Clear Sky Science · ar
خوارزميات بصرية معتمدة على التعلم العميق للتعرّف على الهوية والأفعال في مقررات هندسية عملية
مراقبة من يفعل ماذا في الحصص العملية
في العديد من مختبرات الهندسة، يتحرك الطلاب حول الطاولات لربط الأسلاك وكتابة الشيفرات وفحص هواتفهم. بالنسبة للمدرّسين، من الصعب معرفة من يقوم بأي مهمة، ولأجهزة الكمبيوتر يكون هذا المشهد المشغول أصعب في الفهم. تقدّم هذه الدراسة نظام ذكاء اصطناعي قادرًا على التعرّف بموثوقية على كل من هوية الطالب والأفعال البسيطة في مختبر تعليمي حقيقي، حتى عندما يدير الأشخاص ظهورهم للكاميرا أو يغيّرون وضعيتهم.
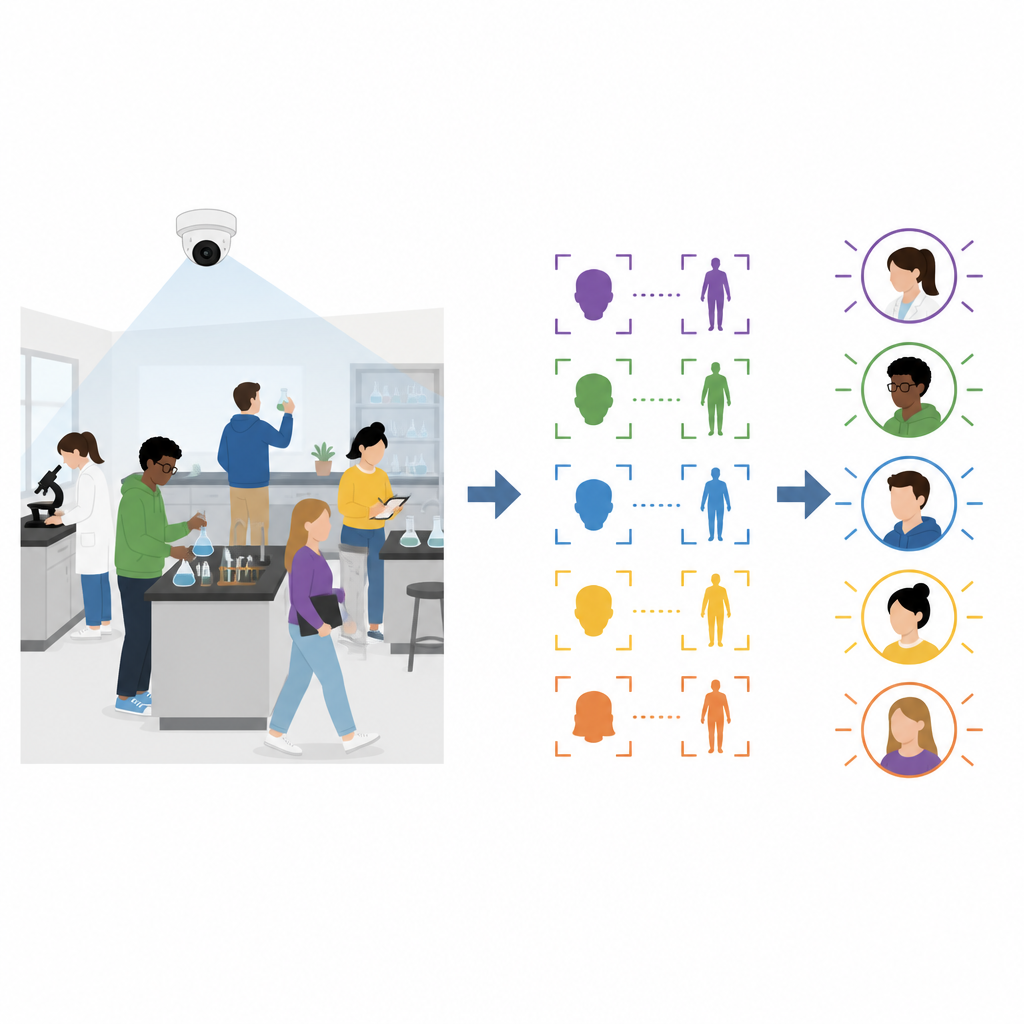
لماذا فحوصات الوجوه الاعتيادية لا تكفي
يعمل التعرّف على الوجوه الحديث جيدًا عندما يجلس الأشخاص ساكنين وينظرون نحو الكاميرا، كما في قاعة محاضرات أو عند بوابة أمنية. لكن في المقررات العملية الهندسية، ينحني الطلاب فوق الطاولات، ويديرون رؤوسهم، ويتنقلون بين المعدات. في هذه الظروف، غالبًا ما يفقد التعرّف على الوجوه الاعتيادي تتبّع الأشخاص لأنه يعتمد على مشاهد أمامية واضحة. طرق إعادة تعرّف الأشخاص التي تركز على مظهر الجسد الكامل تواجه مشاكل مماثلة، إذ يتغير شكل الجسم والملابس بشكل كبير عندما ينحني الطلاب أو يديرون أجسادهم أو يتحرّكون عبر الغرفة.
