Clear Sky Science · de
Künstliche Intelligenz gesteuertes Multi‑Agenten‑Framework für adaptive Cyberangriffssimulation und automatisierte Vorfallreaktion in Cyber‑Range‑Umgebungen
Warum intelligentere Cyber‑Übungen wichtig sind
Täglich proben Unternehmen und Behörden digitale Katastrophen in sogenannten „Cyber‑Ranges“ – sicheren, abgeschotteten Netzwerken, in denen Angreifer und Verteidiger üben können. Viele dieser Trainingsumgebungen basieren jedoch noch immer auf vorgegebenen, vorhersehbaren Angriffsszenarien, die wenig Ähnlichkeit mit den heutigen, heimlichen und formwandelnden Bedrohungen haben. Dieser Artikel stellt einen neuen Ansatz vor, um solche Übungen deutlich realistischer zu machen: künstliche Intelligenz‑Agenten, die selbstständig lernen, anzugreifen und zu verteidigen, wodurch menschliche Teilnehmende und Werkzeuge gegen Gegner antreten müssen, die denken und sich anpassen.
Von statischen Szenarien zu lebendigen Kriegsspielen
Traditionelle Cyber‑Ranges funktionieren ein wenig wie ein vorgeskriptetes Theaterstück: Ausbilder wählen ein Angriffsskript, drücken Start und beobachten das Geschehen. Das ist für Einsteiger nützlich, versagt aber gegen moderne Gegner, die viele leise Schritte verketten, Verteidigungen sondieren und den Kurs ändern, wenn sie entdeckt werden. In der Arbeit zitierte Studien zeigen, dass mehr als die Hälfte der simulierten Angriffe wichtige Taktiken nicht enthalten, etwa die seitliche Bewegung von einem kompromittierten Rechner zum nächsten oder das Verstecken vor Überwachungswerkzeugen. Das Ergebnis sind Trainings, die auf dem Papier ordentlich aussehen, Analysten aber unzureichend auf die unordentliche Realität des Internets vorbereiten.
Digitale Agenten das Angreifen und Verteidigen beibringen
Um diese Lücke zu schließen, bauen die Autorinnen und Autoren ein Multi‑Agenten‑System – eine kleine Gesellschaft von Software‑Entitäten, die unabhängig handeln und zugleich in einem gemeinsamen virtuellen Netzwerk interagieren. Auf der einen Seite stehen Angreifer‑Agenten, die lernen, ihre Schritte mittels Belohnungs‑ und Bestrafungsfeedback zu planen und anzupassen, ähnlich einer spielenden KI, die gewinnen will. Auf der anderen Seite stehen Verteidiger‑Agenten, die den Netzwerkverkehr auf ungewöhnliche Muster überwachen und automatisch reagieren, zum Beispiel einen verdächtigen Rechner isolieren oder eine riskante Verbindung blockieren. Beide Agententypen werden mit großen, realen Sammlungen von Netzwerkaktivitäten trainiert, sodass ihr Verhalten echte bösartige und normale Nutzung widerspiegelt und nicht nur Spielbeispiele.
