Clear Sky Science · es
Surrogado de aprendizaje automático para el modelo foliar PROSPECT-D y sus aplicaciones entre especies vegetales
Por qué importa medir la luz de la hoja
Agricultores, ecólogos y mejoradores de plantas quieren saber cuán sana está una planta, cuánta agua contiene y qué porción de su área foliar está dedicada a la fotosíntesis. Tradicionalmente, responder a estas preguntas implica cortar hojas y realizar análisis químicos cuidadosos. Este estudio muestra cómo mediciones detalladas de la luz reflejada por las hojas, combinadas con modelos computacionales inteligentes, pueden estimar muchas de estas propiedades ocultas de la hoja de forma rápida y sin dañarlas, y hacerlo entre especies vegetales muy distintas.
Leer la salud de la planta a partir de la luz reflejada
Cada hoja refleja y absorbe la luz solar siguiendo un patrón que depende de sus pigmentos, de su estructura interna y de su contenido de agua. Instrumentos modernos pueden medir este patrón en cientos de colores muy estrechos, creando lo que se denomina una huella hiperespectral. Durante mucho tiempo, los investigadores han utilizado herramientas puramente estadísticas o modelos basados en la física para vincular estas huellas con los rasgos foliares. La familia de modelos PROSPECT pertenece al grupo basado en la física, describiendo cómo viaja la luz a través de las capas de una hoja. Puede predecir cómo debería ser el espectro de reflectancia de una hoja si se conocen sus rasgos y, en principio, puede invertirse para estimar esos rasgos a partir de espectros medidos.
Probar un modelo de confianza en muchas plantas
El equipo se propuso evaluar qué tan bien funciona la versión más reciente, PROSPECT D, a lo largo de una amplia gama de especies y condiciones de cultivo, y construir atajos más rápidos mediante aprendizaje automático. Reunieron nueve conjuntos de datos grandes que contenían más de siete mil espectros foliares de maíz, sorgo, soja, camelina, árboles tropicales, cultivos mixtos y diversas plantas leñosas y herbáceas. Para cada espectro medido, primero dejaron que PROSPECT D funcionara a la inversa para inferir seis rasgos foliares clave, como niveles de pigmentos, contenido de agua y masa seca por área. Luego ejecutaron el modelo hacia adelante con esos rasgos inferidos para crear un espectro sintético que debería coincidir con el medido si el modelo es preciso.
Dónde el modelo físico falla y por qué
Al comparar los espectros medidos y simulados en cada longitud de onda, los autores encontraron que PROSPECT D reproducía la reflectancia foliar de forma excelente en la mayor parte del rango visible e infrarrojo. Los principales desajustes aparecieron solo en cuatro bandas de color estrechas donde las hojas reflejan muy poca luz. Un análisis del maíz cultivado durante dos años mostró que la reflectancia en estas bandas problemáticas está fuertemente condicionada por cambios en las condiciones del campo más que por la genética, lo que sugiere que el ruido de medición y los efectos ambientales dominan allí. Cuando el equipo repitió los pasos inverso y directo partiendo de los espectros sintéticos en lugar de los medidos, la coincidencia fue casi perfecta, lo que indica que el procedimiento de inversión en sí es muy preciso cuando los datos se encuentran dentro de la zona de confort del modelo.
