Clear Sky Science · sv
SMC-LUD: Storskalig B-läges ultraljudsdataset för klassificering av hepatocellulärt karcinom och hemangiom
Varför detta betyder något för vardagshälsan
Levercancer är en av världens dödligaste cancerformer, delvis därför att den är svår att upptäcka och klassificera tidigt nog för effektiv behandling. Läkare förlitar sig ofta på ultraljud, en snabb och prisvärd undersökning, för att leta efter misstänkta förändringar i levern. Men på dessa gryniga svartvita bilder kan farliga tumörer och ofarliga tillväxter se förvirrande lika ut, även för experter. Denna artikel presenterar en stor ny bildsamling avsedd att hjälpa datorer att lära sig skilja dem åt, vilket potentiellt kan göra leverkontroller mer träffsäkra och mer tillgängliga.
En närmare titt på leverfläckar
Två vanliga fynd vid leverundersökningar ligger i varsin ände av riskskalan. Hepatocellulärt karcinom är en primär levercancer som kan vara livshotande om den missas eller upptäcks sent. Hemangiom, däremot, är vanligtvis ofarliga kluster av blodkärl som sällan kräver behandling. På enkla ultraljudsbilder kan dessa två dock vara svåra att skilja åt, särskilt när levervävnaden redan är skadad eller när förändringarna är små. Idag behöver läkare ofta beställa extra tester som datortomografi (CT) eller magnetkameraundersökning (MRI) för att vara säkra, vilket ökar kostnad, tid samt exponering för strålning eller kontrastmedel.
Att bygga ett stort bibliotek av leverbilder
För att ta itu med detta problem samlade forskare vid Samsung Medical Center i Seoul SMC-LUD, en ny offentlig samling med 5 385 leverultraljudsbilder från 1 021 verkliga patienter undersökta mellan 2015 och 2024. Varje bild visar en leverskada som noggrant klassificerats i en av två grupper: cancer (hepatocellulärt karcinom, 2 716 bilder) eller benignt hemangiom (2 669 bilder). Cancergånger bekräftades genom undersökning av vävnad borttagen vid operation eller biopsi, medan hemangiom diagnostiserades med hjälp av karakteristiska skanningsfynd tolkade av erfarna radiologer. Alla bilder anonymiserades, grupperades per patient och dubbelkontrollerades av specialister för att säkerställa tillförlitliga etiketter. 
Förberedelse av data för intelligenta algoritmer
Teamet organiserade datasättet för att göra det enkelt för artificiell intelligens-forskare att använda. Bilderna ändrades i storlek och standardiserades så att datorer ser dem i ett konsekvent format, och datan delades upp i separata grupper för träning, finjustering och slutgiltig testning, med omsorg för att bilder från samma patient aldrig förekommer i mer än en grupp. Datasättet finns också i två varianter: en "Clean"-version utan mätmarkörer och en "Caliper"-version som inkluderar dem. För rättvis testning tränade forskarna sina modeller endast på Clean-bilderna för att undvika risken att algoritmer fuskar genom att lära sig koppla markörmönster till vissa diagnoser i stället för att fokusera på själva förändringarna. En tillhörande tabell med patientinformation, såsom tumörstorlek och stadium för cancafallen, möjliggör djupare kliniska analyser.
