Clear Sky Science · pl
Algorytmy wizualne oparte na uczeniu głębokim do rozpoznawania tożsamości i czynności w zajęciach praktycznych inżynierskich
Obserwowanie, kto co robi na zajęciach praktycznych
W wielu laboratoriach inżynierskich studenci przemieszczają się, podłączają przewody, piszą kod i sprawdzają telefony. Dla wykładowców trudno jest wiedzieć, kto wykonuje jakie zadanie, a dla komputerów taka zatłoczona scena jest jeszcze trudniejsza do odczytania. W tym badaniu wprowadzono system sztucznej inteligencji, który potrafi niezawodnie rozpoznawać zarówno tożsamość studentów, jak i proste czynności w rzeczywistym laboratorium dydaktycznym, nawet gdy osoby odwracają się od kamery lub zmieniają pozycję.
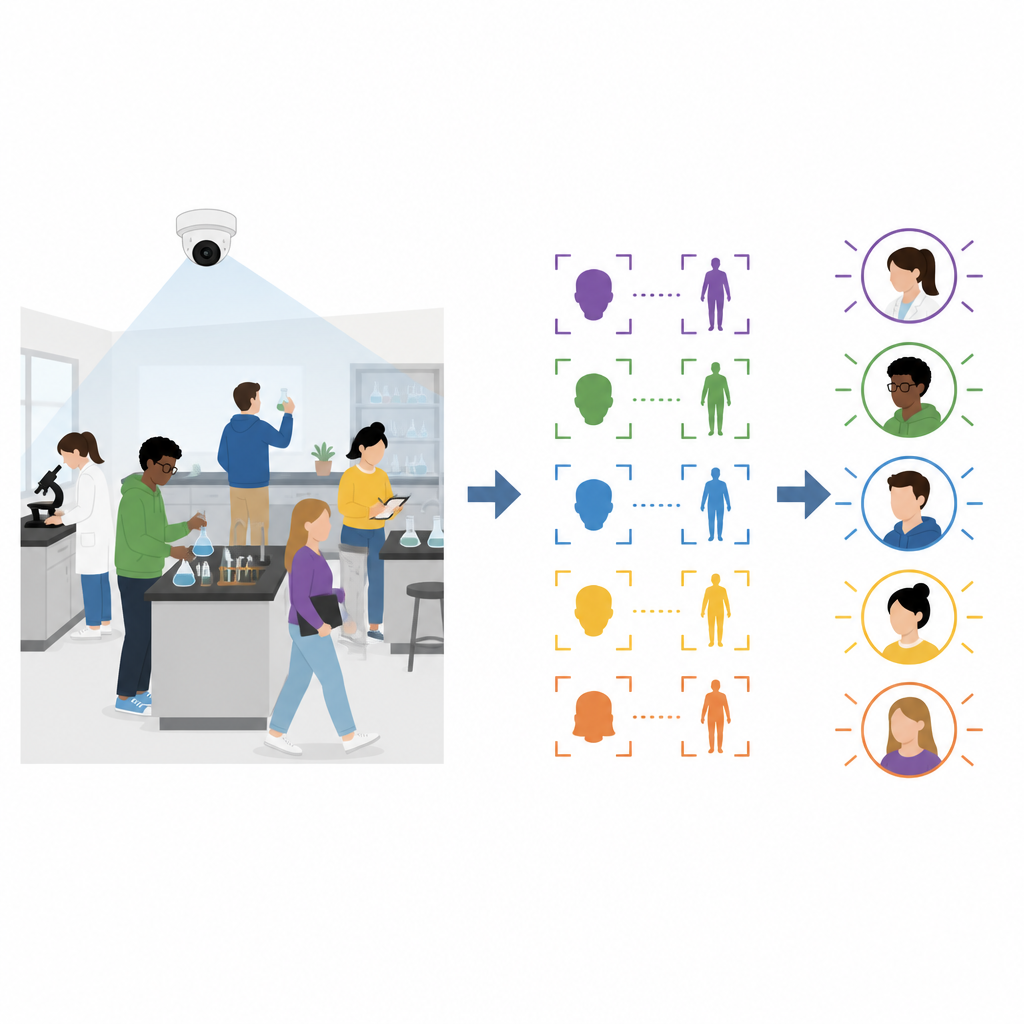
Dlaczego zwykłe kontrole twarzy to za mało
Nowoczesne rozpoznawanie twarzy działa dobrze, gdy ludzie siedzą nieruchomo i patrzą w kierunku kamery, jak na wykładzie czy przy bramce bezpieczeństwa. W kursach praktycznych studenci jednak pochylają się nad stołami, odwracają głowy i chodzą po pomieszczeniu. W takich warunkach standardowe rozpoznawanie twarzy często traci ślad osób, ponieważ opiera się na wyraźnych, frontalnych ujęciach. Metody re-identyfikacji osób koncentrujące się na wyglądzie całego ciała mają podobne problemy, ponieważ kształt ciała i ubrania wyglądają bardzo różnie, gdy studenci pochylają się, obracają lub przemieszczają po sali.
