Clear Sky Science · ru
Многoагентная платформа на базе искусственного интеллекта для адаптивного моделирования кибератак и автоматизированного реагирования на инциденты в средах киберрайнов
Почему важны более продуманные кибротренировки
Каждый день компании и государственные органы репетируют цифровые катастрофы в «киберрайнах» — безопасных изолированных сетях, где хакеры и защитники могут отрабатывать навыки. Но многие такие полигоны по‑прежнему опираются на сценарии с фиксированной последовательностью действий, которые мало похожи на современные скрытные, постоянно меняющиеся угрозы. В этой работе предлагается новый подход к повышению реализма тренировок: использование «агентов» на базе искусственного интеллекта, которые самостоятельно учатся атаковать и защищаться, заставляя людей и инструменты иметь дело с противниками, умеющими мыслить и адаптироваться.
От статичных сценариев к живым военным играм
Традиционные киберрайны работают как заранее написанная пьеса: инструктор выбирает сценарий атаки, запускает его и наблюдает. Это полезно для новичков, но неэффективно против современных противников, которые проводят цепочки тихих шагов, исследуют оборону и меняют тактику при обнаружении. Приведённые в статье исследования показывают, что более половины моделируемых атак не включают важные приёмы — например перемещение с одной взломанной машины на другую или сокрытие от систем мониторинга. В результате тренировки выглядят хорошо на бумаге, но недостаточно готовят аналитиков к беспорядочной реальности интернета.
Обучение цифровых агентов атаковать и защищаться
Чтобы сократить этот разрыв, авторы создают многoагентную систему — небольшое «общество» программных сущностей, действующих независимо, но взаимодействующих в общей виртуальной сети. С одной стороны — агенты‑атакующие, которые учатся планировать и корректировать шаги с помощью механизмов вознаграждения и штрафа, подобно игровому ИИ, стремящемуся победить. С другой — агенты‑защитники, отслеживающие сетевой трафик на предмет аномалий и автоматически выбирающие меры: изолировать подозрительную машину или заблокировать рискованное соединение. Оба типа агентов обучаются на больших наборах реального сетевого трафика, так что их поведение отражает настоящую вредоносную и обычную активность, а не игрушечные примеры.
