Clear Sky Science · it
Algoritmi visivi basati sul deep learning per il riconoscimento dell’identità e delle azioni nei corsi pratici di ingegneria
Osservare chi fa cosa nelle lezioni pratiche
In molti laboratori di ingegneria gli studenti si muovono collegando cavi, scrivendo codice e controllando i telefoni. Per gli insegnanti è difficile sapere chi sta svolgendo quale attività, e per i computer questa scena affollata è ancora più complessa da interpretare. Questo studio introduce un sistema di intelligenza artificiale in grado di riconoscere in modo affidabile sia l’identità degli studenti sia azioni semplici in un laboratorio didattico reale, anche quando le persone si voltano rispetto alla telecamera o cambiano posizione.
Perché i controlli facciali standard non bastano
Il riconoscimento facciale moderno funziona bene quando le persone sono ferme e guardano verso la telecamera, come in un’aula o a un varco di sicurezza. Nei corsi pratici di ingegneria, però, gli studenti si chinano sui tavoli, girano la testa e camminano attorno alle attrezzature. In queste condizioni il riconoscimento facciale standard spesso perde il tracciamento, poiché si basa su viste frontali nitide. Anche i metodi di re-identificazione che considerano l’aspetto del corpo intero presentano problemi simili, dato che la forma del corpo e l’abbigliamento appaiono molto diversi quando gli studenti si piegano, ruotano o si muovono nella stanza.
Fondere volti, corpi e movimento
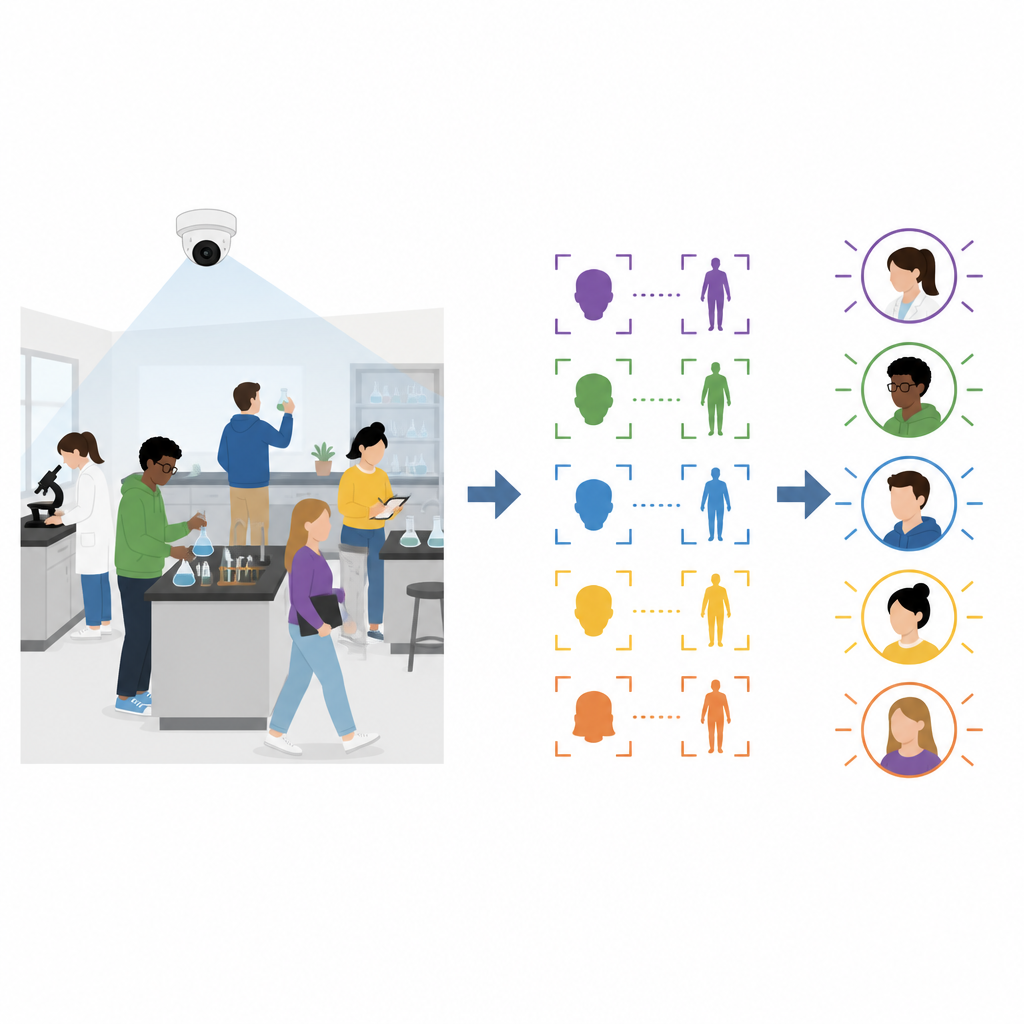
Gli autori propongono un framework che combina informazioni sia dalle immagini del volto sia dalla parte superiore del corpo e che aggiorna continuamente ciò che conosce man mano che la lezione procede. Prima del corso, ogni studente fornisce al sistema della scuola una foto frontale chiara. All’inizio della sessione gli studenti effettuano il login guardando la telecamera mentre sono in piedi nel laboratorio. Il sistema abbina i loro volti alle foto memorizzate e, contemporaneamente, registra un’immagine del corpo per ciascuna persona loggata. Queste caratteristiche iniziali del volto e del corpo costituiscono il punto di partenza per tracciare tutti durante la lezione.