Hur datorn lär sig att se
För att visa vad som kan göras med denna resurs byggde författarna en djuplärande modell baserad på en välkänd bildigenkänningsram och förstärkte den med speciella "attention"-moduler. Dessa komponenter hjälper nätverket att fokusera på de mest informativa delarna av bilden och de mest utslagsgivande mönstren av ljusstyrka och textur. Konstruktionen använder två parallella grenar som bearbetar samma funktioner på något olika sätt innan de återförenas och sedan applicerar ett spatialt filter som framhäver viktiga regioner, ungefär som en radiolog som mentalt zoomar in på ett misstänkt område. Tränad på SMC-LUD Clean-undermängden jämfördes denna modell med flera populära neurala nätverksdesigner för medicinsk bildbehandling. 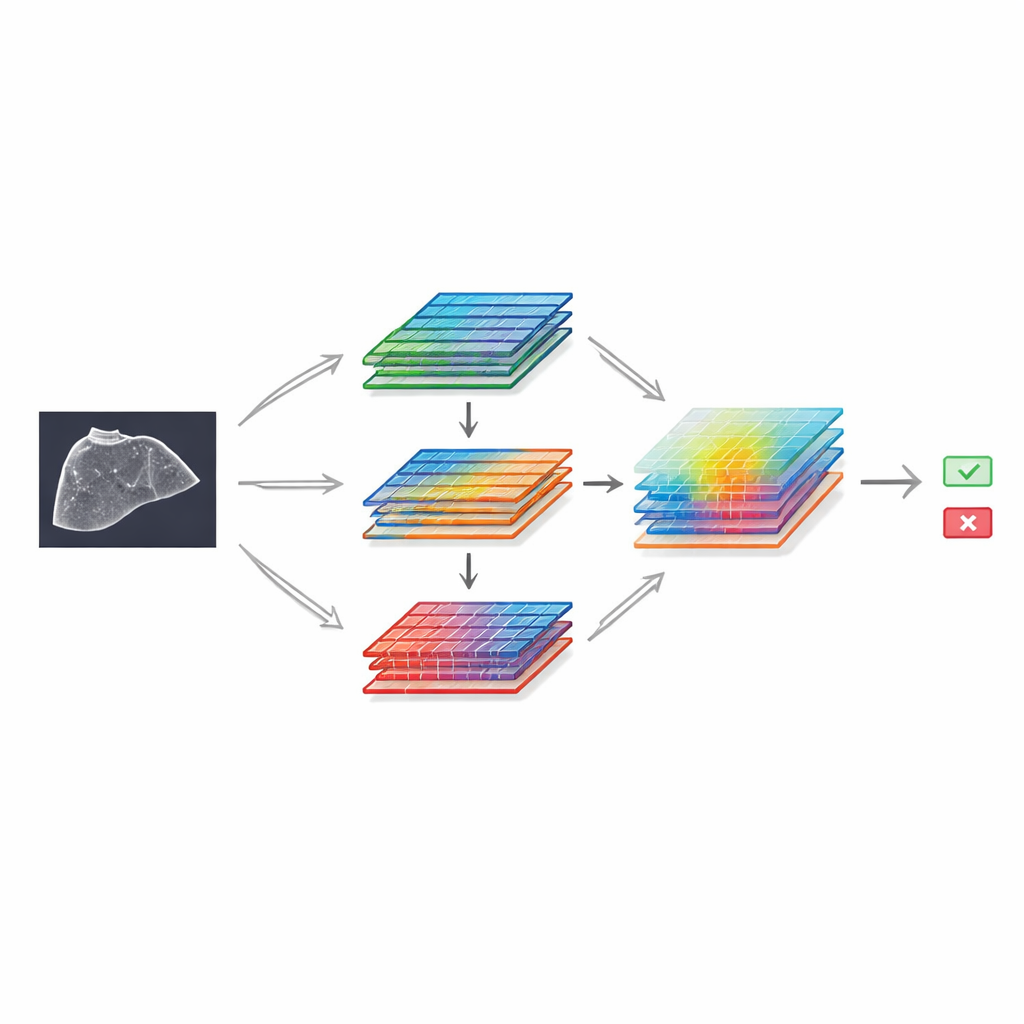
Vad resultaten visar
På de avhållna testbilderna skilde den attention-förstärkta modellen korrekt mellan levercancer och hemangiom i nära 99 % av fallen och överträffade jämförelsemodellerna. Värmekartor härledda från nätverkets interna beräkningar visade att den tenderade att fokusera på själva förändringarna snarare än på orelaterade bilddetaljer, vilket tyder på att den lärde sig medicinskt meningsfulla signaler. Även om denna studie bara utvärderar en tvåvägsdistinktion mellan en malign och en benign lesionstyp, framhäver dess prestanda både kvaliteten på bildetiketterna och potentialen för ultraljudsbaserad datordiagnostik när den förses med tillräckligt stora, välorganiserade data.
Vad detta kan innebära för patienter
För icke-specialister är huvudbudskapet att detta datasätt i sig inte förändrar hur din läkare kommer att tolka din nästa undersökning — men det lägger viktig grund. Genom att fritt dela ett stort, noggrant verifierat bibliotek av ultraljudsbilder ger författarna forskare världen över råmaterialet som behövs för att träna och testa smartare verktyg för lever-screening. I framtiden kan sådana verktyg fungera som ett andra par ögon, flagga oroväckande förändringar som förtjänar närmare granskning och minska onödig uppföljning för klart godartade fynd. I förlängningen kan detta bidra till att flytta levercancerdiagnostik mot tidigare, mer behandlingsbara stadier samtidigt som kostnader och komplexitet hålls nere.
Citering: Tak, J., Ko, RE., Kwon, R.D. et al. SMC-LUD:Large-Scale B-Mode Liver Ultrasound Dataset for Hepatocellular Carcinoma and Hemangioma Classification. Sci Data 13, 649 (2026). https://doi.org/10.1038/s41597-026-07023-7
Nyckelord: leverultraljud, hepatocellulärt karcinom, hemangiom, djuplärande, medicinskt bilddatasätt