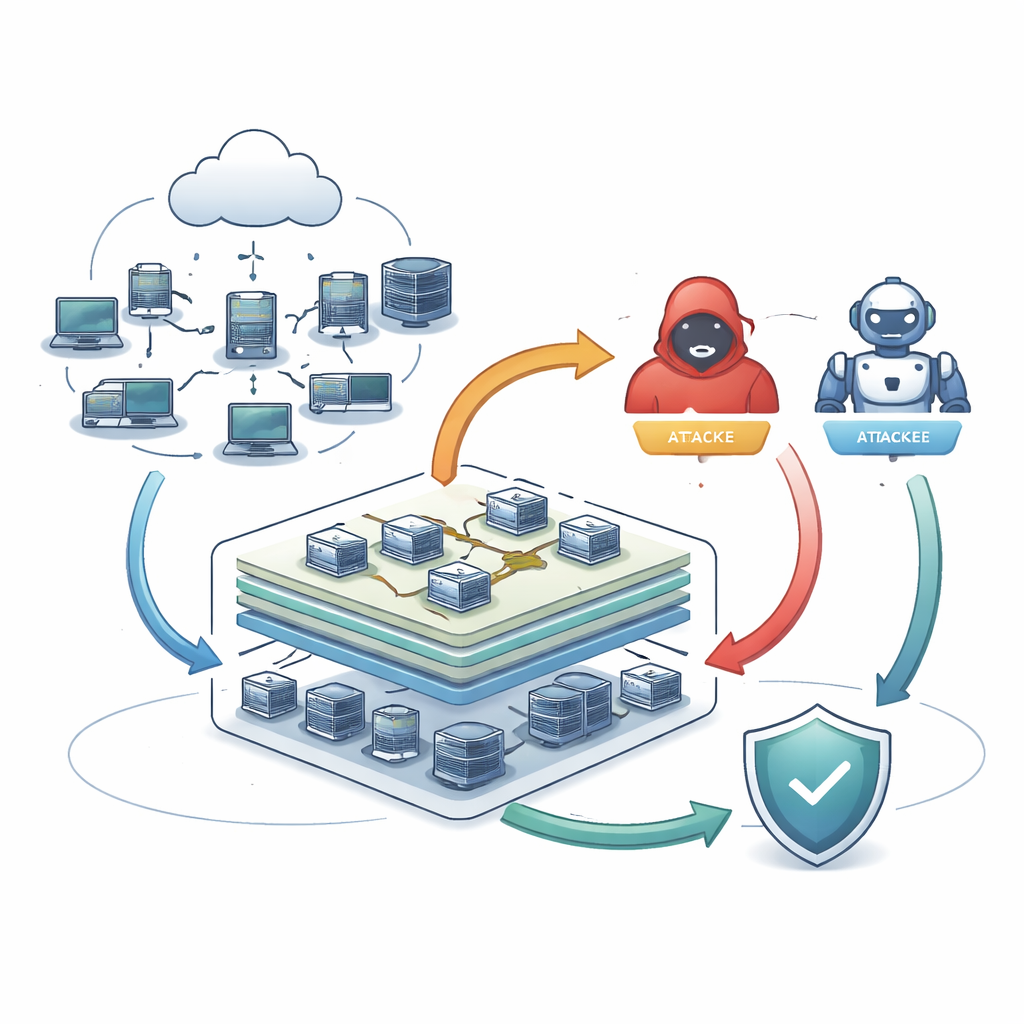
Создание и подключение тестовой среды
Команда интегрирует этих агентов в CyDER 2.0 — облачный киберрайн, способный разворачивать разные корпоративные сети: от небольших с несколькими десятками машин до крупных сред с сотнями узлов. Перед обучением они тщательно очищают и балансируют исходные данные, чтобы редкие атаки не терялись на фоне повседневного трафика. Атакующий агент использует глубокое обучение для исследования многошаговых последовательностей: сканирование уязвимых машин, эксплуатация одной из них, повышение привилегий, затем распространение или кража данных — при попытке оставаться незамеченным. Агенты‑защитники комбинируют два подхода: традиционный классификатор, настроенный на размеченные атаки, и автокодировщик, который изучает шаблоны «нормального» поведения и сигнализирует о отклонениях, включая ранее неизвестные приёмы.
Как умный райнг работает на практике
Исследователи сравнивают своих агентов на базе ИИ с двумя распространёнными альтернативами: фиксированными скриптами и многoагентной системой на основе правил, поведение которой фактически не меняется. На малых, средних и больших тестовых сетях обучающиеся агенты обнаруживают атаки точнее и реже пропускают инциденты. В наиболее требовательном смешанном сценарии на самой большой сети новая система сохраняет хорошее соотношение обнаружения угроз и избегания ложных срабатываний, в то время как статические подходы заметно теряют в эффективности. Не менее важно, что её автоматические ответы срабатывают на несколько секунд быстрее базовых систем — разрыв, который может существенно ограничить ущерб при стремительно развивающемся нарушении. Сами агенты‑атакующие в ходе обучения становятся более способными, объединяя длинные, сложные цепочки атак, при этом использование ресурсов остаётся в умеренных пределах.
