Clear Sky Science · fr
Algorithmes visuels basés sur l’apprentissage profond pour la reconnaissance d’identité et d’action dans les cours pratiques d’ingénierie
Observer qui fait quoi dans les cours pratiques
Dans de nombreux laboratoires d’ingénierie, les étudiants se déplacent pour connecter des fils, taper du code et consulter leur téléphone. Pour les enseignant·e·s, il est difficile de savoir qui réalise quelle tâche, et pour les ordinateurs cette scène animée est encore plus difficile à interpréter. Cette étude présente un système d’intelligence artificielle capable de reconnaître de manière fiable à la fois l’identité des étudiant·e·s et des actions simples dans un véritable laboratoire d’enseignement, même lorsque les personnes tournent le dos à la caméra ou changent de position.
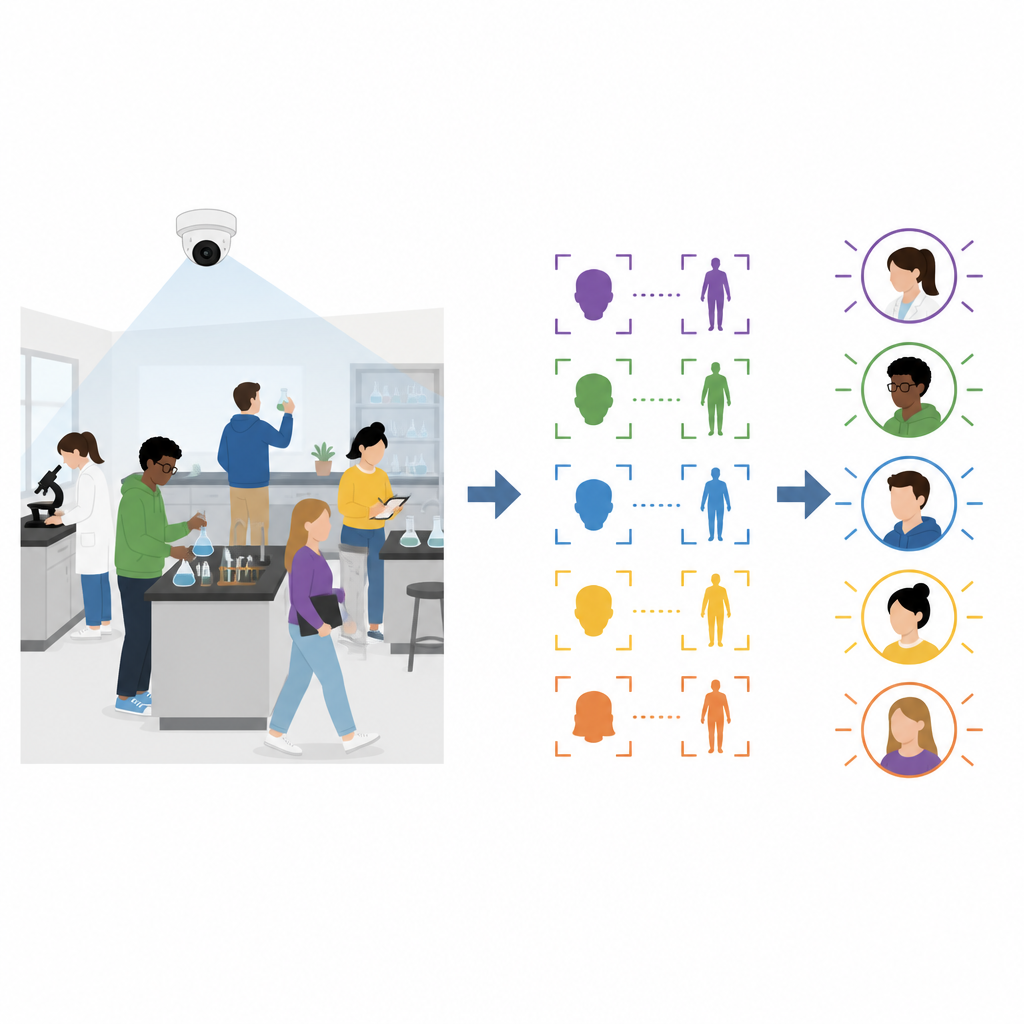
Pourquoi les contrôles faciaux classiques ne suffisent pas
La reconnaissance faciale moderne fonctionne bien lorsque les personnes restent immobiles et regardent la caméra, comme dans une amphithéâtre ou à une porte de sécurité. Dans les cours pratiques d’ingénierie, cependant, les étudiant·e·s se penchent sur les tables, tournent la tête et circulent autour des équipements. Dans ces conditions, la reconnaissance faciale standard perd souvent la trace des personnes parce qu’elle repose sur des vues frontales nettes. Les méthodes de ré-identification qui se concentrent sur l’apparence corporelle rencontrent des problèmes similaires, car la silhouette et les vêtements varient fortement quand les étudiant·e·s se penchent, tournent ou se déplacent dans la pièce.
