Clear Sky Science · en
Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species
Why measuring leaf light matters
Farmers, ecologists, and plant breeders all want to know how healthy a plant is, how much water it holds, and how much of its leaf area is devoted to photosynthesis. Traditionally, answering these questions means cutting leaves and running careful chemical tests. This study shows how detailed measurements of the light reflected from leaves, combined with smart computer models, can estimate many of these hidden leaf properties quickly and without harm, and do so across very different plant species.
Reading plant health from reflected light
Every leaf reflects and absorbs sunlight in a pattern that depends on its pigments, internal structure, and water content. Modern instruments can measure this pattern at hundreds of very narrow colors, creating what is called a hyperspectral fingerprint. Researchers have long used either purely statistical tools or physics based models to link these fingerprints to leaf traits. The PROSPECT family of models belongs to the physics based side, describing how light travels through the layers of a leaf. It can predict what a leaf’s reflectance spectrum should look like if you know its traits and, in principle, can be run in reverse to estimate those traits from measured spectra.
Testing a trusted model across many plants
The team set out to test how well the latest version, PROSPECT D, works across a broad range of species and growing conditions, and to build faster shortcuts to it using machine learning. They assembled nine large data sets containing more than seven thousand leaf spectra from maize, sorghum, soybean, camelina, tropical trees, mixed crops, and diverse woody and herbaceous plants. For each measured spectrum, they first let PROSPECT D run in reverse to infer six key leaf traits, such as pigment levels, water content, and dry mass per area. They then ran the model forward with these inferred traits to create a synthetic spectrum that should match the measured one if the model is accurate.
Where the physics model struggles and why
By comparing measured and simulated spectra at each wavelength, the authors found that PROSPECT D reproduced leaf reflectance extremely well across most of the visible and infrared range. The main mismatches appeared only in four narrow color bands where leaves reflect very little light. An analysis of maize grown over two years showed that reflectance in these troublesome bands is strongly driven by shifting field conditions rather than genetics, suggesting that measurement noise and environmental effects dominate there. When the team repeated the reverse and forward steps starting from the synthetic spectra instead of the measured ones, the match was nearly perfect, which indicates that the inversion procedure itself is very accurate when the data fall within the model’s comfort zone.
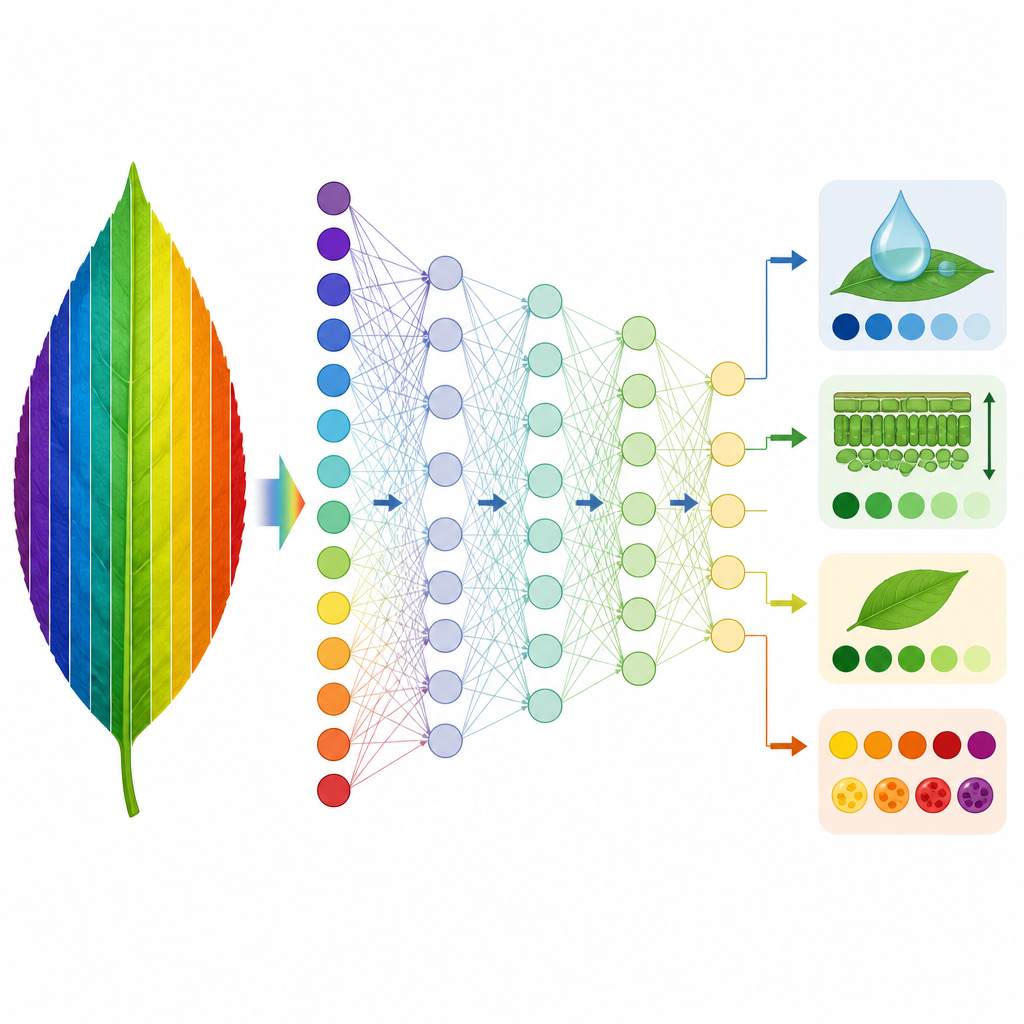
Teaching machines to stand in for physics
With this foundation, the researchers trained two kinds of data driven models to mimic PROSPECT D. First, they used a method called partial least squares regression to learn the link between simulated spectra and the leaf traits that PROSPECT D had inferred. Models trained on one species were then tested on others. For four traits related to leaf structure, chlorophyll, water, and dry mass, these models transferred very well between most data sets, especially when trained on the most diverse collections of species. Two pigment traits, tied to carotenoids and anthocyanins, proved harder to predict reliably across species, likely because their spectral signatures are weak and overlap with those of chlorophyll. Second, the team trained deep neural networks directly on measured spectra to predict the same traits, creating a fast surrogate for running the full physics based inversion.
A faster path from spectra to traits
Neural networks trained on two diverse plant collections were able to recover four core leaf traits from measured spectra with accuracy close to that of PROSPECT D, but in a fraction of the computing time. An interpretability method showed that these networks naturally downplayed the noisy wavelength bands where PROSPECT D performs poorly, and instead relied on spectral regions where the model and measurements agree. While two pigment traits remain challenging, the study delivers a practical, transferable tool for estimating key leaf properties from hyperspectral reflectance and a general framework for spotting and correcting weaknesses in physics based models of plant leaves.
Citation: Rahimi-Majd, M., Xu, R., Bauermeister, S. et al. Machine learning surrogate for the leaf PROSPECT-D model and its applications across plant species. Sci Rep 16, 15602 (2026). https://doi.org/10.1038/s41598-026-53899-1
Keywords: leaf hyperspectral reflectance, PROSPECT-D, machine learning surrogate, leaf trait estimation, plant phenotyping