Clear Sky Science · it
Surrogato di apprendimento automatico per il modello fogliare PROSPECT-D e sue applicazioni tra le specie vegetali
Perché misurare la luce delle foglie è importante
Agricoltori, ecologi e miglioratori genetici vogliono tutti sapere quanto è sana una pianta, quanta acqua contiene e quanto della sua area fogliare è dedicata alla fotosintesi. Tradizionalmente, rispondere a queste domande richiede il taglio delle foglie e l’esecuzione di test chimici accurati. Questo studio mostra come misure dettagliate della luce riflessa dalle foglie, combinate con modelli computazionali intelligenti, possano stimare molte di queste proprietà nascoste rapidamente e senza danneggiare le piante, e farlo attraverso specie molto diverse tra loro.
Leggere la salute delle piante dalla luce riflessa
Ogni foglia riflette e assorbe la luce solare in un pattern che dipende dai suoi pigmenti, dalla struttura interna e dal contenuto di acqua. Strumenti moderni possono misurare questo pattern in centinaia di colori molto stretti, creando quella che viene chiamata un’impronta iperspettrale. I ricercatori hanno da tempo utilizzato sia strumenti puramente statistici sia modelli basati sulla fisica per collegare queste impronte ai tratti fogliari. La famiglia di modelli PROSPECT appartiene al filone basato sulla fisica, descrivendo come la luce si propaga attraverso gli strati di una foglia. Può prevedere come dovrebbe apparire lo spettro di riflettanza di una foglia se si conoscono i suoi tratti e, in principio, può essere eseguito al contrario per stimare quei tratti a partire da spettri misurati.
Testare un modello consolidato su molte piante
Il team ha voluto verificare quanto bene l’ultima versione, PROSPECT D, funzioni su un’ampia gamma di specie e condizioni di crescita, e costruire scorciatoie più veloci usando l’apprendimento automatico. Hanno assemblato nove grandi set di dati contenenti più di settemila spettri fogliari provenienti da mais, sorgo, soia, camelina, alberi tropicali, colture miste e piante legnose e erbacee diverse. Per ogni spettro misurato, hanno prima eseguito PROSPECT D al contrario per inferire sei tratti fogliari chiave, come livelli di pigmenti, contenuto d’acqua e massa secca per unità di area. Hanno poi eseguito il modello in avanti con questi tratti inferiti per creare uno spettro sintetico che dovrebbe corrispondere a quello misurato se il modello è accurato.
Dove il modello fisico fatica e perché
Confrontando spettri misurati e simulati a ogni lunghezza d’onda, gli autori hanno riscontrato che PROSPECT D riproduce la riflettanza fogliare in modo eccellente sulla maggior parte delle gamme visibile e infrarossa. I principali disallineamenti sono comparsi solo in quattro bande strette di colore dove le foglie riflettono pochissima luce. Un’analisi sul mais coltivato in due anni ha mostrato che la riflettanza in queste bande problematiche è fortemente guidata dalle condizioni del campo che cambiano piuttosto che dalla genetica, suggerendo che il rumore di misura e gli effetti ambientali dominano lì. Quando il team ha ripetuto i passaggi di inversione e simulazione partendo dagli spettri sintetici invece che da quelli misurati, la corrispondenza è risultata quasi perfetta, il che indica che la procedura di inversione in sé è molto accurata quando i dati rientrano nella zona di validità del modello.