دمج الوجوه والأجساد والحركة
يقترح المؤلفون إطار عمل يجمع معلومات من كل من صور الوجه وجزء الجذع العلوي ويستمر في تحديث ما يعرفه مع تسلسل الحصة. قبل الحصة، يقدّم كل طالب صورة أمامية واضحة إلى نظام المدرسة. في بداية الجلسة، يسجل الطلاب دخولهم بالنظر إلى الكاميرا أثناء الوقوف في المختبر. يطابق النظام وجوههم مع الصور المخزّنة ويسجّل في الوقت نفسه صورة للجسم لكل شخص مسجّل. تشكّل ميزات الوجه والجسم الأولية هذه نقطة انطلاق لتتبّع الجميع لاحقًا في الحصة.
بناء ذاكرة حية لكل طالب
بمجرد بدء الحصة العملية، يحلل النظام الفيديو بمعدل نحو عشرة إلى خمسة عشر إطارًا في الثانية. في كل إطار، يكتشف الوجوه والأجسام ويستخرج أوصافًا عددية مضغوطة لكل منها. إذا طابقت وجهًا في الإطار الحالي الوجه المسجّل، لكن تطابق الجسم كان ضعيفًا، يفترض النظام أن الوجه موثوق ويضيف مشهد الجسم الجديد إلى مكتبة جسد ديناميكية. في حالات أخرى، عندما يتطابق الجسم جيدًا ويتغير موضعه قليلًا بين الإطارات بينما يختفي الوجه لفترة وجيزة، يتعامل النظام مع ذلك على أنه دوران سريع للرأس ويضيف مشهد الوجه الجديد إلى مكتبة وجه ديناميكية. مع مرور الوقت، يُمثّل كل طالب بالعديد من أمثلة وجهه وجسده من زوايا ومقاييس وإضاءات مختلفة، مما يجعل التعرف في الإطارات اللاحقة أكثر موثوقية بكثير.
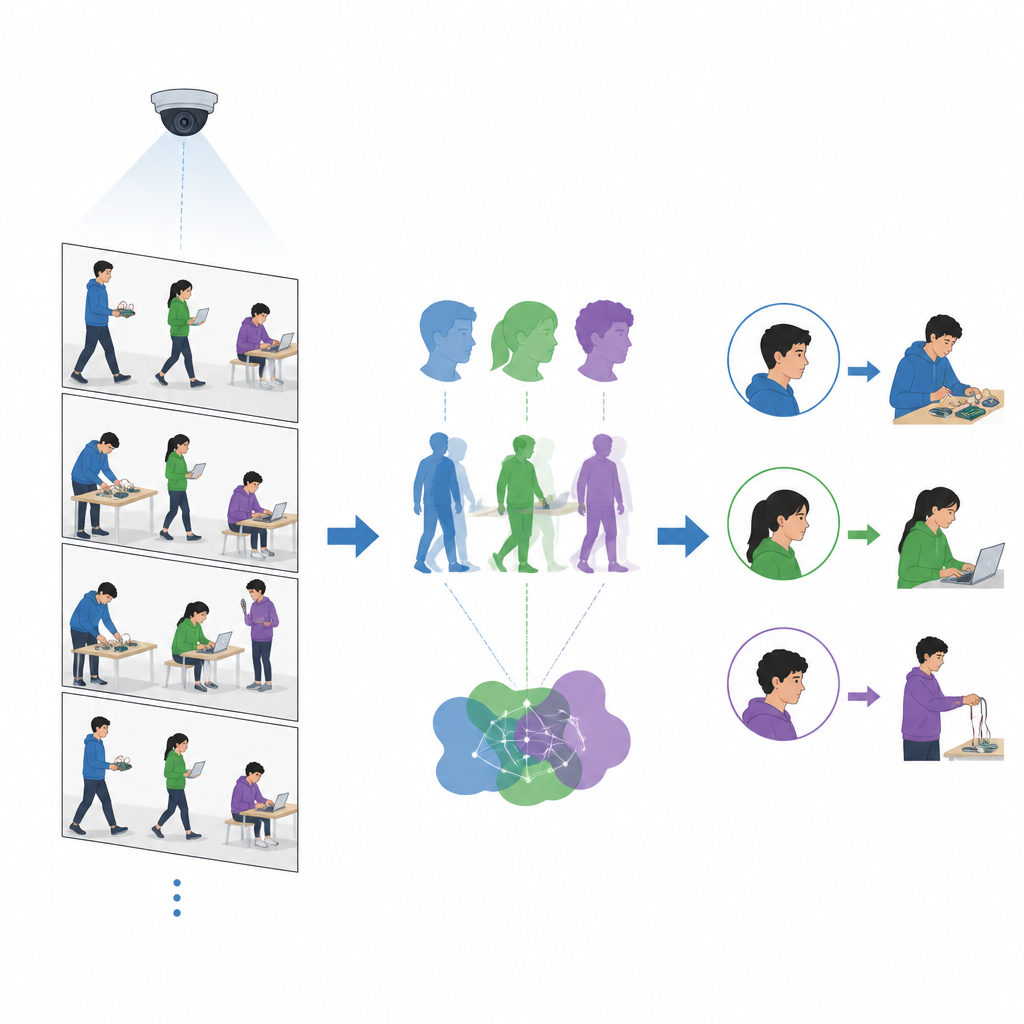
تعليم الحاسوب ملاحظة الأفعال البسيطة
إلى جانب معرفة من يتواجد في الغرفة، يهتم المدرّسون أيضًا بما يفعله الطلاب. يضيف الباحثون مكوّنًا للتعرّف على السلوك يركز على عدد قليل من أنشطة المختبر الرئيسية، مثل البرمجة على الحاسوب المحمول، ربط الأسلاك، أو استخدام الهاتف. يرسم أداة منفصلة هياكل عظمية شبيهة بعصي فوق أجساد البشر، تلتقط ترتيب الرأس والجذع والأطراف. ثم يدرب الفريق مصنّف صور خفيف الوزن لتمييز هذه الوضعيات المبنية على الهيكل العظمي. لأن هذا النموذج يحلل مخططات مبسطة بدلًا من الصور الكاملة، يمكنه معالجة أكثر من عشرين إطار فيديو في الثانية، بسرعة كافية لمجاراة كاميرات الصف النموذجية.