Mieszanie informacji z twarzy, ciała i ruchu
Autorzy proponują ramy działania, które łączą informacje z obrazów twarzy i górnej części ciała oraz stale aktualizują zgromadzone dane w miarę trwania zajęć. Przed zajęciami każdy student przesyła do systemu szkoły wyraźne, frontalne zdjęcie. Na początku sesji studenci logują się, patrząc w kamerę stojąc w laboratorium. System dopasowuje ich twarze do zapisanych zdjęć i równocześnie rejestruje obraz sylwetki dla każdej zalogowanej osoby. Te początkowe cechy twarzy i ciała stanowią punkt wyjścia do późniejszego śledzenia wszystkich uczestników zajęć.
Budowanie żywej pamięci o każdym studencie
Gdy zajęcia praktyczne się rozpoczynają, system analizuje wideo z szybkością około dziesięciu do piętnastu klatek na sekundę. Dla każdej klatki wykrywa twarze i sylwetki oraz wydobywa zwarte numeryczne opisy każdej z nich. Jeśli twarz w bieżącej klatce pasuje do tej w bazie, ale dopasowanie sylwetki jest słabe, system uznaje, że twarz jest wiarygodna i dodaje nowe ujęcie sylwetki do dynamicznej biblioteki ciał. W innych sytuacjach, gdy sylwetka pasuje dobrze, a jej pozycja zmienia się tylko nieznacznie między klatkami, podczas gdy twarz jest chwilowo nieobecna, system traktuje to jako szybki obrót głowy i dodaje nowe ujęcie twarzy do dynamicznej biblioteki twarzy. Z czasem każdy student jest reprezentowany przez wiele przykładów twarzy i ciała pod różnymi kątami, skalami i warunkami oświetleniowymi, co sprawia, że rozpoznawanie w kolejnych klatkach jest znacznie bardziej niezawodne.
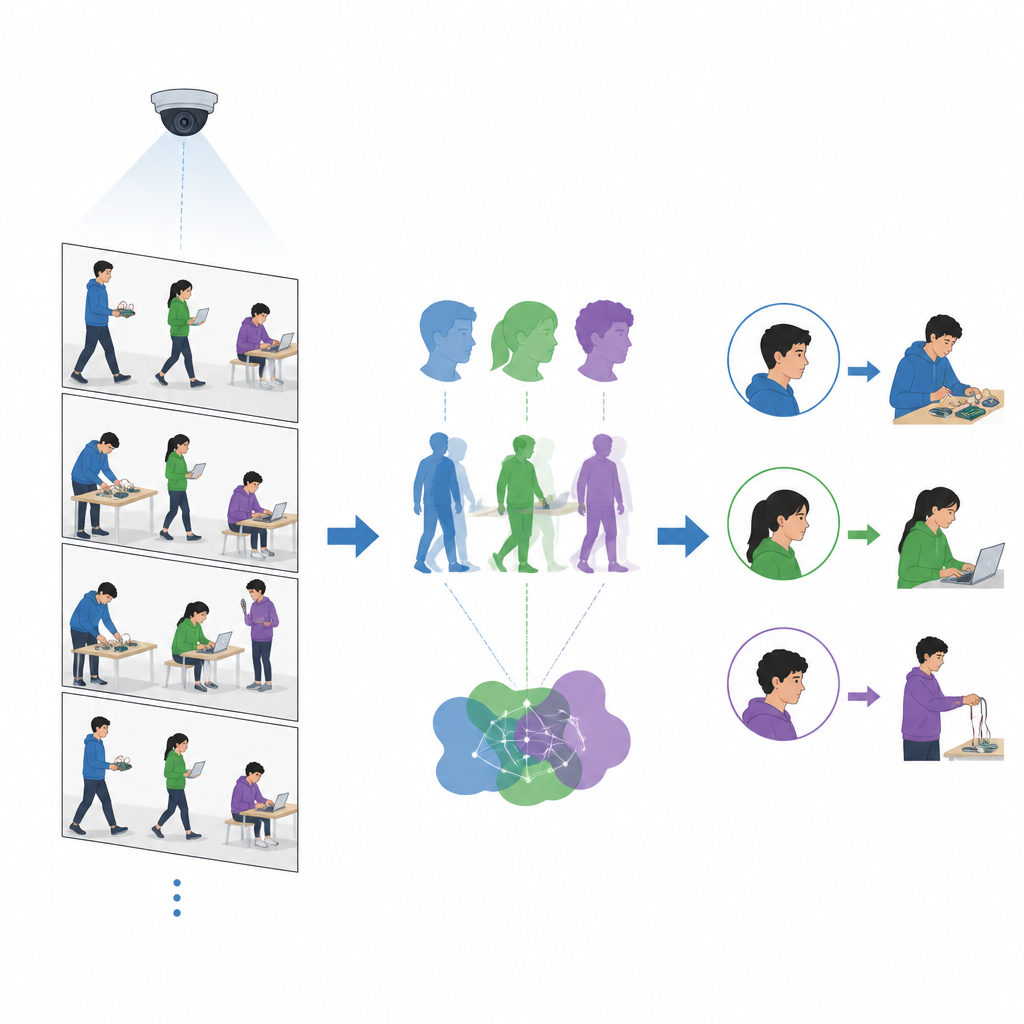
Nauczanie komputera rozpoznawania prostych czynności
Poza znajomością tego, kto przebywa w pomieszczeniu, wykładowcy interesują się też, co studenci robią. Badacze dodali komponent rozpoznawania zachowań, który koncentruje się na kilku kluczowych aktywnościach laboratoryjnych, takich jak programowanie przy laptopie, podłączanie przewodów czy korzystanie z telefonu. Osobne narzędzie nakłada na sylwetki ludzi szkielety przypominające patyczakowe rysunki, uchwytując ułożenie głowy, tułowia i kończyn. Zespół następnie szkoli lekki klasyfikator obrazów, aby rozróżniał te sylwetkowe pozy. Ponieważ model analizuje uproszczone zarysy zamiast pełnych obrazów, potrafi przetwarzać ponad dwadzieścia klatek wideo na sekundę — wystarczająco szybko, by nadążyć za typowymi kamerami klasowymi.
