Clear Sky Science · ru
Визуальные алгоритмы на основе глубокого обучения для распознавания личности и действий в практических инженерных курсах
Наблюдение за тем, кто что делает на практических занятиях
Во многих инженерных лабораториях студенты перемещаются, подключают провода, пишут код и проверяют телефоны. Преподавателям трудно понимать, кто выполняет какую задачу, а для компьютерных систем такая оживлённая сцена ещё сложнее для анализа. В этом исследовании предлагается система искусственного интеллекта, которая может надёжно распознавать как личность студента, так и простые действия в реальной учебной лаборатории, даже когда люди отворачиваются от камеры или меняют позу.
Почему обычных проверок лиц недостаточно
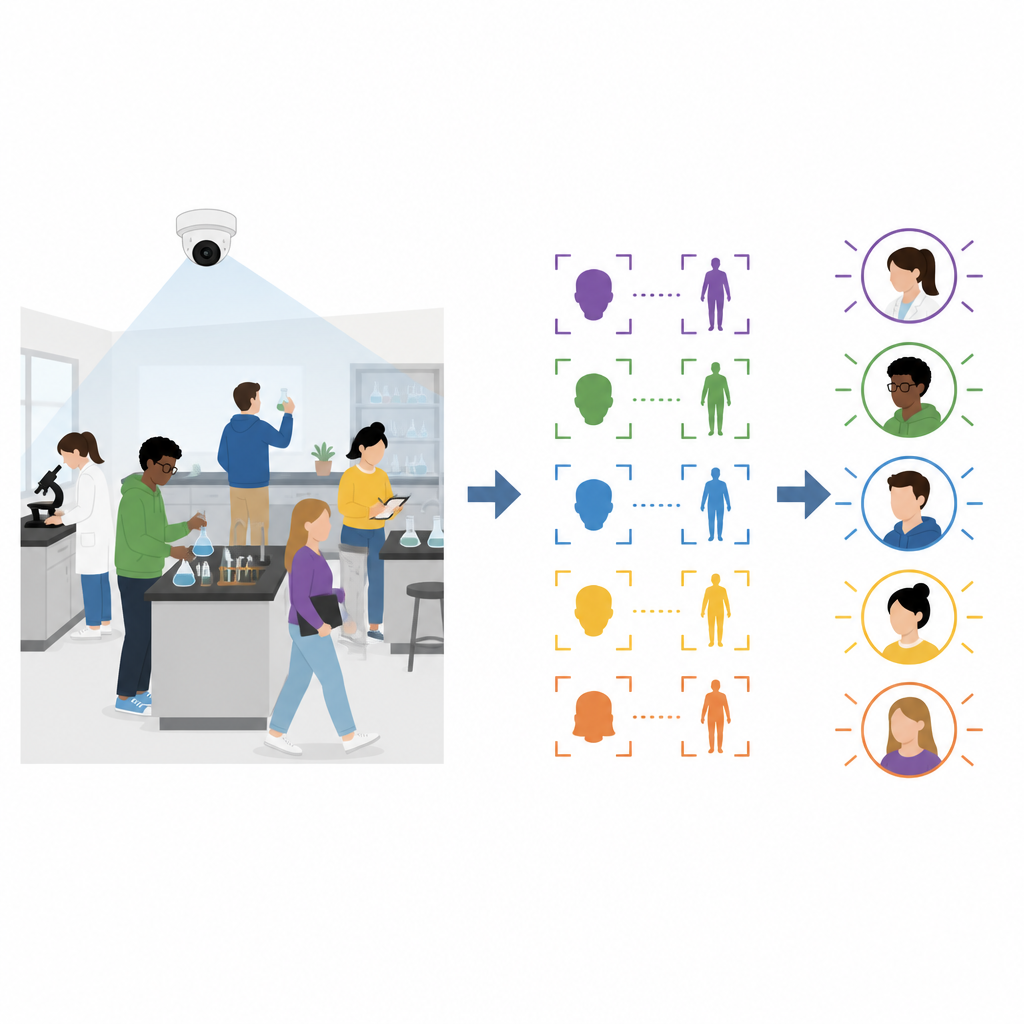
Современное распознавание лиц работает хорошо, когда люди сидят неподвижно и смотрят в камеру, как в лекционном зале или на пункте контроля. На практических инженерных занятиях студенты сгибаются над столами, поворачивают голову и ходят вокруг оборудования. В таких условиях стандартное распознавание лиц часто теряет след, поскольку оно опирается на чёткие фронтальные виды. Методы повторной идентификации по внешнему виду тела сталкиваются с похожими трудностями, ведь форма тела и одежда выглядят очень по-разному, когда студент наклоняется, поворачивается или перемещается по комнате.