اختبار النظام في مختبر حقيقي
تم تقييم الإطار في دورة تحكم بمحركات سيرفو مع ستة طلاب يعملون على مهام مثل توصيل المكونات، إعادة المحرك إلى الأصل، وكتابة برامج الحركة. قارن المؤلفون بين ثلاث خيارات: التعرّف على الوجه وحده، إعادة التعرّف المعتمدة على الجسم وحدها، وطريقتهم الديناميكية المدمجة. خلال فترة تسجيل الدخول وطوال الجلسة العملية، تفوّقت المقاربة المدمجة بوضوح على الأسلوبين الآخرين، محققة دقّة أعلى ونتائج إجمالية أفضل عند تقرير أي طالب ظهر في كل إطار فيديو. بالنسبة لوحدة الأفعال، تراوحت دقة التعرّف من نحو ثلثي الحالات للبرمجة إلى أكثر من أربعة أخماس لحالات استخدام الهاتف، رغم استخدام مجموعة تدريبية صغيرة نسبيًا.
ماذا يعني هذا للصفوف المستقبلية
بالنسبة للقارئ العام، الرسالة الأساسية أن الدراسة توضح كيف أن دمج دلائل بصرية مختلفة وتحديثها عبر الزمن يمكن أن يساعد الحواسيب على تتبّع من يكون ومن يفعل ماذا في مختبر تعليمي مزدحم، مع التعرّف أيضًا على بعض السلوكيات البسيطة. لا يزال النظام يواجه صعوبات مع المشاهد الجانبية القوية للوجه ومع التنوع الكامل في حركات الطلاب، لكن المؤلفين يوضّحون طرقًا لتحسينه باستخدام نماذج وجه ثلاثية الأبعاد وبيانات تدريب أغنى. كما يؤكدون على ضرورة تدابير حماية الخصوصية، مثل تخزين الميزات الضرورية فقط وتشفير الصور الأصلية. مجتمعة، تشير هذه الأفكار إلى بيئات مختبرية حيث تدعم الحواسيب المعلمين بهدوء عبر مراقبة المشاركة والنشاط دون مقاطعة التعلم العملي.
الاستشهاد: Ma, J., Wang, R. & Lan, W. Deep learning-based visual algorithms for identity and action recognition in engineering practical courses. Sci Rep 16, 15524 (2026). https://doi.org/10.1038/s41598-026-45964-6
الكلمات المفتاحية: مراقبة الطلاب, التعرّف على الوجوه, التعرّف على الأفعال, التعليم الهندسي, رؤية الحاسوب