moins risqués.
Comment des fluides plus épais aident à déplacer le pétrole récalcitrant
Lorsqu’un réservoir est d’abord exploité, le pétrole s’écoule relativement facilement. Avec le temps, ce qui reste est piégé dans les pores de la roche et ne se déplace plus correctement avec une simple inondation d’eau. Si l’eau injectée est trop fluide par rapport au pétrole, elle contourne les zones les plus résistantes en empruntant les chemins les plus faciles, laissant une grande partie du brut derrière elle. Ajouter des polymères rend l’eau injectée plus visqueuse, ce qui permet de pousser le pétrole de façon plus uniforme, d’améliorer le recouvrement des pores et d’augmenter la récupération totale. Le hic, c’est que le comportement des polymères est très sensible aux conditions : une concentration plus élevée épaissit généralement la solution, une température plus élevée et un cisaillement plus fort (débits plus élevés) la fluidifient habituellement, et les sels dissous peuvent affaiblir ou modifier la conformation des chaînes polymériques. Comme ces facteurs interagissent de manière complexe et non linéaire, les formules simples échouent souvent.
Constituer un jeu de données riche à partir d’expériences en laboratoire
Les auteurs se sont concentrés sur un polymère largement utilisé (SAV10, un type de HPAM) et ont réalisé 1 079 mesures de sa viscosité dans des conditions réalistes de champs pétrolifères. Ils ont varié quatre paramètres principaux : la concentration en polymère (de 1 000 à 4 000 parties par million), la température (25–80 °C), la teneur en sel simulant l’eau de mer arabique et ses dilutions, et le débit, exprimé en taux de cisaillement. Comme prévu, des solutions plus visqueuses apparaissaient à basse température, faible salinité, forte concentration et cisaillement réduit ; tous les échantillons présentaient un comportement de « diminution de viscosité par cisaillement », devenant moins visqueux lorsqu’ils étaient agités ou pompés plus rapidement. Avant la modélisation, l’équipe a nettoyé et standardisé les données, recherché les valeurs aberrantes et examiné les corrélations. La concentration montrait le lien positif le plus fort avec la viscosité, tandis que la température, le cisaillement et la salinité avaient tendance à la diminuer, mais pas de façon linéaire simple.
Soumettre de nombreuses méthodes d’apprentissage à l’épreuve
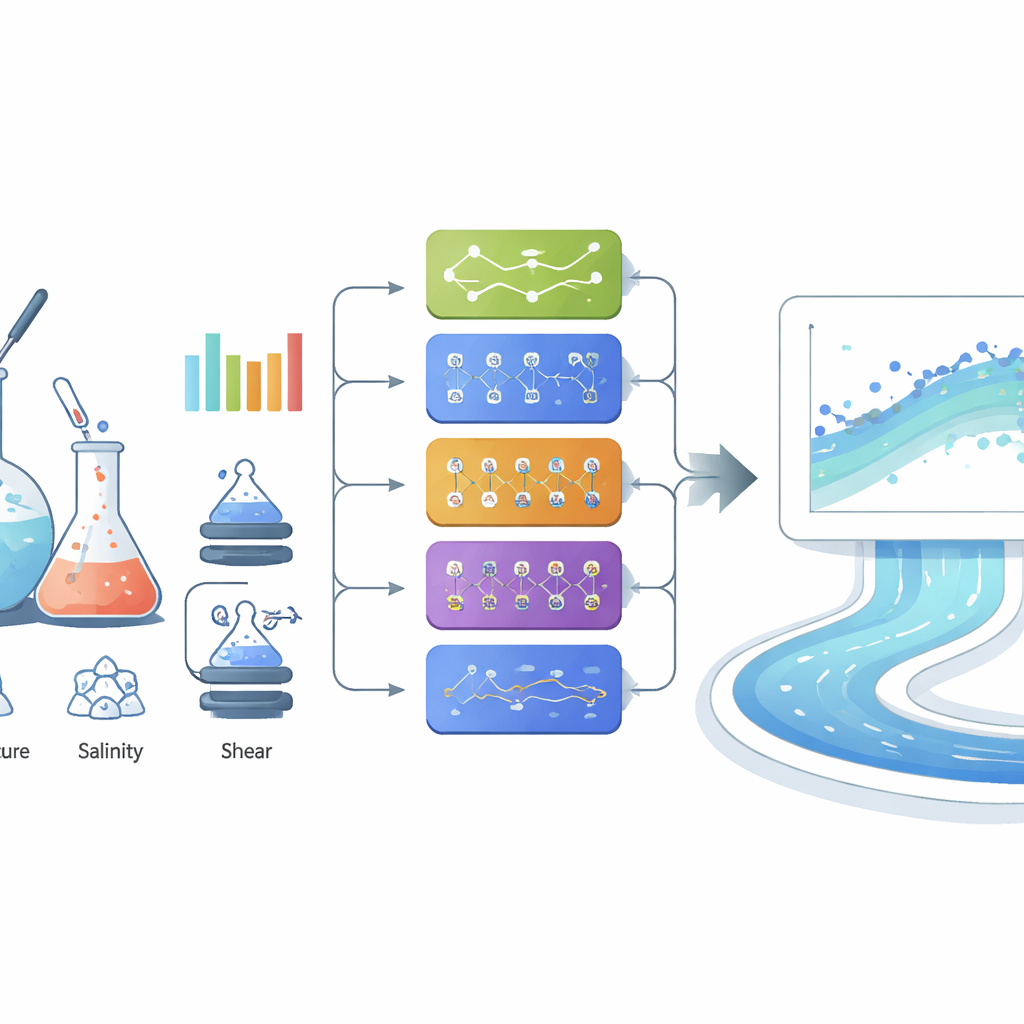
Les chercheurs ont ensuite abordé la prédiction de la viscosité comme une tâche pilotée par les données et ont comparé systématiquement différentes méthodes d’apprentissage automatique. Ils ont commencé par des outils familiers — régression linéaire, machines à vecteurs de support, arbres de décision et plusieurs réseaux neuronaux — et ont constaté que les modèles plus flexibles faisaient largement mieux que les ajustements en ligne droite. Un réseau neuronal « large » avec une seule couche cachée de 100 neurones prédisait déjà les viscosités avec une excellente précision, correspondant étroitement aux valeurs mesurées