Costruire una memoria vivente di ogni studente
Una volta iniziata la parte pratica, il sistema analizza il video a circa dieci-quindici fotogrammi al secondo. Per ogni fotogramma rileva volti e corpi ed estrae descrizioni numeriche compatte di ciascuno. Se un volto nel fotogramma corrente corrisponde al volto archiviato, ma la corrispondenza del corpo è scarsa, il sistema considera il volto affidabile e aggiunge la nuova vista del corpo a una libreria dinamica del corpo. In altre situazioni, quando un corpo corrisponde bene e la sua posizione cambia solo leggermente tra fotogrammi mentre il volto è temporaneamente assente, il sistema interpreta ciò come una rapida rotazione della testa e aggiunge la nuova vista del volto a una libreria dinamica del volto. Nel tempo, ogni studente è rappresentato da molti esempi del proprio volto e corpo in diverse angolazioni, scale e condizioni di illuminazione, il che rende il riconoscimento nei fotogrammi successivi molto più affidabile.
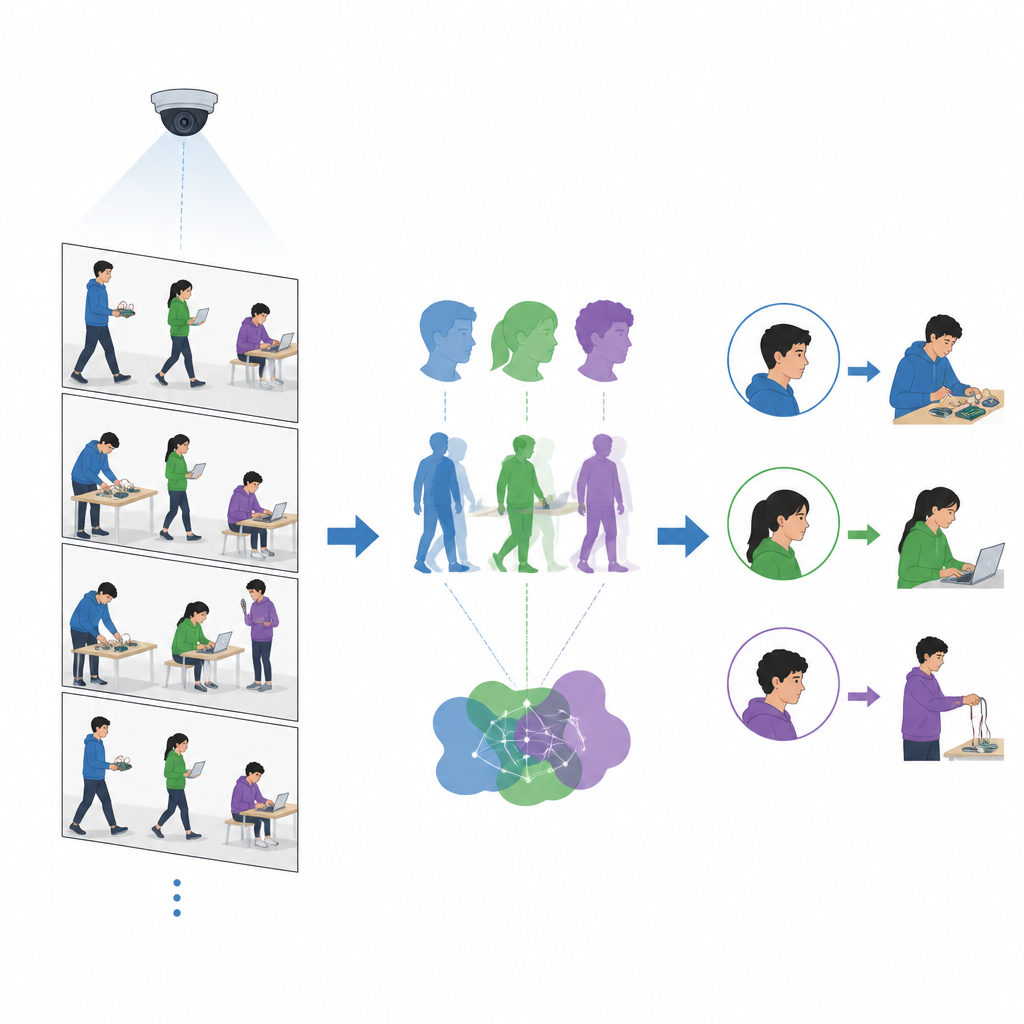
Insegnare al computer a riconoscere azioni semplici
Oltre a sapere chi è presente in aula, agli insegnanti interessa anche cosa stanno facendo gli studenti. I ricercatori aggiungono un componente di riconoscimento del comportamento che si concentra su poche attività chiave del laboratorio, come programmare al portatile, collegare cavi o usare il telefono. Uno strumento separato sovrappone scheletri semplificati alle figure umane, catturando la disposizione di testa, torso e arti. Il team poi addestra un leggero classificatore di immagini per distinguere queste pose basate sullo scheletro. Poiché questo modello analizza contorni semplificati invece di immagini complete, può elaborare oltre venti fotogrammi al secondo, abbastanza rapidamente da tenere il passo con le telecamere tipiche in aula.
Testare il sistema in un laboratorio reale
