Clear Sky Science · de
Maschinelles Lern‑Surrogat für das Blattmodell PROSPECT‑D und seine Anwendungen über Pflanzenarten hinweg
Warum die Messung von Blattlicht wichtig ist
Bäuerinnen und Bauern, Ökologinnen und Ökologen sowie Pflanzenzüchter wollen wissen, wie gesund eine Pflanze ist, wie viel Wasser sie speichert und wie viel ihrer Blattfläche der Photosynthese gewidmet ist. Traditionell bedeutet die Beantwortung dieser Fragen, Blätter zu schneiden und aufwändige chemische Tests durchzuführen. Diese Studie zeigt, wie detaillierte Messungen des von Blättern reflektierten Lichts in Kombination mit ausgeklügelten Computer‑Modellen viele dieser verborgenen Blattparameter schnell und schonend schätzen können — und das über sehr unterschiedliche Pflanzenarten hinweg.
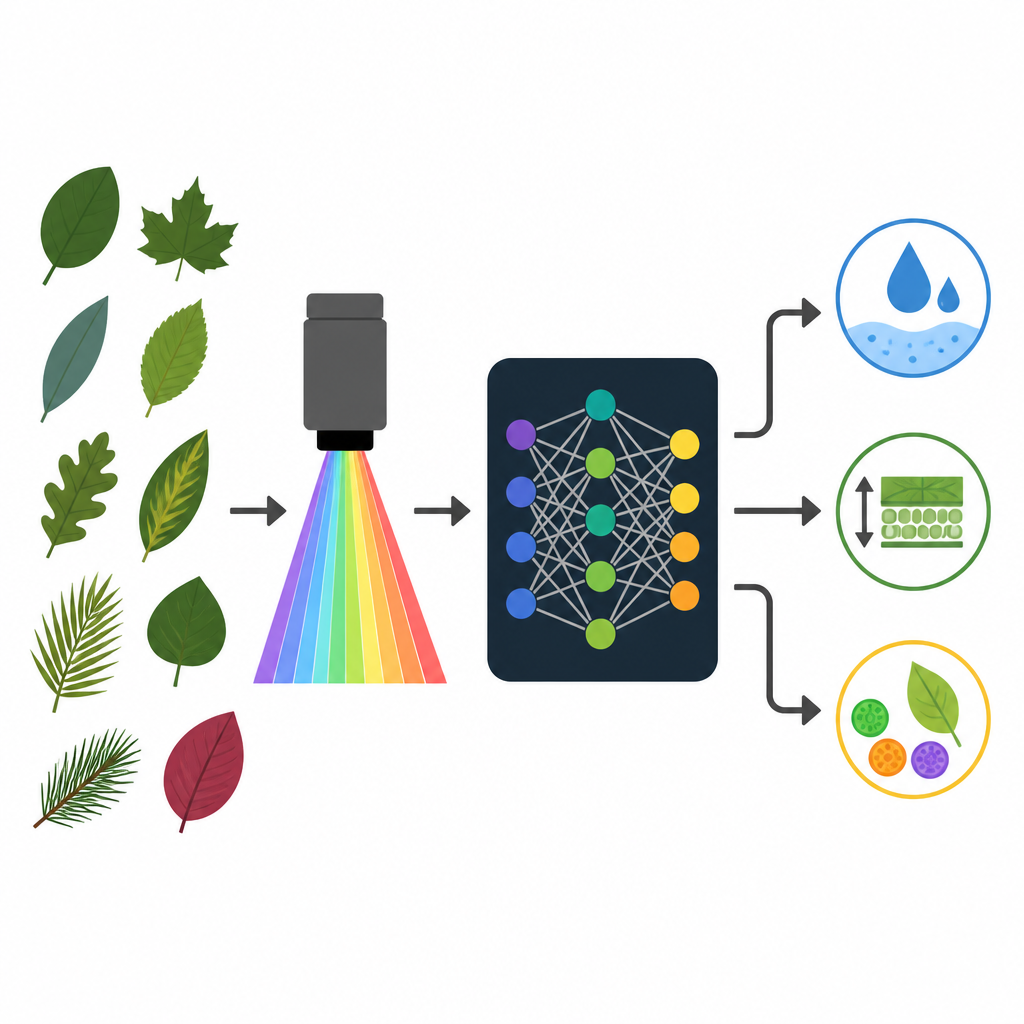
Gesundheit von Pflanzen aus reflektiertem Licht lesen
Jedes Blatt reflektiert und absorbiert Sonnenlicht in einem Muster, das von seinen Pigmenten, seiner inneren Struktur und seinem Wassergehalt abhängt. Moderne Instrumente können dieses Muster in Hunderten sehr schmaler Farbkanäle messen und so einen sogenannten hyperspektralen Fingerabdruck erstellen. Forschende haben lange entweder rein statistische Werkzeuge oder physikbasierte Modelle verwendet, um diese Fingerabdrücke mit Blattmerkmalen zu verknüpfen. Die PROSPECT‑Modellfamilie gehört zur physikbasierten Seite und beschreibt, wie Licht durch die Schichten eines Blattes wandert. Sie kann vorhersagen, wie das Reflexionsspektrum eines Blattes aussehen sollte, wenn man seine Merkmale kennt, und sich prinzipiell umkehren lassen, um diese Merkmale aus gemessenen Spektren zu schätzen.
