Clear Sky Science · nl
Visuele algoritmen op basis van deep learning voor identiteit- en activiteitsherkenning in praktijkvakken voor ingenieurs
Bijhouden wie wat doet in praktijklessen
In veel engineeringlabs bewegen studenten zich door de ruimte om draden aan te sluiten, code te typen en hun telefoon te raadplegen. Voor docenten is het moeilijk om te weten wie welke taak uitvoert, en voor computers is zo’n drukke scène nog lastiger te interpreteren. Deze studie introduceert een kunstmatig intelligentiesysteem dat betrouwbaar zowel de identiteit van studenten als eenvoudige handelingen kan herkennen in een echte lesruimte, zelfs wanneer mensen van de camera wegkijken of van positie veranderen.
Waarom gewone gezichtscontroles niet voldoende zijn
Moderne gezichtsherkenning werkt goed wanneer mensen stilzitten en naar een camera kijken, zoals in een collegezaal of bij een beveiligingspoort. In praktijkvakken buigen studenten zich echter over werkbanken, draaien met hun hoofd en lopen rond apparatuur. Onder deze omstandigheden verliest standaard gezichtsherkenning vaak de persoon uit het oog omdat die vertrouwt op duidelijke, frontale aanzichten. Methoden voor persoonsheridentificatie die zich richten op het hele lichaam ondervinden vergelijkbare problemen, omdat lichaamsvorm en kleding er heel anders uitzien wanneer studenten zich voorover buigen, roteren of door de ruimte bewegen.
Gezichten, lichamen en beweging combineren
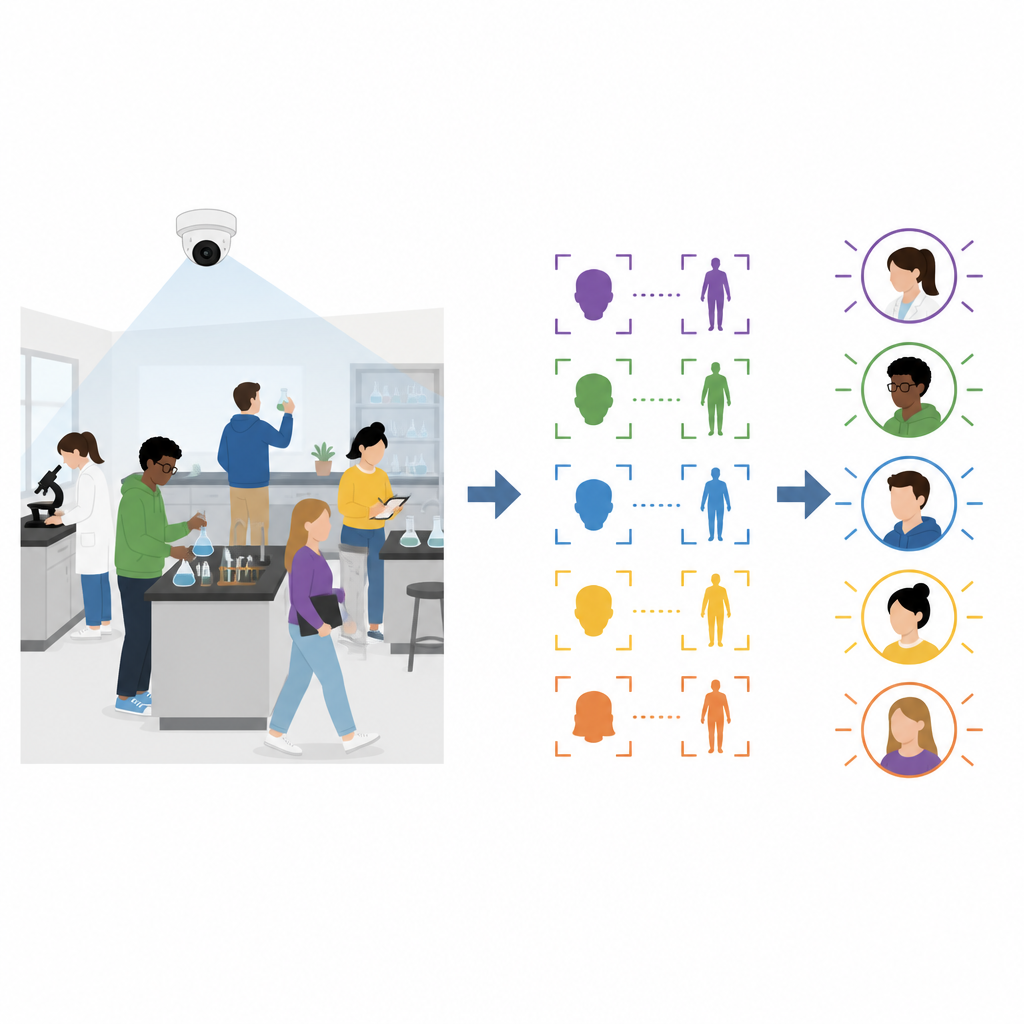
De auteurs stellen een raamwerk voor dat informatie uit zowel gezicht- als bovenlichaambeelden combineert en voortdurend bijwerkt terwijl de les voortschrijdt. Vooraf levert elke student een duidelijke frontale foto aan het schoolsysteem. Aan het begin van de sessie loggen studenten in door naar de camera te kijken terwijl ze in het lab staan. Het systeem matcht hun gezichten met de opgeslagen foto’s en registreert tegelijk voor elke ingelogde persoon een lichaamsbeeld. Deze eerste gezicht- en lichaamskenmerken vormen het uitgangspunt voor het later volgen van iedereen tijdens de les.