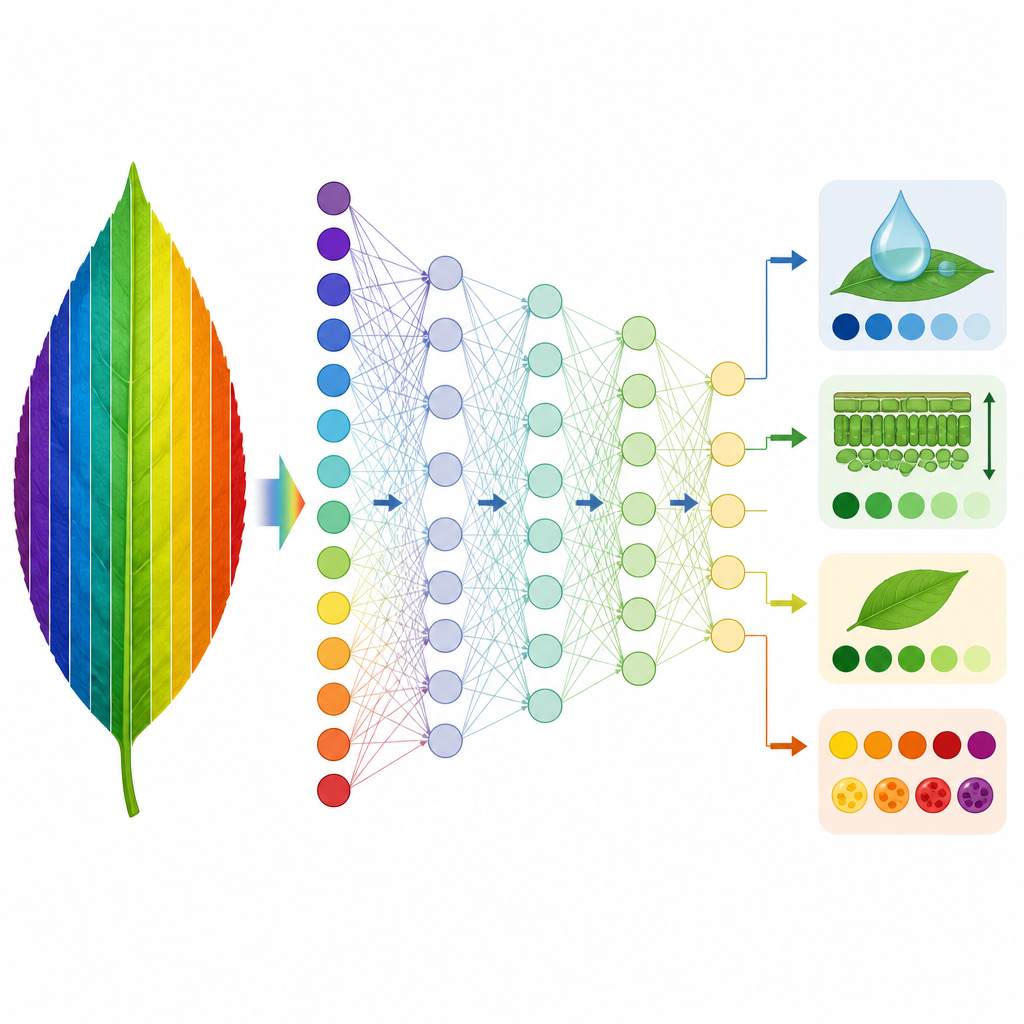
Enseñar a las máquinas a sustituir a la física
Con esta base, los investigadores entrenaron dos tipos de modelos basados en datos para imitar a PROSPECT D. Primero, usaron un método llamado regresión por mínimos cuadrados parciales para aprender la relación entre los espectros simulados y los rasgos foliares que PROSPECT D había inferido. Los modelos entrenados en una especie se probaron luego en otras. Para cuatro rasgos relacionados con la estructura foliar, la clorofila, el agua y la masa seca, estos modelos transfirieron muy bien entre la mayoría de los conjuntos de datos, especialmente cuando se entrenaron con las colecciones más diversas de especies. Dos rasgos de pigmentos, vinculados a carotenoides y antocianinas, resultaron más difíciles de predecir de forma fiable entre especies, probablemente porque sus firmas espectrales son débiles y se superponen con las de la clorofila. En segundo lugar, el equipo entrenó redes neuronales profundas directamente con espectros medidos para predecir los mismos rasgos, creando un sustituto rápido para ejecutar la inversión física completa.
Un camino más rápido de espectros a rasgos
Las redes neuronales entrenadas en dos colecciones diversas de plantas pudieron recuperar cuatro rasgos foliares centrales a partir de espectros medidos con una precisión cercana a la de PROSPECT D, pero en una fracción del tiempo de cálculo. Un método de interpretabilidad mostró que estas redes restaban importancia de forma natural a las bandas de longitud de onda ruidosas donde PROSPECT D tiene un desempeño pobre, y en su lugar se basaban en regiones espectrales donde el modelo y las mediciones concuerdan. Si bien dos rasgos de pigmentos siguen siendo un desafío, el estudio proporciona una herramienta práctica y transferible para estimar propiedades foliares clave a partir de la reflectancia hiperespectral y un marco general para detectar y corregir debilidades en los modelos físicos de las hojas de las plantas.
Cita: Rahimi-Majd, M., Xu, R., Bauermeister, S. et al. Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species. Sci Rep 16, 15602 (2026). https://doi.org/10.1038/s41598-026-53899-1
Palabras clave: reflectancia foliar hiperespectral, PROSPECT-D, surrogado de aprendizaje automático, estimación de rasgos foliares, fenotipado vegetal