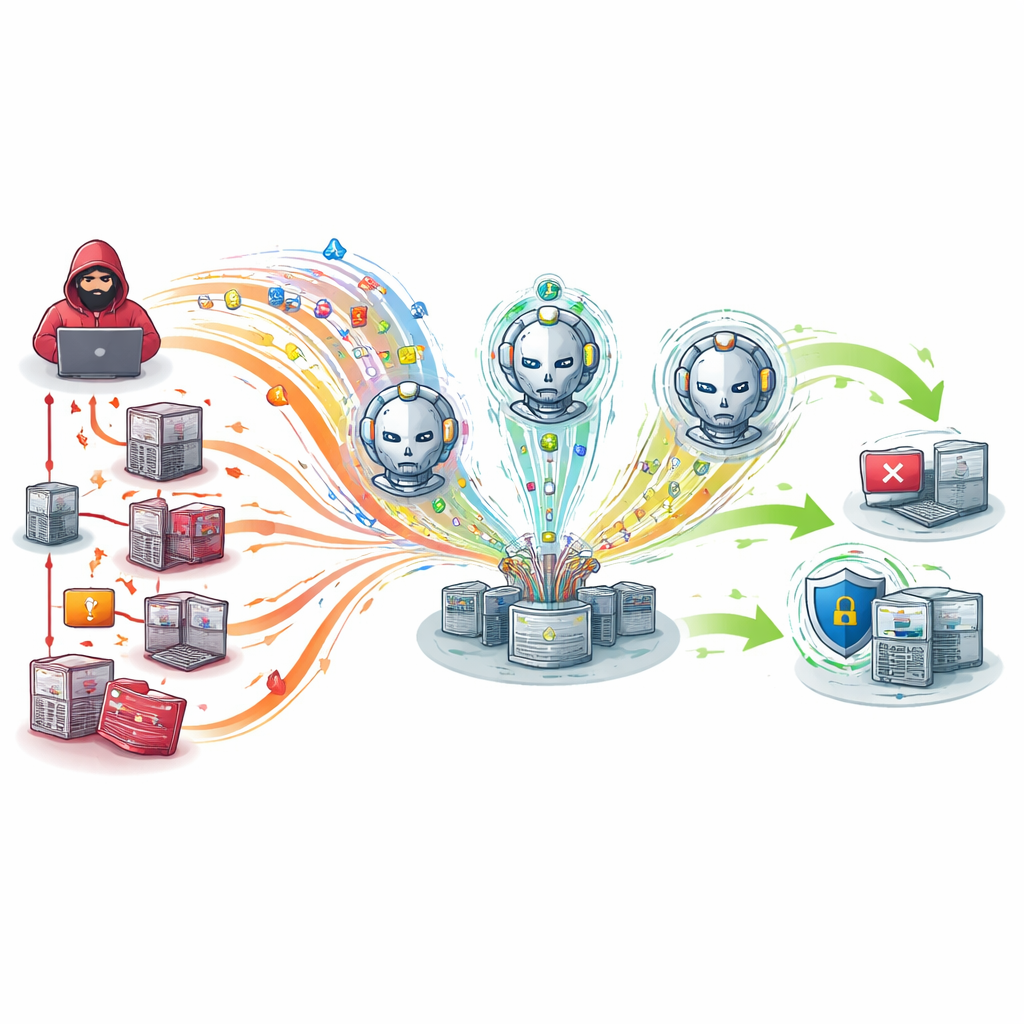
Что это значит для готовности в реальном мире
С точки зрения неспециалиста исследование показывает, что киберучения можно превратить из заготовленных упражнений в живые военные игры, где обе стороны мыслят самостоятельно. Подключив обучающихся атакующих и защитников к реалистичным учебным сетям и дав им реальные записи трафика, платформа формирует сценарии, которые гораздо ближе к реальным инцидентам. В испытаниях это даёт более точное обнаружение, более быструю реакцию и возможность масштабироваться до более сложных сред без перегрузки системы. Авторы утверждают, что такие интеллектуальные райны лучше подготовят команды безопасности к будущим атакам и станут базой для более автономных цифровых оборон, а в будущих работах планируется уменьшить требования этих мощных агентов, чтобы они могли работать и на менее мощных устройствах.
Цитирование: Agrawal, A., Nadeem, M., Al Nuaim, A. et al. Artificial intelligence driven multi agent framework for adaptive cyber attack simulation and automated incident response in cyber range environments. Sci Rep 16, 11673 (2026). https://doi.org/10.1038/s41598-026-45937-9
Ключевые слова: киберрайн, адаптивные кибератаки, многoагентные системы, защита на базе ИИ, реагирование на инциденты