Een levende geheugenbank van elke student opbouwen
Zodra de praktische les begint, analyseert het systeem video met ongeveer tien tot vijftien frames per seconde. Voor elk frame detecteert het gezichten en lichamen en extraheert het compacte numerieke beschrijvingen van elk exemplaar. Als een gezicht in het huidige frame overeenkomt met de opgeslagen foto, maar de lichaamsmatch zwak is, gaat het systeem ervan uit dat het gezicht betrouwbaar is en voegt het de nieuwe lichaamsperspectief toe aan een dynamische lichaambibliotheek. In andere situaties, wanneer een lichaam goed matcht en zijn positie tussen frames slechts licht verandert terwijl het gezicht kort ontbreekt, beschouwt het systeem dit als een snelle hoofdbeweging en voegt het de nieuwe gezichtsscene toe aan een dynamische gezichtsbibliotheek. In de loop van de tijd wordt elke student vertegenwoordigd door vele voorbeelden van gezicht en lichaam onder verschillende hoeken, schalen en lichtomstandigheden, wat herkenning in latere frames veel betrouwbaarder maakt.
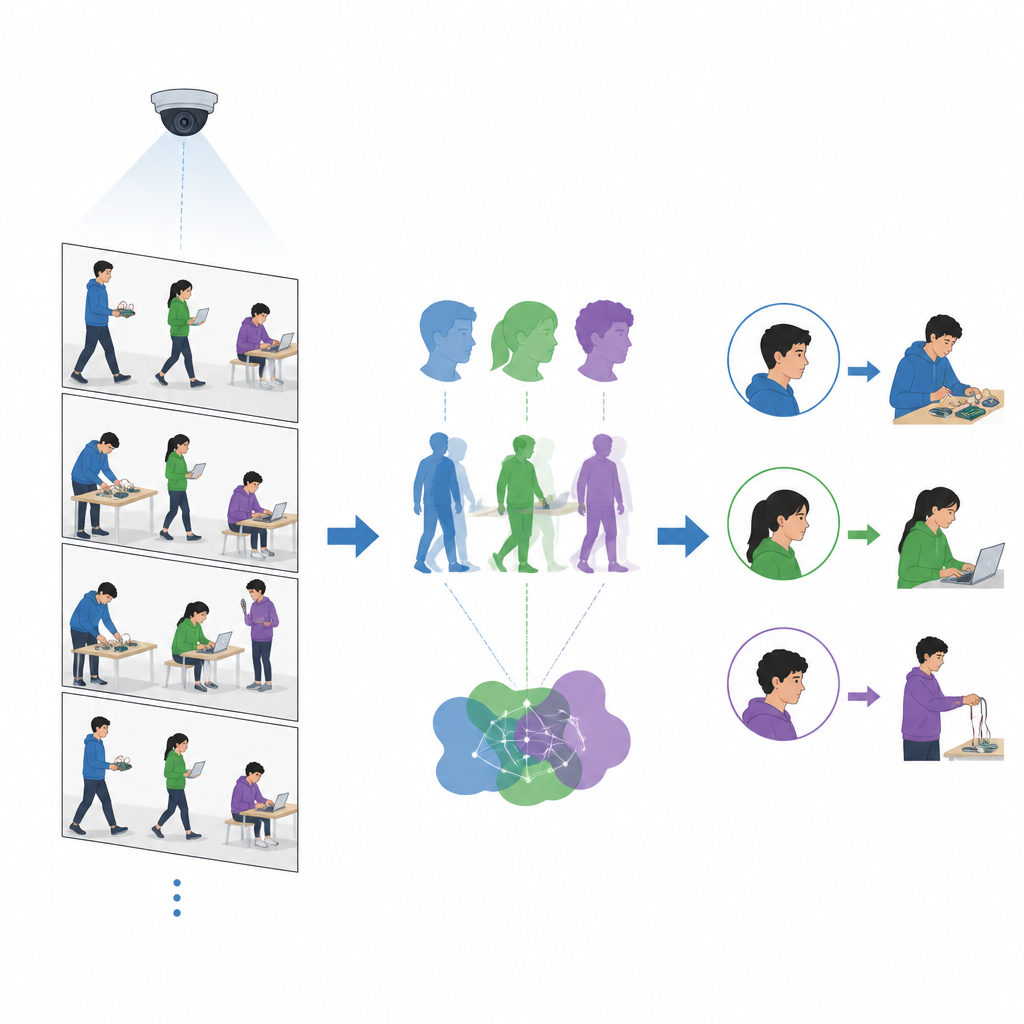
De computer leren eenvoudige handelingen te zien
Naast weten wie er in de ruimte is, willen docenten ook weten wat studenten doen. De onderzoekers voegen een gedragsherkenningscomponent toe die zich richt op een paar sleutelactiviteiten in het lab, zoals programmeren op een laptop, draden aansluiten of een telefoon gebruiken. Een apart hulpmiddel tekent stokfiguurachtige skeletmodellen over menselijke lichamen en legt zo de positie van hoofd, torso en ledematen vast. Het team traint vervolgens een lichtgewicht beeldclassificator om deze skeletgebaseerde houdingen te onderscheiden. Omdat dit model vereenvoudigde omtrekken analyseert in plaats van volledige beelden, kan het meer dan twintig videoframes per seconde verwerken, snel genoeg om bij te blijven met typische klascamera’s.
Het systeem testen in een echt lab