Mêler visages, corps et mouvement
Les auteur·rice·s proposent un cadre qui combine les informations issues des images du visage et du haut du corps et met à jour en continu ce qu’il sait au fil du déroulement du cours. Avant la séance, chaque étudiant·e fournit une photo claire de face au système de l’école. Au début de la session, les étudiant·e·s se connectent en regardant la caméra depuis le laboratoire. Le système associe leurs visages aux photos enregistrées et, en parallèle, enregistre une image du corps pour chaque personne connectée. Ces caractéristiques initiales du visage et du corps constituent le point de départ pour le suivi de chacun·e durant le cours.
Construire une mémoire vivante de chaque étudiant·e
Dès que le cours pratique commence, le système analyse la vidéo à raison d’environ dix à quinze images par seconde. Pour chaque image, il détecte les visages et les corps et extrait des descriptions numériques compactes de chacun. Si un visage dans l’image courante correspond au visage enregistré, mais que la correspondance du corps est faible, le système considère le visage comme fiable et ajoute la nouvelle vue du corps à une bibliothèque dynamique du corps. Dans d’autres situations, lorsqu’un corps correspond bien et que sa position change peu d’une image à l’autre alors que le visage est momentanément absent, le système interprète cela comme un rapide mouvement de tête et ajoute la nouvelle vue du visage à une bibliothèque dynamique du visage. Au fil du temps, chaque étudiant·e est représenté·e par de nombreux exemples de son visage et de son corps sous différents angles, échelles et conditions d’éclairage, ce qui rend la reconnaissance dans les images suivantes beaucoup plus robuste.
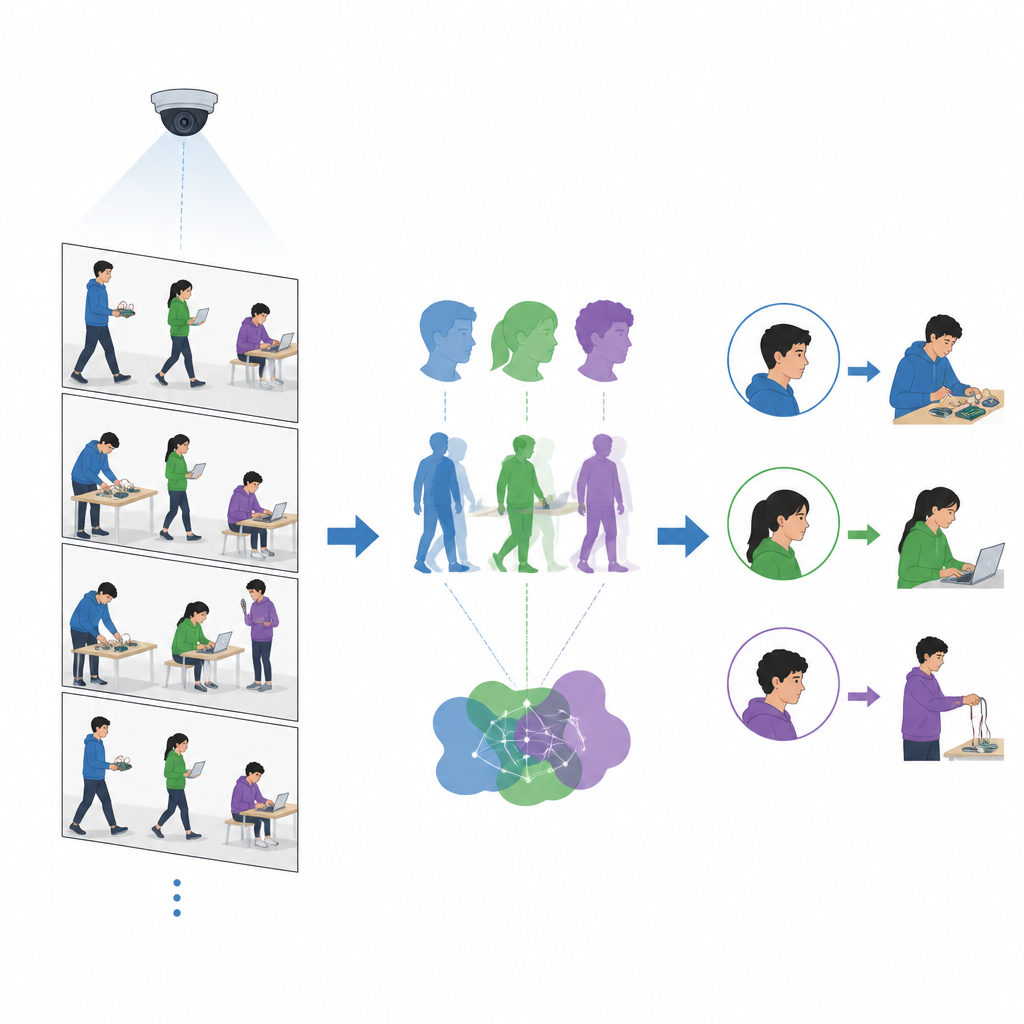
Apprendre à l’ordinateur à repérer des actions simples
Au-delà de l’identification des personnes présentes, les enseignant·e·s s’intéressent aussi aux actions réalisées par les étudiant·e·s. Les chercheur·se·s ajoutent un module de reconnaissance de comportements qui se concentre sur quelques activités clés en laboratoire, comme programmer sur un ordinateur portable, connecter des fils ou utiliser un téléphone. Un outil séparé trace des squelettes stylisés sur les corps, capturant l’agencement de la tête, du tronc et des membres. L’équipe entraîne ensuite un classificateur d’images léger pour distinguer ces poses basées sur le squelette. Parce que ce modèle analyse des contours simplifiés plutôt que des images complètes, il peut traiter plus de vingt images par seconde, assez vite pour suivre les caméras typiques de salle de classe.