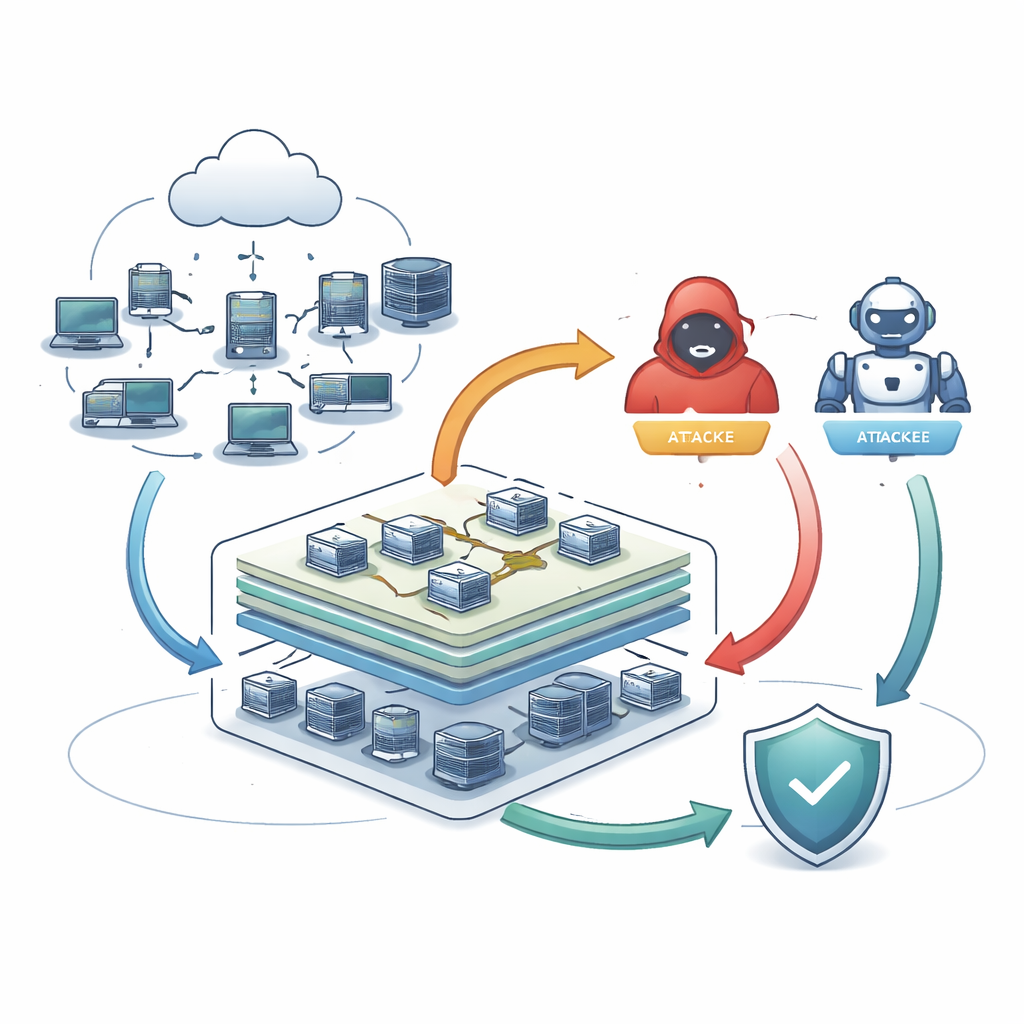
Aufbau und Vernetzung des Testbeds
Das Team integriert diese Agenten in CyDER 2.0, eine cloudbasierte Cyber‑Range, die verschiedene Unternehmensnetzwerke nachbilden kann – von kleinen Konfigurationen mit wenigen Dutzend Rechnern bis hin zu großen Umgebungen mit Hunderten Hosts. Vor dem Training bereinigen und balancieren sie die zugrundeliegenden Daten sorgfältig, damit seltene Angriffe nicht von Alltagsverkehr überdeckt werden. Der Angreifer‑Agent nutzt Deep Learning, um mehrstufige Sequenzen zu erkunden, wie das Scannen nach schwachen Rechnern, Ausnutzen einer Schwachstelle, Eskalation von Rechten und anschließendes Ausbreiten oder Datendiebstahl, und versucht dabei unentdeckt zu bleiben. Verteidiger‑Agenten kombinieren zwei komplementäre Ansätze: einen klassischen Klassifikator, der auf gelabelten Angriffen feinjustiert ist, und einen Autoencoder, der lernt, wie „normal“ aussieht, und Abweichungen markiert, einschließlich zuvor unbekannter Tricks.
Wie sich die intelligente Range in der Praxis schlägt
Die Forschenden lassen ihre KI‑gesteuerten Agenten gegen zwei gängige Alternativen antreten: feste Skripte und ein regelbasiertes Multi‑Agenten‑System, dessen Verhalten sich nie wirklich ändert. In kleinen, mittleren und großen Testnetzwerken erkennen die lernenden Agenten Angriffe genauer und mit weniger Fehlversäumnissen. Im anspruchsvollsten Mischangriffsszenario im größten Netzwerk hält das neue System eine gute Balance zwischen Erkennung von Bedrohungen und Vermeidung von Fehlalarmen, während statische Ansätze deutlich schlechter werden. Gerade wichtig ist, dass die automatisierten Reaktionen mehrere Sekunden schneller ausgelöst werden als bei den Baselines — ein Vorsprung, der bei schnell ablaufenden Einbrüchen erheblichen Schaden begrenzen kann. Die Angreifer‑Agenten selbst werden während des Trainings fähiger und fügen längere, komplexere Angriffsketten zusammen, während der Ressourcenverbrauch aller Agenten in moderaten Grenzen bleibt.