Het raamwerk werd geëvalueerd in een cursus servo-motorsturing met zes studenten die taken uitvoerden zoals componenten bedraden, een motor naar zijn nulpositie terugzetten en motion-programma’s schrijven. De auteurs vergeleken drie opties: alleen gezichtsherkenning, alleen lichaamsgebaseerde re-identificatie en hun gecombineerde dynamische methode. Tijdens de inlogperiode en gedurende de praktijkles presteerde de gecombineerde benadering duidelijk beter dan de andere twee, met hogere precisie en betere totaalscores bij het bepalen welke student in elk videoframe voorkwam. Voor de actiemodule lag de herkenningsnauwkeurigheid tussen ongeveer twee derde voor programmeren en meer dan vier vijfde voor telefoongebruik, ondanks een relatief kleine trainingsset.
Wat dit betekent voor toekomstige klaslokalen
Voor een niet-specialistische lezer is de kernboodschap dat de studie laat zien hoe het combineren van verschillende visuele aanwijzingen en het continu bijwerken daarvan computers kan helpen bijhouden wie wie is in een druk leslokaal, terwijl ook een paar eenvoudige gedragingen worden herkend. Het systeem heeft nog moeite met sterke zijdelingse aanzichten van gezichten en met de volledige variëteit aan studentenbewegingen, maar de auteurs schetsen manieren om het te verbeteren met driedimensionale gezichtmodellen en rijkere trainingsdata. Ze benadrukken ook de noodzaak van privacybescherming, zoals het alleen opslaan van de strikt benodigde kenmerken en het versleutelen van originele beelden. Samen wijzen deze ideeën op labomgevingen waarin computers docenten stil ondersteunen door deelname en activiteit te monitoren zonder het hands-on leren te onderbreken.
Bronvermelding: Ma, J., Wang, R. & Lan, W. Deep learning-based visual algorithms for identity and action recognition in engineering practical courses. Sci Rep 16, 15524 (2026). https://doi.org/10.1038/s41598-026-45964-6
Trefwoorden: studentmonitoring, gezichtsherkenning, activiteitsherkenning, engineeringonderwijs, computervisie