Clear Sky Science · nl
Machine learning-surrogaat voor het bladmodel PROSPECT-D en de toepassingen ervan over plantensoorten heen
Waarom het meten van bladlicht belangrijk is
Boeren, ecologen en plantenveredelaars willen allemaal weten hoe gezond een plant is, hoeveel water ze vasthoudt en welk deel van het bladmassa bedoeld is voor fotosynthese. Traditioneel betekent het beantwoorden van deze vragen dat je bladeren moet nemen en zorgvuldige chemische tests uitvoeren. Deze studie laat zien hoe gedetailleerde metingen van het licht dat door bladeren wordt teruggekaatst, gecombineerd met slimme computermodellen, veel van deze verborgen bladdeigenschappen snel en schadevrij kunnen schatten, en dat over zeer verschillende plantensoorten heen.
Plantgezondheid aflezen uit teruggekaatst licht
Elk blad reflecteert en absorbeert zonlicht in een patroon dat afhangt van zijn pigmenten, interne structuur en watergehalte. Moderne instrumenten kunnen dit patroon meten op honderden zeer smalle kleuren, waardoor een zogeheten hyperspectrale vingerafdruk ontstaat. Onderzoekers hebben lang gebruikgemaakt van zowel puur statistische hulpmiddelen als fysica-gebaseerde modellen om deze vingerafdrukken te koppelen aan blaadeigenschappen. De PROSPECT-familie van modellen behoort tot de fysica-gebaseerde kant en beschrijft hoe licht door de lagen van een blad reist. Het kan voorspellen hoe het reflectiespectrum van een blad eruit zou moeten zien als je zijn eigenschappen kent en kan in principe ook omgekeerd worden gebruikt om die eigenschappen uit gemeten spectra af te leiden.
Een vertrouwd model testen over veel planten
Het team wilde onderzoeken hoe goed de nieuwste versie, PROSPECT D, presteert over een breed scala aan soorten en groeiomstandigheden, en ook snellere snelkoppelingen naar het model bouwen met machine learning. Ze verzamelden negen grote datasets met meer dan zevenduizend bladspectra van maïs, sorgho, soja, camelina, tropische bomen, gemengde gewassen en diverse houtige en kruidachtige planten. Voor elk gemeten spectrum lieten ze eerst PROSPECT D omgekeerd lopen om zes belangrijke blaadeigenschappen af te leiden, zoals pigmentniveaus, watergehalte en droge massa per oppervlakte-eenheid. Vervolgens lieten ze het model vooruit draaien met deze afgeleide eigenschappen om een synthetisch spectrum te creëren dat het gemeten spectrum zou moeten naderen als het model nauwkeurig is.
Waar het fysicamodel moeite mee heeft en waarom
Door gemeten en gesimuleerde spectra bij elke golflengte te vergelijken, vonden de auteurs dat PROSPECT D de bladreflectantie buitengewoon goed reproduceerde over het grootste deel van het zichtbare en infrarode bereik. De belangrijkste mismatches traden alleen op in vier smalle kleurbanden waar bladeren zeer weinig licht reflecteren. Een analyse van maïs gekweekt over twee jaar liet zien dat reflectantie in deze lastige banden sterk wordt aangedreven door wisselende veldcondities in plaats van door genetica, wat suggereert dat meetruis en omgevingsfactoren daar de overhand hebben. Wanneer het team de omgekeerde en vooruitstap herhaalde uitgaande van de synthetische spectra in plaats van de gemeten, was de overeenkomst vrijwel perfect, wat erop wijst dat de inversieprocedure zelf zeer nauwkeurig is wanneer de data binnen de comfortzone van het model vallen.