Ein bewährtes Modell über viele Pflanzen testen
Das Team setzte sich zum Ziel zu prüfen, wie gut die neueste Version, PROSPECT‑D, über eine breite Palette von Arten und Wachstumsbedingungen funktioniert, und schnellere Abkürzungen mit maschinellem Lernen zu entwickeln. Sie stellten neun große Datensätze mit mehr als siebentausend Blattspektren zusammen, darunter Mais, Sorghum, Sojabohne, Camelina, tropische Bäume, Mischanbau und vielfältige Holz‑ und krautige Pflanzen. Für jedes gemessene Spektrum ließen sie zunächst PROSPECT‑D rückwärts laufen, um sechs Schlüsselblattmerkmale zu inferieren, etwa Pigmentgehalte, Wassergehalt und Trockenmasse pro Fläche. Anschließend führten sie das Modell mit diesen inferierten Merkmalen vorwärts, um ein synthetisches Spektrum zu erzeugen, das mit dem gemessenen übereinstimmen sollte, wenn das Modell genau ist.
Woran das physikalische Modell scheitert und warum
Durch den Vergleich gemessener und simulierter Spektren bei jeder Wellenlänge stellten die Autorinnen und Autoren fest, dass PROSPECT‑D die Blattreflektanz über weite Teile des sichtbaren und infraroten Bereichs äußerst gut nachbildet. Die wichtigsten Abweichungen traten nur in vier schmalen Farbbändern auf, in denen Blätter sehr wenig Licht reflektieren. Eine Analyse von über zwei Jahre angebautem Mais zeigte, dass die Reflektanz in diesen problematischen Bändern stark von wechselnden Feldbedingungen statt von der Genetik getrieben wird, was darauf hindeutet, dass Messrauschen und Umwelteinflüsse dort dominieren. Als das Team die Rückwärts‑ und Vorwärts‑Schritte erneut durchführte, diesmal ausgehend von den synthetischen statt den gemessenen Spektren, war die Übereinstimmung nahezu perfekt — ein Hinweis darauf, dass das Inversionsverfahren selbst sehr genau ist, wenn die Daten in den Modell‑Gültigkeitsbereich fallen.
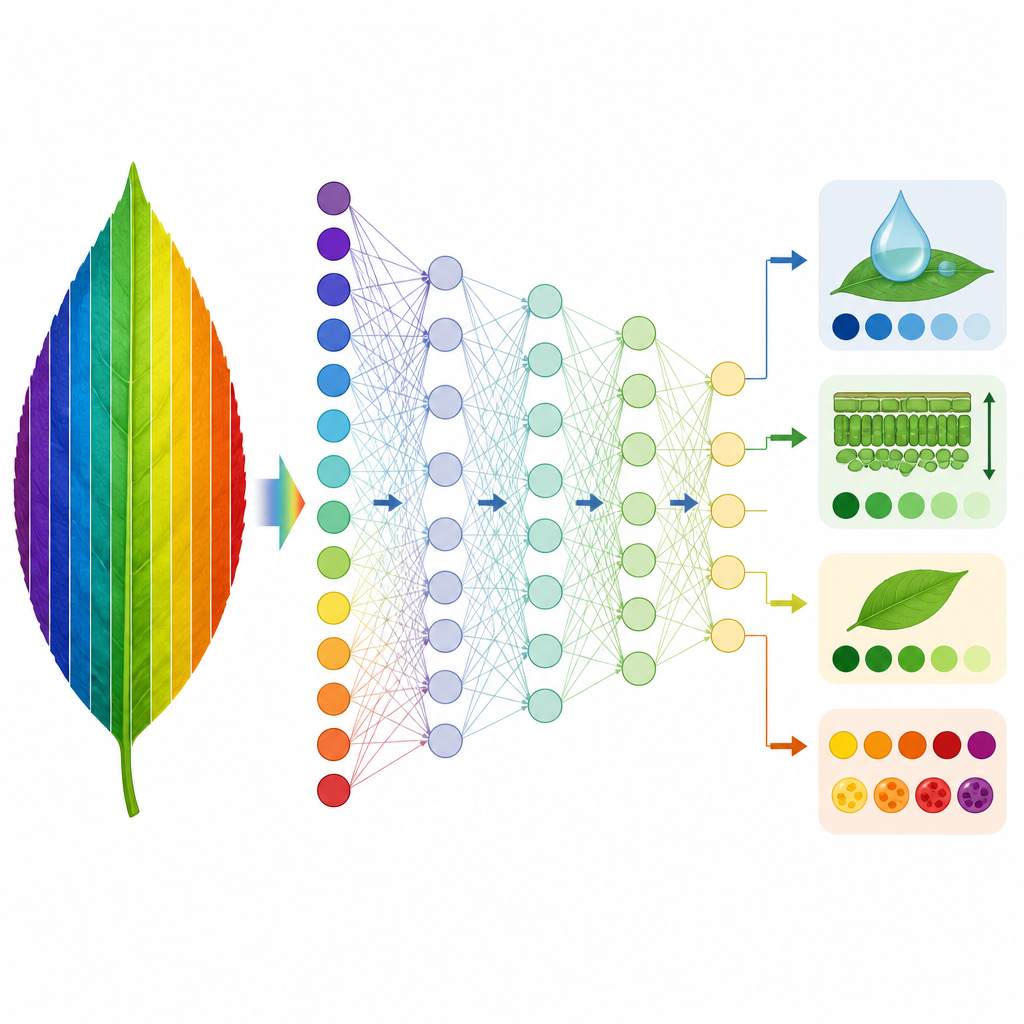
Maschinen beibringen, die Physik zu vertreten