Смешение лиц, тел и движения
Авторы предлагают архитектуру, которая объединяет информацию как из изображений лица, так и из изображений верхней части тела, и постоянно обновляет накопленные данные в ходе занятия. До начала занятия каждый студент предоставляет системе школы чёткое фронтальное фото. В начале сессии студенты входят в систему, посмотрев в камеру, находясь в лаборатории. Система сопоставляет их лица с сохранёнными фотографиями и одновременно сохраняет изображение тела для каждого вошедшего пользователя. Эти начальные признаки лица и тела служат отправной точкой для последующего отслеживания всех участников занятия.
Создание «живой» памяти о каждом студенте
После начала практики система анализирует видео примерно с частотой десять-пятнадцать кадров в секунду. Для каждого кадра она обнаруживает лица и тела и извлекает компактные числовые описания каждого объекта. Если лицо в текущем кадре совпадает с сохранённым образцом, но совпадение тела слабое, система считает лицо надёжным и добавляет новый вид тела в динамическую библиотеку тел. В других ситуациях, когда тело совпадает хорошо и его положение меняется незначительно между кадрами, в то время как лицо временно отсутствует, система трактует это как кратковременный поворот головы и добавляет новый вид лица в динамическую библиотеку лиц. Со временем каждый студент представлен множеством примеров лица и тела под разными углами, масштабами и освещением, что значительно повышает надёжность распознавания в последующих кадрах.
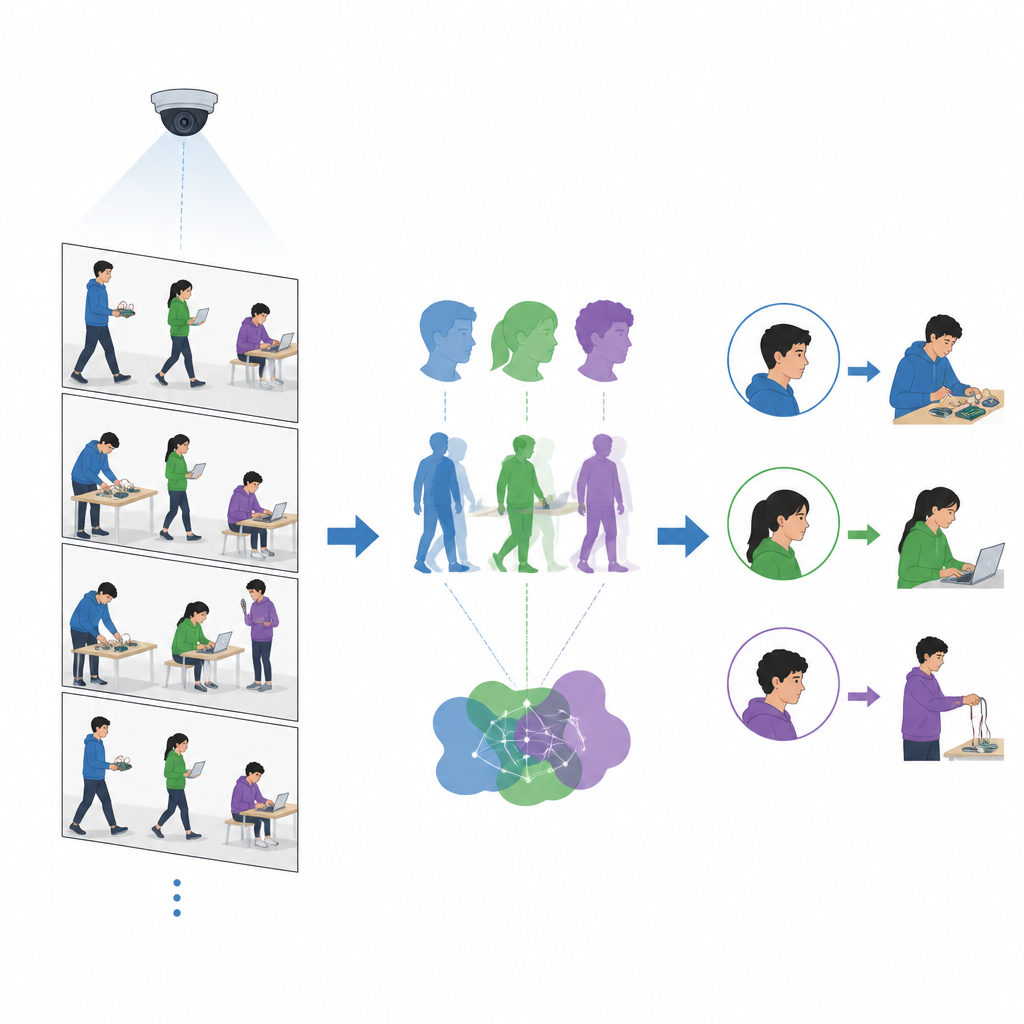
Обучение компьютера замечать простые действия
Кроме знания того, кто находится в комнате, преподавателей интересует, чем заняты студенты. Исследователи добавили компонент распознавания поведения, сосредоточенный на нескольких ключевых лабораторных действиях, таких как программирование за ноутбуком, подключение проводов или использование телефона. Отдельный инструмент рисует на людях скелетоподобные палочные модели, фиксируя расположение головы, торса и конечностей. Команда затем обучает лёгкий классификатор изображений различать эти позы, основанные на скелете. Поскольку модель анализирует упрощённые контуры вместо полноценных изображений, она способна обрабатывать более двадцати кадров в секунду — достаточно быстро, чтобы успевать за типичными камерами в аудитории.