sur toute la plage. Ensuite, ils ont évalué une série de méthodes avancées appelées modèles d’ensemble, qui combinent les forces de nombreux arbres de décision ou d’apprenants boostés, ainsi que la régression par processus gaussien, une méthode probabiliste fournissant aussi des estimations d’incertitude. Plusieurs de ces modèles avancés ont donné d’excellentes performances, avec des erreurs de prédiction très faibles même pour les viscosités élevées, où de nombreuses approches traditionnelles échouent.
Pourquoi l’empilement de modèles a donné les prédictions les plus précises
Pour extraire la dernière marge de précision, l’équipe a construit un ensemble « empilé » (stacking) qui combine trois des meilleurs modèles individuels (Extra Trees, XGBoost et CatBoost) à l’aide d’un méta‑modèle simple en second niveau. Chaque modèle de base apprenait des aspects légèrement différents de la façon dont la concentration, le cisaillement, la température et la salinité influent sur la viscosité ; le méta‑modèle a ensuite appris à pondérer leurs sorties. Ce système empilé a fourni la meilleure performance de toutes les approches, avec une correspondance quasi parfaite entre viscosités prédites et mesurées et une erreur moyenne très faible, y compris pour les cas les plus visqueux — cruciaux pour la conception sur le terrain. Des outils d’explicabilité (Explainable‑AI), tels que l’importance par permutation et l’analyse SHAP, ont confirmé que la concentration en polymère est le facteur dominant, suivie du taux de cisaillement, de la température et de la salinité — un ordre cohérent avec la physique des polymères.
Ce que cela signifie pour la conception future de la récupération pétrolière
Pour le lecteur non spécialiste, l’essentiel est que l’étude transforme un processus laborieux d’essais et d’erreurs en laboratoire en un moteur de prédiction rapide et fondé sur les données. Une fois entraîné, le modèle empilé peut estimer instantanément la viscosité d’une solution de polymère pour de nouvelles combinaisons de salinité, température, flux et concentration, sans réaliser à chaque fois de nouvelles expériences. Cela peut accélérer le criblage des options de récupération, réduire les coûts et diminuer l’incertitude lors de la planification des projets d’injection de polymères. Si le travail actuel repose sur un polymère spécifique et des données à l’échelle laboratoire, la même approche pourrait être étendue à d’autres formulations et additifs, aidant finalement les ingénieurs à concevoir des fluides sur mesure pour des réservoirs plus difficiles en s’appuyant moins sur l’intuition et davantage sur les motifs appris dans les données.
Citation: Belkhir, S.A., Pakeer, A.A., Shakeel, M. et al. Comparative assessment of machine learning models for polymer solution viscosity prediction in enhanced oil recovery. Sci Rep 16, 10442 (2026). https://doi.org/10.1038/s41598-026-41045-w
Mots-clés: injection de polymère, prédiction de la viscosité, apprentissage automatique, récupération assistée du pétrole, modèles d’ensemble