Clear Sky Science · fr
Surrogat d'apprentissage automatique du modèle foliaire PROSPECT-D et ses applications à travers les espèces végétales
Pourquoi mesurer la lumière des feuilles importe
Agriculteurs, écologues et sélectionneurs veulent tous savoir si une plante est en bonne santé, combien d’eau elle contient, et quelle part de sa surface foliaire est consacrée à la photosynthèse. Traditionnellement, répondre à ces questions implique de couper des feuilles et d’effectuer des tests chimiques minutieux. Cette étude montre comment des mesures détaillées de la lumière réfléchie par les feuilles, combinées à des modèles informatiques intelligents, peuvent estimer rapidement nombre de ces propriétés cachées sans dommage et ce, pour des espèces végétales très diverses.
Lire la santé des plantes à partir de la lumière réfléchie
Chaque feuille réfléchit et absorbe la lumière du soleil selon un motif qui dépend de ses pigments, de sa structure interne et de sa teneur en eau. Les instruments modernes peuvent mesurer ce motif à des centaines de couleurs très fines, formant ce que l’on appelle une empreinte hyperspectrale. Les chercheurs ont depuis longtemps utilisé soit des outils purement statistiques soit des modèles basés sur la physique pour relier ces empreintes aux traits foliaires. La famille de modèles PROSPECT appartient au camp des modèles physiques : elle décrit comment la lumière traverse les couches d’une feuille. Elle peut prédire à quoi devrait ressembler le spectre de réflectance d’une feuille si l’on connaît ses traits et, en principe, peut être utilisée en sens inverse pour estimer ces traits à partir de spectres mesurés.
Tester un modèle fiable à travers de nombreuses plantes
L’équipe a entrepris d’évaluer dans quelle mesure la version la plus récente, PROSPECT D, fonctionne sur une large diversité d’espèces et de conditions de croissance, et de construire des raccourcis plus rapides via l’apprentissage automatique. Ils ont rassemblé neuf jeux de données volumineux contenant plus de sept mille spectres de feuilles issus de maïs, sorgho, soja, caméline, arbres tropicaux, cultures mixtes et diverses plantes ligneuses et herbacées. Pour chaque spectre mesuré, ils ont d’abord exécuté PROSPECT D en sens inverse pour inférer six traits foliaires clés, tels que les niveaux de pigments, la teneur en eau et la masse sèche par unité de surface. Ils ont ensuite exécuté le modèle vers l’avant avec ces traits inférés pour créer un spectre synthétique qui devrait correspondre au spectre mesuré si le modèle est exact.
Où le modèle physique bute et pourquoi
En comparant les spectres mesurés et simulés à chaque longueur d’onde, les auteurs ont constaté que PROSPECT D reproduisait la réflectance foliaire extrêmement bien sur la plupart des plages visible et infrarouge. Les principales discordances apparaissaient seulement dans quatre bandes de couleurs étroites où les feuilles réfléchissent très peu de lumière. Une analyse du maïs cultivé sur deux années a montré que la réflectance dans ces bandes problématiques est fortement influencée par des conditions de terrain changeantes plutôt que par la génétique, ce qui suggère que le bruit de mesure et les effets environnementaux y dominent. Lorsque l’équipe a répété les étapes inverse et directe en partant des spectres synthétiques plutôt que des spectres mesurés, la concordance était presque parfaite, ce qui indique que la procédure d’inversion elle-même est très précise lorsque les données se situent dans la zone de confort du modèle.