Testowanie systemu w rzeczywistym laboratorium
Ramy oceniono na kursie sterowania silnikiem serwo, w którym sześciu studentów pracowało nad zadaniami takimi jak okablowanie komponentów, resetowanie silnika do pozycji zerowej czy pisanie programów ruchu. Autorzy porównali trzy opcje: samo rozpoznawanie twarzy, tylko re-identyfikację opartą na ciele oraz ich połączoną, dynamiczną metodę. W czasie logowania i przez cały okres zajęć podejście łączone wyraźnie przewyższało pozostałe dwie opcje, osiągając wyższą precyzję i lepsze ogólne wyniki przy ustalaniu, który student pojawił się w każdej klatce wideo. W module rozpoznawania czynności dokładność wahała się od około dwóch trzecich dla programowania do ponad czterech piątych dla korzystania z telefonu, mimo użycia stosunkowo niewielkiego zbioru treningowego.
Co to oznacza dla przyszłych sal wykładowych
Dla laika główne przesłanie jest takie, że badanie pokazuje, jak łączenie różnych wskazówek wizualnych i ich aktualizowanie w czasie może pomóc komputerom śledzić, kto jest kim w zatłoczonym laboratorium dydaktycznym, jednocześnie rozpoznając kilka prostych zachowań. System wciąż ma problemy z mocnymi bocznymi widokami twarzy i z pełną gamą ruchów studentów, ale autorzy wskazują sposoby poprawy, wykorzystując trójwymiarowe modele twarzy i bogatsze dane treningowe. Podkreślają też potrzebę zabezpieczeń prywatności, takich jak przechowywanie tylko niezbędnych cech i szyfrowanie oryginalnych obrazów. Razem te pomysły wskazują kierunek ku środowiskom laboratoryjnym, w których komputery dyskretnie wspierają wykładowców, monitorując udział i aktywność bez zakłócania nauki praktycznej.
Cytowanie: Ma, J., Wang, R. & Lan, W. Deep learning-based visual algorithms for identity and action recognition in engineering practical courses. Sci Rep 16, 15524 (2026). https://doi.org/10.1038/s41598-026-45964-6
Słowa kluczowe: monitorowanie studentów, rozpoznawanie twarzy, rozpoznawanie czynności, edukacja inżynierska, widzenie komputerowe