Clear Sky Science · pt
Algoritmos visuais baseados em deep learning para reconhecimento de identidade e ações em disciplinas práticas de engenharia
Observando quem faz o quê em aulas práticas
Em muitos laboratórios de engenharia, os estudantes circulam conectando fios, digitando código e checando seus telefones. Para os professores, é difícil saber quem está executando cada tarefa, e para os computadores essa cena movimentada é ainda mais difícil de interpretar. Este estudo introduz um sistema de inteligência artificial que consegue reconhecer de forma confiável tanto a identidade dos estudantes quanto ações simples em um laboratório real de ensino, mesmo quando as pessoas viram o rosto para longe da câmera ou mudam de posição.
Por que verificações faciais regulares não bastam
O reconhecimento facial moderno funciona bem quando as pessoas ficam paradas e olham para a câmera, como em uma sala de aula ou em um portão de segurança. Em disciplinas práticas de engenharia, no entanto, os estudantes se inclinam sobre mesas, viram a cabeça e caminham entre equipamentos. Nestas condições, o reconhecimento facial padrão frequentemente perde o rastro das pessoas porque depende de vistas frontais claras. Métodos de reidentificação de pessoas que focam na aparência do corpo têm problemas semelhantes, já que a forma do corpo e as roupas parecem muito diferentes quando os estudantes se inclinam, giram ou se movem pela sala.
Combinando rostos, corpos e movimento
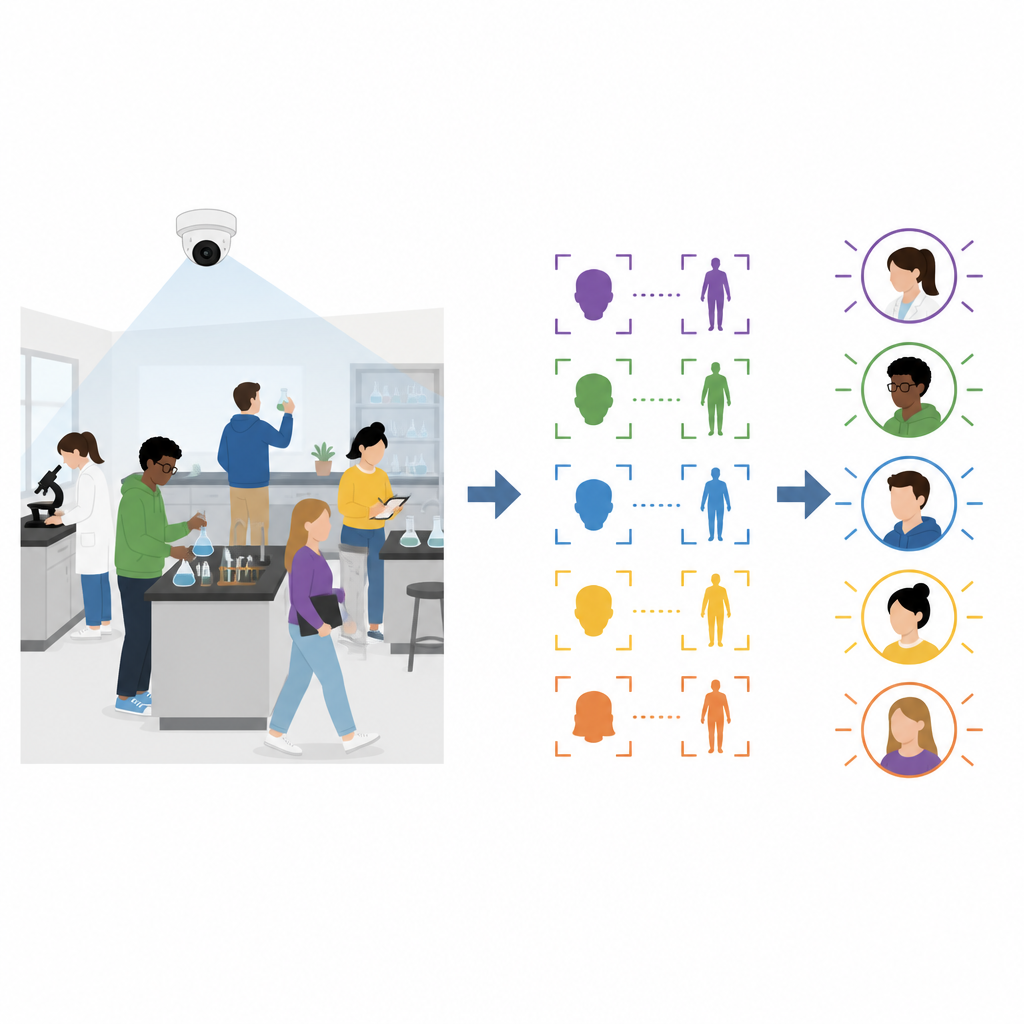
Os autores propõem uma estrutura que combina informações de imagens do rosto e da parte superior do corpo e vai atualizando o que sabe à medida que a aula se desenrola. Antes da aula, cada estudante fornece uma foto clara de frente ao sistema da escola. No início da sessão, os estudantes fazem login olhando para a câmera enquanto estão em pé no laboratório. O sistema compara seus rostos com as fotos armazenadas e, ao mesmo tempo, registra uma imagem do corpo para cada pessoa autenticada. Esses recursos iniciais de rosto e corpo formam o ponto de partida para rastrear todos durante a aula.
