Clear Sky Science · ru
Суррогат на основе машинного обучения для листовой модели PROSPECT-D и его применения к разным видам растений
Почему важно измерять свет от листа
Фермеры, экологи и селекционеры хотят знать, насколько растение здорово, сколько воды оно удерживает и какая часть площади листа участвует в фотосинтезе. Традиционно на эти вопросы отвечают методом срезания листьев и проведения тщательных химических анализов. В этом исследовании показано, как детальные измерения света, отражённого листьями, в сочетании с продвинутыми компьютерными моделями позволяют быстро и бесконтактно оценивать многие скрытые свойства листа и делать это для самых разных видов растений.
Чтение состояния растения по отражённому свету
Каждый лист отражает и поглощает солнечный свет по‑разному: это зависит от пигментов, внутренней структуры и содержания воды. Современные приборы могут измерять этот рисунок по сотням очень узких полос спектра, формируя так называемый гиперспектральный отпечаток. Долгое время связывать эти отпечатки с листовыми признаками пытались либо чисто статистическими методами, либо физически обоснованными моделями. Семейство моделей PROSPECT относится к последним — оно описывает прохождение света через слои листа. Модель может предсказать, каким должен быть спектр отражения листа при известных признаках и, в принципе, работать в обратном направлении, оценивая признаки по измеренным спектрам.
Проверка проверенной модели на множестве растений
Авторы поставили задачу оценить, насколько хорошо последняя версия PROSPECT-D работает в широком наборе видов и условий выращивания, а также создать более быстрые приближения с помощью машинного обучения. Они собрали девять больших наборов данных, включающих более семи тысяч спектров листьев кукурузы, сорго, сои, камелины, тропических деревьев, смешанных культур и разнообразных древесных и травянистых растений. Для каждого измеренного спектра сначала выполняли обратный запуск PROSPECT-D, чтобы вывести шесть ключевых листовых признаков, таких как уровни пигментов, содержание воды и сухая масса на единицу площади. Затем модель запускали вперёд с этими выведенными признаками, чтобы получить синтетический спектр, который должен совпадать с измеренным, если модель точна.
Где физическая модель испытывает трудности и почему