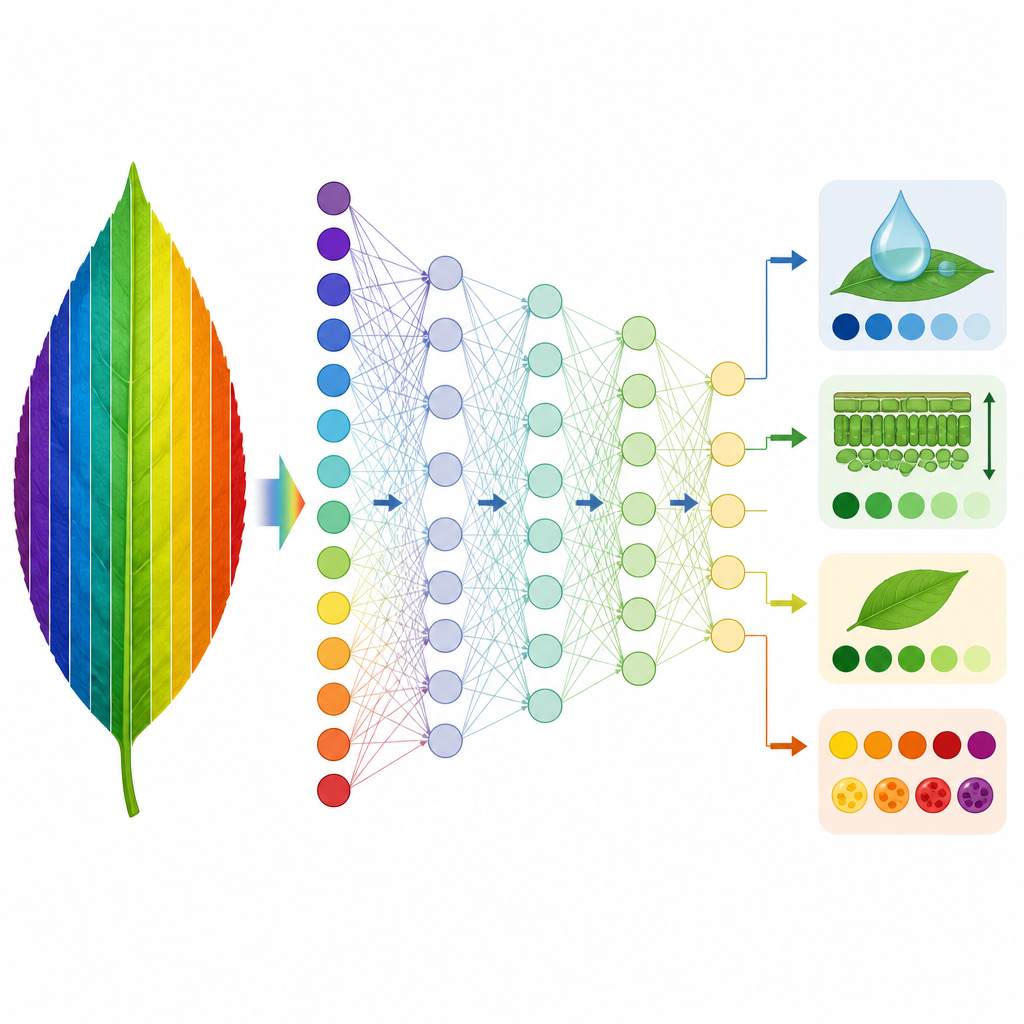
Machines leren in de plaats van de fysica
Op basis van deze fundamenten trainden de onderzoekers twee soorten datagedreven modellen om PROSPECT D te imiteren. Eerst gebruikten ze een methode genaamd partial least squares-regressie om de koppeling te leren tussen gesimuleerde spectra en de blaadeigenschappen die PROSPECT D had afgeleid. Modellen die op één soort waren getraind, werden vervolgens op andere soorten getest. Voor vier eigenschappen gerelateerd aan bladstructuur, chlorofyl, water en droge massa transfereerden deze modellen zeer goed tussen de meeste datasets, vooral wanneer ze waren getraind op de meest diverse verzamelingen van soorten. Twee pigmenteigenschappen, verbonden aan carotenoïden en anthocyanen, bleken moeilijker betrouwbaar over soorten heen te voorspellen, waarschijnlijk omdat hun spectrale signaturen zwak zijn en overlappen met die van chlorofyl. Ten tweede trainde het team diepe neurale netwerken direct op gemeten spectra om dezelfde eigenschappen te voorspellen, waardoor een snelle surrogaat ontstond voor het uitvoeren van de volledige fysica-gebaseerde inversie.
Een snellere route van spectra naar eigenschappen
Neurale netwerken die op twee diverse plantencollecties waren getraind, wisten vier kernblaadeigenschappen uit gemeten spectra terug te winnen met een nauwkeurigheid dicht bij die van PROSPECT D, maar in slechts een fractie van de rekentijd. Een interpretatiemethode toonde aan dat deze netwerken de ruisige golflengtebanden waar PROSPECT D slecht presteert van nature minder zwaar lieten meetellen, en in plaats daarvan vertrouwden op spectrale gebieden waar model en metingen overeenkomen. Hoewel twee pigmenteigenschappen moeilijk blijven, levert de studie een praktisch en overdraagbaar hulpmiddel voor het schatten van belangrijke bladmaten uit hyperspectrale reflectantie, en een algemeen kader om zwakheden in fysica-gebaseerde modellen van plantenbladeren te signaleren en te corrigeren.
Bronvermelding: Rahimi-Majd, M., Xu, R., Bauermeister, S. et al. Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species. Sci Rep 16, 15602 (2026). https://doi.org/10.1038/s41598-026-53899-1
Trefwoorden: blad hyperspectrale reflectantie, PROSPECT-D, machine learning-surrogaat, schatting van blaadeigenschappen, plantfenotypering