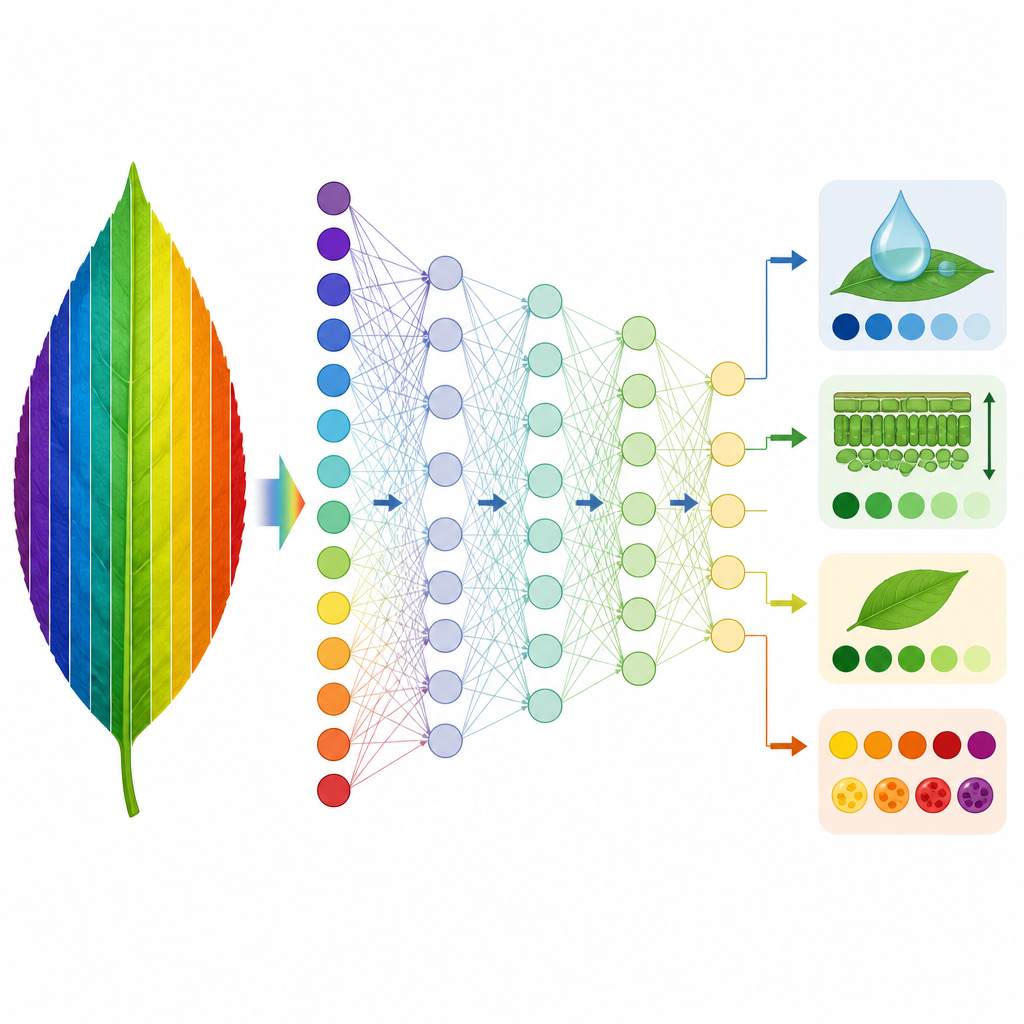
Insegnare alle macchine a sostituire la fisica
Con questa base, i ricercatori hanno addestrato due tipi di modelli guidati dai dati per imitare PROSPECT D. Innanzitutto hanno utilizzato un metodo chiamato regressione PLS (partial least squares) per apprendere il legame tra spettri simulati e i tratti fogliari che PROSPECT D aveva inferito. I modelli addestrati su una specie sono stati poi testati su altre. Per quattro tratti legati a struttura fogliare, clorofilla, acqua e massa secca, questi modelli si sono trasferiti molto bene tra la maggior parte dei set di dati, soprattutto quando addestrati sulle raccolte più diverse di specie. Due tratti pigmentari, associati a carotenoidi e antociani, si sono rivelati più difficili da predire in modo affidabile tra le specie, probabilmente perché le loro firme spettrali sono deboli e si sovrappongono a quelle della clorofilla. In secondo luogo, il team ha addestrato reti neurali profonde direttamente sugli spettri misurati per predire gli stessi tratti, creando un surrogato veloce per l’esecuzione completa dell’inversione basata sulla fisica.
Un percorso più veloce dagli spettri ai tratti
Le reti neurali addestrate su due collezioni vegetali diverse sono state in grado di recuperare quattro tratti fogliari fondamentali da spettri misurati con un’accuratezza vicina a quella di PROSPECT D, ma in una frazione del tempo di calcolo. Un metodo di interpretabilità ha mostrato che queste reti tendono naturalmente a sottopesare le bande di lunghezza d’onda rumorose dove PROSPECT D si comporta peggio, e a fare invece affidamento sulle regioni spettrali in cui modello e misure concordano. Sebbene due tratti pigmentari rimangano sfidanti, lo studio fornisce uno strumento pratico e trasferibile per stimare le proprietà chiave delle foglie dalla riflettanza iperspettrale e un quadro generale per individuare e correggere i punti deboli dei modelli fisici delle foglie vegetali.
Citazione: Rahimi-Majd, M., Xu, R., Bauermeister, S. et al. Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species. Sci Rep 16, 15602 (2026). https://doi.org/10.1038/s41598-026-53899-1
Parole chiave: riflettanza fogliare iperspettrale, PROSPECT-D, surrogato di apprendimento automatico, stima dei tratti fogliari, fenotipizzazione delle piante