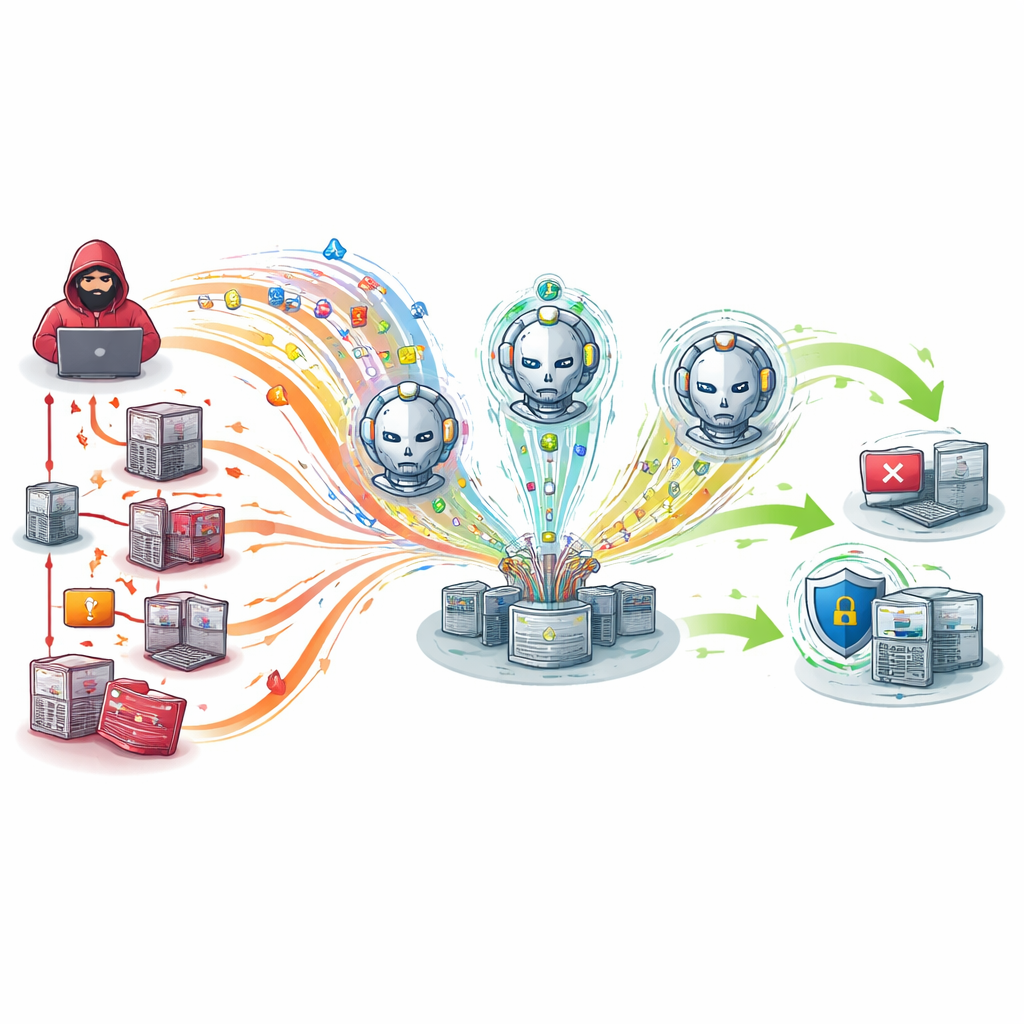
Was das für die reale Einsatzbereitschaft bedeutet
Aus Sicht einer nicht‑fachlichen Leserschaft zeigt die Studie, dass Cyber‑Sicherheitsübungen von vorgekauten Trainings zu lebendigen Kriegsspielen aufgewertet werden können, in denen beide Seiten eigenständig denken. Indem lernende Angreifer und Verteidiger in realistische Übungsnetze eingespeist und mit echten Verkehrsaufzeichnungen versorgt werden, erzeugt das Framework Szenarien, die tatsächlichen Vorfällen deutlich näherkommen. In Tests führt das zu schärferer Erkennung, schnellerer Reaktion und der Fähigkeit, auf komplexere Umgebungen zu skalieren, ohne das System zu überlasten. Die Autorinnen und Autoren argumentieren, dass solche intelligenten Ranges Sicherheitsteams besser auf zukünftige Angriffe vorbereiten und eine Grundlage für autonomere digitale Verteidigungen schaffen können; zukünftige Arbeiten werden darauf abzielen, diese leistungsfähigen Agenten zu verschlanken, damit sie auch auf kleineren, leistungsschwächeren Geräten laufen können.
Zitation: Agrawal, A., Nadeem, M., Al Nuaim, A. et al. Artificial intelligence driven multi agent framework for adaptive cyber attack simulation and automated incident response in cyber range environments. Sci Rep 16, 11673 (2026). https://doi.org/10.1038/s41598-026-45937-9
Schlüsselwörter: cyber range, adaptive Cyberangriffe, Multi‑Agenten‑Systeme, KI‑gesteuerte Verteidigung, Vorfallreaktion