Auf dieser Grundlage trainierten die Forschenden zwei Arten datengetriebener Modelle, um PROSPECT‑D nachzuahmen. Zuerst verwendeten sie eine Methode namens partielle kleinste Quadrate (PLS‑Regression), um die Verbindung zwischen simulierten Spektren und den von PROSPECT‑D inferierten Blattmerkmalen zu erlernen. Modelle, die an einer Art trainiert wurden, testeten sie anschließend an anderen Arten. Für vier Merkmale — Blattstruktur, Chlorophyll, Wasser und Trockenmasse — übertrugen sich diese Modelle sehr gut zwischen den meisten Datensätzen, besonders wenn sie an den vielfältigsten Artensammlungen trainiert wurden. Zwei Pigmentmerkmale, die mit Carotinoiden und Anthocyanen zusammenhängen, erwiesen sich als schwerer zuverlässig über Arten hinweg vorherzusagen, vermutlich weil ihre spektralen Signaturen schwach sind und sich mit denen des Chlorophylls überlappen. Zweitens trainierte das Team tiefe neuronale Netze direkt an gemessenen Spektren, um dieselben Merkmale vorherzusagen und so einen schnellen Surrogatweg zur vollständigen physikbasierten Inversion zu schaffen.
Ein schnellerer Weg von Spektren zu Merkmalen
An zwei vielfältigen Pflanzensammlungen trainierte neuronale Netze konnten vier zentrale Blattmerkmale aus gemessenen Spektren mit einer Genauigkeit wiederherstellen, die nahe an der von PROSPECT‑D lag — jedoch in einem Bruchteil der Rechenzeit. Eine Interpretierbarkeitsmethode zeigte, dass diese Netze natürlicherweise die verrauschten Wellenlängenbänder, in denen PROSPECT‑D schlecht abschneidet, heruntergewichten und stattdessen auf spektrale Regionen setzen, in denen Modell und Messungen übereinstimmen. Zwar bleiben zwei Pigmentmerkmale herausfordernd, doch liefert die Studie ein praktisches, transferierbares Werkzeug zur Schätzung wichtiger Blattparameter aus hyperspektraler Reflektanz und einen allgemeinen Rahmen, um Schwächen physikbasierter Blattsimulationen zu erkennen und zu korrigieren.
Zitation: Rahimi-Majd, M., Xu, R., Bauermeister, S. et al. Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species. Sci Rep 16, 15602 (2026). https://doi.org/10.1038/s41598-026-53899-1
Schlüsselwörter: hyperspektrale Blattreflektanz, PROSPECT‑D, maschinelles Lern‑Surrogat, Schätzung von Blattmerkmalen, Pflanzenphänotypisierung