Construindo uma memória viva de cada estudante
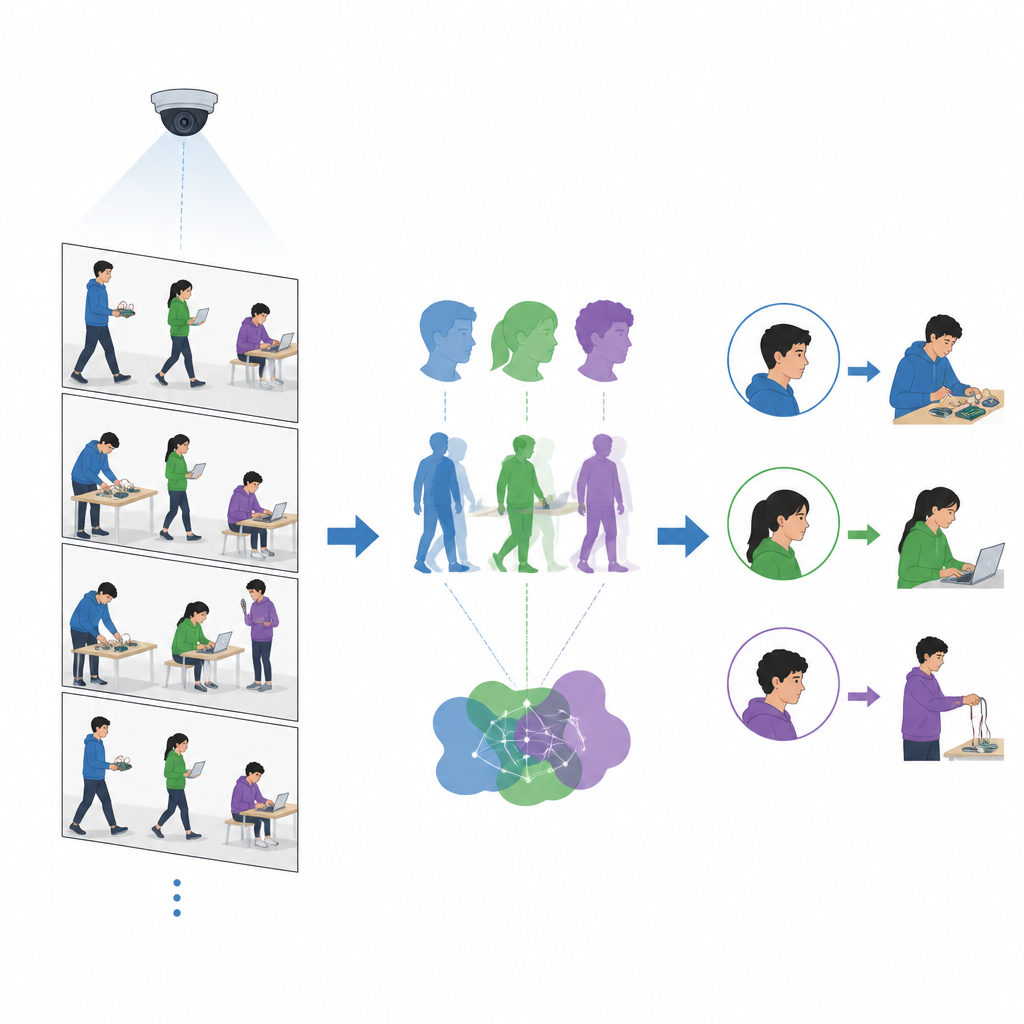
Uma vez que a aula prática começa, o sistema analisa o vídeo a cerca de dez a quinze quadros por segundo. Para cada quadro, ele detecta rostos e corpos e extrai descrições numéricas compactas de cada um. Se um rosto no quadro atual corresponder ao rosto registrado, mas a correspondência do corpo for ruim, o sistema assume que o rosto é confiável e adiciona a nova vista do corpo a uma biblioteca dinâmica de corpos. Em outras situações, quando um corpo corresponde bem e sua posição muda apenas levemente entre quadros enquanto o rosto está brevemente ausente, o sistema trata isso como uma rápida virada de cabeça e adiciona a nova vista do rosto a uma biblioteca dinâmica de rostos. Ao longo do tempo, cada estudante passa a ser representado por muitos exemplos de seu rosto e corpo sob diferentes ângulos, escalas e condições de iluminação, o que torna o reconhecimento em quadros posteriores muito mais robusto.
Ensinando o computador a notar ações simples
Além de saber quem está na sala, os instrutores também se preocupam com o que os estudantes estão fazendo. Os pesquisadores adicionam um componente de reconhecimento de comportamento que foca em algumas atividades-chave do laboratório, como programar em um laptop, conectar fios ou usar um telefone. Uma ferramenta separada desenha esqueletos em estilo figura de palito sobre os corpos, capturando a disposição da cabeça, do tronco e dos membros. A equipe então treina um classificador de imagens leve para distinguir essas poses baseadas em esqueleto. Como esse modelo analisa contornos simplificados em vez de imagens completas, ele pode processar mais de vinte quadros de vídeo por segundo, rápido o suficiente para acompanhar câmeras típicas de sala de aula.
Testando o sistema em um laboratório real