Il framework è stato valutato in un corso di controllo di motori servomeccanici con sei studenti che svolgevano attività come cablare componenti, azzerare un motore alla posizione iniziale e scrivere programmi di movimento. Gli autori hanno confrontato tre opzioni: solo riconoscimento facciale, solo re-identificazione basata sul corpo e il loro metodo dinamico combinato. Durante il periodo di login e per tutta la sessione pratica l’approccio combinato ha sovraperformato chiaramente gli altri due, raggiungendo maggiore precisione e punteggi complessivi migliori quando si doveva stabilire quale studente appariva in ciascun fotogramma video. Per il modulo delle azioni, l’accuratezza del riconoscimento variava da circa i due terzi per la programmazione a oltre quattro quinti per l’uso del telefono, nonostante l’uso di un set di addestramento relativamente piccolo.
Cosa significa per le aule del futuro
Per il lettore non specialista, il messaggio principale è che lo studio mostra come fondere diversi segnali visivi e aggiornarli nel tempo possa aiutare i computer a tenere traccia di chi è chi in un laboratorio didattico affollato, riconoscendo allo stesso tempo alcune semplici azioni. Il sistema fatica ancora con viste laterali pronunciate del volto e con l’ampia varietà di movimenti degli studenti, ma gli autori delineano modi per migliorarlo usando modelli tridimensionali del volto e dati di addestramento più ricchi. Sottolineano inoltre la necessità di garanzie per la privacy, come memorizzare solo le caratteristiche strettamente necessarie e crittografare le immagini originali. Nel complesso, queste proposte indicano ambienti di laboratorio in cui i computer supportano discretamente gli insegnanti monitorando partecipazione e attività senza interrompere l’apprendimento pratico.
Citazione: Ma, J., Wang, R. & Lan, W. Deep learning-based visual algorithms for identity and action recognition in engineering practical courses. Sci Rep 16, 15524 (2026). https://doi.org/10.1038/s41598-026-45964-6
Parole chiave: monitoraggio studenti, riconoscimento facciale, riconoscimento azioni, educazione ingegneristica, computer vision