Tester le système dans un laboratoire réel
Le cadre a été évalué dans un cours de commande de servomoteur avec six étudiant·e·s travaillant sur des tâches telles que le câblage de composants, la remise du moteur à l’origine et la rédaction de programmes de mouvement. Les auteur·rice·s ont comparé trois options : uniquement la reconnaissance faciale, uniquement la ré-identification basée sur le corps, et leur méthode dynamique combinée. Pendant la période de connexion et tout au long de la séance pratique, l’approche combinée a nettement surpassé les deux autres, obtenant une plus grande précision et de meilleurs scores globaux pour décider quel·le étudiant·e apparaissait sur chaque image vidéo. Pour le module d’action, la précision de reconnaissance variait d’environ deux tiers pour la programmation à plus de quatre cinquièmes pour l’utilisation du téléphone, malgré l’emploi d’un jeu d’entraînement relativement réduit.
Ce que cela signifie pour les classes de demain
Pour un lectorat non spécialiste, le message principal est que l’étude montre comment la combinaison de différents indices visuels et leur mise à jour au fil du temps peuvent aider les ordinateurs à suivre qui est qui dans un laboratoire d’enseignement animé, tout en reconnaissant quelques comportements simples. Le système éprouve encore des difficultés face aux vues latérales marquées du visage et à la pleine variété des mouvements des étudiant·e·s, mais les auteur·rice·s indiquent des pistes d’amélioration en utilisant des modèles faciaux tridimensionnels et des données d’entraînement plus riches. Ils soulignent également la nécessité de garanties en matière de vie privée, comme le stockage uniquement des caractéristiques strictement nécessaires et le chiffrement des images originales. Ensemble, ces idées ouvrent la voie à des environnements de laboratoire où les ordinateurs soutiennent discrètement les enseignant·e·s en surveillant la participation et l’activité sans perturber l’apprentissage pratique.
Citation: Ma, J., Wang, R. & Lan, W. Deep learning-based visual algorithms for identity and action recognition in engineering practical courses. Sci Rep 16, 15524 (2026). https://doi.org/10.1038/s41598-026-45964-6
Mots-clés: surveillance des étudiants, reconnaissance faciale, reconnaissance d’action, enseignement en ingénierie, vision par ordinateur