A estrutura foi avaliada em um curso de controle de motor de servo com seis estudantes trabalhando em tarefas como fiação de componentes, resetar um motor para sua origem e escrever programas de movimento. Os autores compararam três opções: apenas reconhecimento facial, apenas reidentificação baseada no corpo e seu método dinâmico combinado. Durante o período de login e ao longo da sessão prática, a abordagem combinada superou claramente as outras duas, alcançando maior precisão e melhores resultados gerais ao decidir qual estudante aparecia em cada quadro de vídeo. Para o módulo de ação, a acurácia do reconhecimento variou de cerca de dois terços para programação até mais de quatro quintos para uso de telefone, apesar do uso de um conjunto de treinamento relativamente pequeno.
O que isso significa para salas de aula futuras
Para um leitor leigo, a mensagem principal é que o estudo mostra como fundir diferentes pistas visuais e atualizá‑las ao longo do tempo pode ajudar computadores a acompanhar quem é quem em um laboratório de ensino movimentado, ao mesmo tempo em que reconhece alguns comportamentos simples. O sistema ainda tem dificuldades com vistas laterais acentuadas do rosto e com a variedade completa de movimentos dos estudantes, mas os autores descrevem formas de melhorá‑lo usando modelos faciais tridimensionais e dados de treinamento mais ricos. Eles também ressaltam a necessidade de salvaguardas de privacidade, como armazenar apenas os recursos estritamente necessários e criptografar imagens originais. Em conjunto, essas ideias apontam para ambientes de laboratório onde computadores apoiam discretamente os professores monitorando participação e atividade sem interromper o aprendizado prático.
Citação: Ma, J., Wang, R. & Lan, W. Deep learning-based visual algorithms for identity and action recognition in engineering practical courses. Sci Rep 16, 15524 (2026). https://doi.org/10.1038/s41598-026-45964-6
Palavras-chave: monitoramento de estudantes, reconhecimento facial, reconhecimento de ações, educação em engenharia, visão computacional