Сравнивая измеренные и сгенерированные спектры по каждой длине волны, авторы обнаружили, что PROSPECT-D очень хорошо воспроизводит отражение листа в большинстве видимой и инфракрасной областей. Основные несоответствия возникали лишь в четырёх узких полосах, где листья отражают очень мало света. Анализ кукурузы, выращенной в течение двух лет, показал, что отражение в этих проблемных полосах сильно определяется изменяющимися полевыми условиями, а не генетикой, что указывает на доминирование шумов измерений и влияния окружающей среды. Когда команда повторяла шаги «обратный→прямой» начиная с синтетических спектров вместо измеренных, совпадение было почти идеальным, что говорит о том, что сама процедура инверсии очень точна, когда данные находятся в зоне надёжности модели.
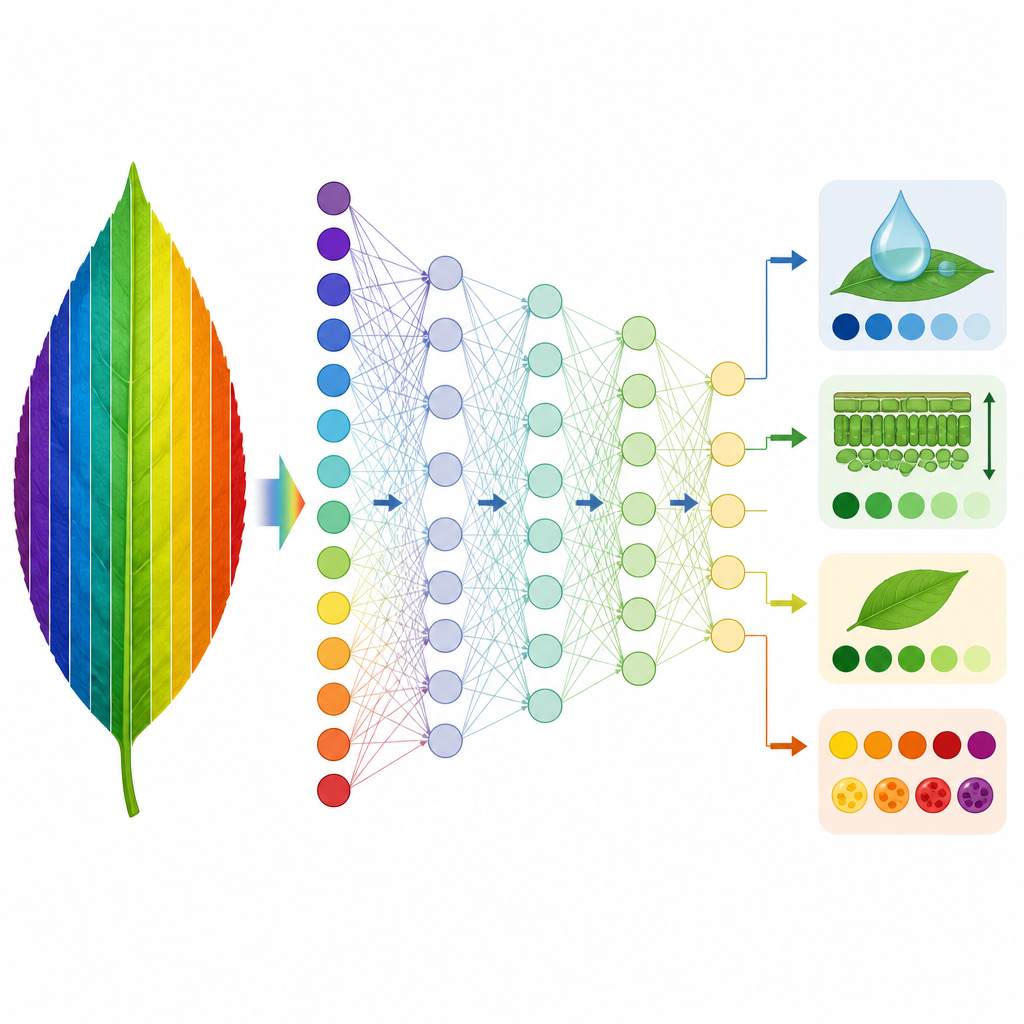
Обучение машин заменять физику
Исходя из этой базы, исследователи обучили два типа моделей, основанных на данных, чтобы имитировать PROSPECT-D. Во‑первых, они применили метод частичных наименьших квадратов (PLS-регрессия), чтобы усвоить связь между симулированными спектрами и листовыми признаками, которые вывела PROSPECT-D. Модели, обученные на одном виде, затем тестировали на других. Для четырёх признаков, связанных со структурой листа, хлорофиллом, водой и сухой массой, такие модели хорошо переносились между большинством наборов данных, особенно если обучение проводилось на самых разнообразных коллекциях видов. Два пигментных признака, связанные с каротиноидами и антоцианинами, оказались труднее предсказываемыми между видами — вероятно, потому что их спектральные сигнатуры слабы и перекрываются с хлорофиллом. Во‑вторых, команда обучила глубокие нейронные сети непосредственно на измеренных спектрах для предсказания тех же признаков, создав быстрый суррогат для полной физически обоснованной инверсии.
Более быстрый путь от спектров к признакам
Нейронные сети, обученные на двух разнообразных коллекциях растений, смогли восстановить четыре основных листовых признака по измеренным спектрам с точностью, близкой к PROSPECT-D, но за долю времени вычислений. Метод интерпретируемости показал, что эти сети естественно недооценивают шумные полосы длин волн, в которых PROSPECT-D работает хуже, и вместо этого опираются на спектральные области, где модель и измерения согласуются. Хотя два пигментных признака остаются проблемными, исследование предоставляет практичный и переносимый инструмент для оценки ключевых свойств листьев по гиперспектральному отражению и общую схему для выявления и исправления слабых мест физически обоснованных моделей листьев растений.
Цитирование: Rahimi-Majd, M., Xu, R., Bauermeister, S. et al. Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species. Sci Rep 16, 15602 (2026). https://doi.org/10.1038/s41598-026-53899-1
Ключевые слова: гиперспектральное отражение листа, PROSPECT-D, суррогат машинного обучения, оценка листовых признаков, фенотипирование растений