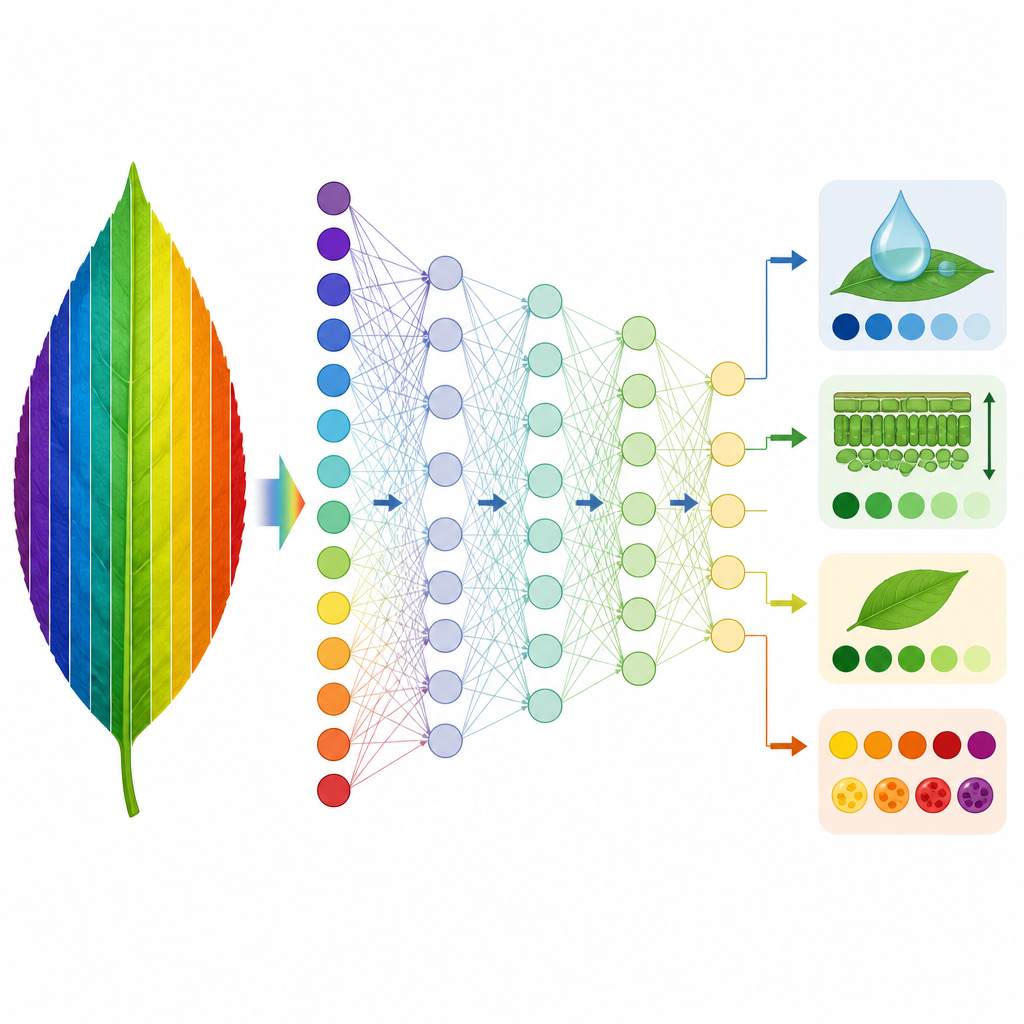
Apprendre aux machines à remplacer la physique
Sur cette base, les chercheurs ont entraîné deux types de modèles data-driven pour imiter PROSPECT D. D’abord, ils ont utilisé une méthode appelée régression par moindres carrés partiels (PLS) pour apprendre le lien entre les spectres simulés et les traits foliaires que PROSPECT D avait inférés. Les modèles entraînés sur une espèce ont ensuite été testés sur d’autres. Pour quatre traits liés à la structure foliaire, à la chlorophylle, à l’eau et à la masse sèche, ces modèles se sont bien transférés entre la plupart des jeux de données, surtout lorsqu’ils étaient entraînés sur les collections les plus diversifiées d’espèces. Deux traits pigmentaires, associés aux caroténoïdes et aux anthocyanines, se sont révélés plus difficiles à prédire de façon fiable entre espèces, probablement parce que leurs signatures spectrales sont faibles et se chevauchent avec celles de la chlorophylle. Ensuite, l’équipe a entraîné des réseaux neuronaux profonds directement sur des spectres mesurés pour prédire les mêmes traits, créant un surrogat rapide pour l’exécution complète de l’inversion physique.
Un chemin plus rapide des spectres aux traits
Les réseaux neuronaux entraînés sur deux collections végétales diversifiées ont pu retrouver quatre traits foliaires centraux à partir des spectres mesurés avec une précision proche de celle de PROSPECT D, mais en une fraction du temps de calcul. Une méthode d’interprétabilité a montré que ces réseaux minimisaient naturellement l’importance des bandes de longueurs d’onde bruitées où PROSPECT D présente de faibles performances, et s’appuyaient plutôt sur des régions spectrales où le modèle et les mesures sont en accord. Si deux traits pigmentaires demeurent difficiles, l’étude fournit un outil pratique et transférable pour estimer des propriétés foliaires clés à partir de la réflectance hyperspectrale et un cadre général pour repérer et corriger les faiblesses des modèles physiques de la feuille de plante.
Citation: Rahimi-Majd, M., Xu, R., Bauermeister, S. et al. Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species. Sci Rep 16, 15602 (2026). https://doi.org/10.1038/s41598-026-53899-1
Mots-clés: réflectance hyperspectrale foliaire, PROSPECT-D, surrogat en apprentissage automatique, estimation des traits foliaires, phénotypage des plantes