Испытание системы в реальной лаборатории
Фреймворк был оценён в курсе по управлению серводвигателем с участием шести студентов, выполнявших задания, такие как монтаж проводки, сброс двигателя в нулевое положение и написание программ движения. Авторы сравнили три варианта: только распознавание лиц, только повторная идентификация по телу и их комбинированный динамический метод. В период входа в систему и на протяжении практической сессии комбинированный подход явно превзошёл другие два, демонстрируя более высокую точность и лучшие общие показатели при определении того, какой студент появляется в каждом кадре видео. Для модуля распознавания действий точность варьировала от примерно двух третьих для программирования до более чем четырёх пятых для использования телефона, несмотря на относительно небольшой обучающий набор.
Что это значит для будущих аудиторий
Для неискушённого читателя основной вывод в том, что исследование демонстрирует: объединение разных визуальных сигналов и их обновление с течением времени помогают компьютерным системам отслеживать, кто есть кто в оживлённой учебной лаборатории, а также распознавать несколько простых видов поведения. Система по-прежнему испытывает трудности с сильными боковыми видами лица и с полным разнообразием движений студентов, но авторы описывают пути улучшения с помощью трёхмерных моделей лиц и более богатых обучающих данных. Они также подчёркивают необходимость мер по защите приватности, например хранить только наиболее необходимые признаки и шифровать исходные изображения. В совокупности эти идеи указывают на лабораторную среду, где компьютеры незаметно помогают преподавателям, контролируя участие и активность, не вмешиваясь в практический учебный процесс.
Цитирование: Ma, J., Wang, R. & Lan, W. Deep learning-based visual algorithms for identity and action recognition in engineering practical courses. Sci Rep 16, 15524 (2026). https://doi.org/10.1038/s41598-026-45964-6
Ключевые слова: мониторинг студентов, распознавание лиц, распознавание действий, инженерное образование, компьютерное зрение