Clear Sky Science · nl
Door kunstmatige intelligentie aangedreven multi-agentkader voor adaptieve cyberaanvalssimulatie en geautomatiseerde incidentrespons in cyber range-omgevingen
Waarom slimmer uitgevoerde cyberoefeningen ertoe doen
Dagelijks oefenen bedrijven en overheden op digitale rampen met behulp van “cyber ranges” – veilige, geïsoleerde netwerken waar aanvallers en verdedigers kunnen trainen. Veel van deze oefenomgevingen vertrouwen echter nog steeds op gescripte, voorspelbare aanvalsscenario’s die weinig lijken op de hedendaagse, sluipende en veranderlijke dreigingen. Dit artikel introduceert een nieuwe manier om die oefeningen realistischer te maken: kunstmatige-intelligentie‑“agenten” die zelfstandig leren aanvallen en verdedigen, waardoor menselijke trainees en tools te maken krijgen met tegenstanders die denken en zich aanpassen.
Van statische scenario’s naar levende oorlogsspelen
Traditionele cyber ranges werken een beetje als een uitgeschreven toneelstuk: instructeurs kiezen een aanvalsscript, drukken op start en zien de actie zich ontvouwen. Dat is nuttig voor beginners, maar faalt tegen moderne tegenstanders die vele stille stappen aaneenkoppelen, verdedigingslinies aftasten en van koers veranderen zodra ze worden ontdekt. Studies die in het artikel worden genoemd tonen aan dat meer dan de helft van gesimuleerde aanvallen cruciale tactieken niet bevat, zoals lateraal bewegen tussen gecompromitteerde machines of het verbergen voor monitoringtools. Het resultaat is training die op papier netjes oogt maar analisten onvoldoende voorbereidt op de rommelige realiteit van het internet.
Digitale agenten leren aanvallen en verdedigen
Om deze kloof te dichten bouwen de auteurs een multi‑agentsysteem – een kleine samenleving van software-entiteiten die onafhankelijk handelen maar binnen een gedeeld virtueel netwerk met elkaar interacteren. Aan de ene kant zijn er aanvalleragenten die leren hun zetten te plannen en aan te passen met behulp van beloning‑ en strafsignalen, vergelijkbaar met een spel‑AI die leert te winnen. Aan de andere kant zijn er verdedigeragenten die netwerkverkeer monitoren op afwijkende patronen en automatisch kiezen hoe te reageren, bijvoorbeeld door een verdachte computer te isoleren of een risicovolle verbinding te blokkeren. Beide agentgroepen worden getraind op grote, reële verzamelingen netwerkactiviteit zodat hun gedrag echte kwaadaardige en normale gebruiken weerspiegelt in plaats van speelgoedvoorbeelden.
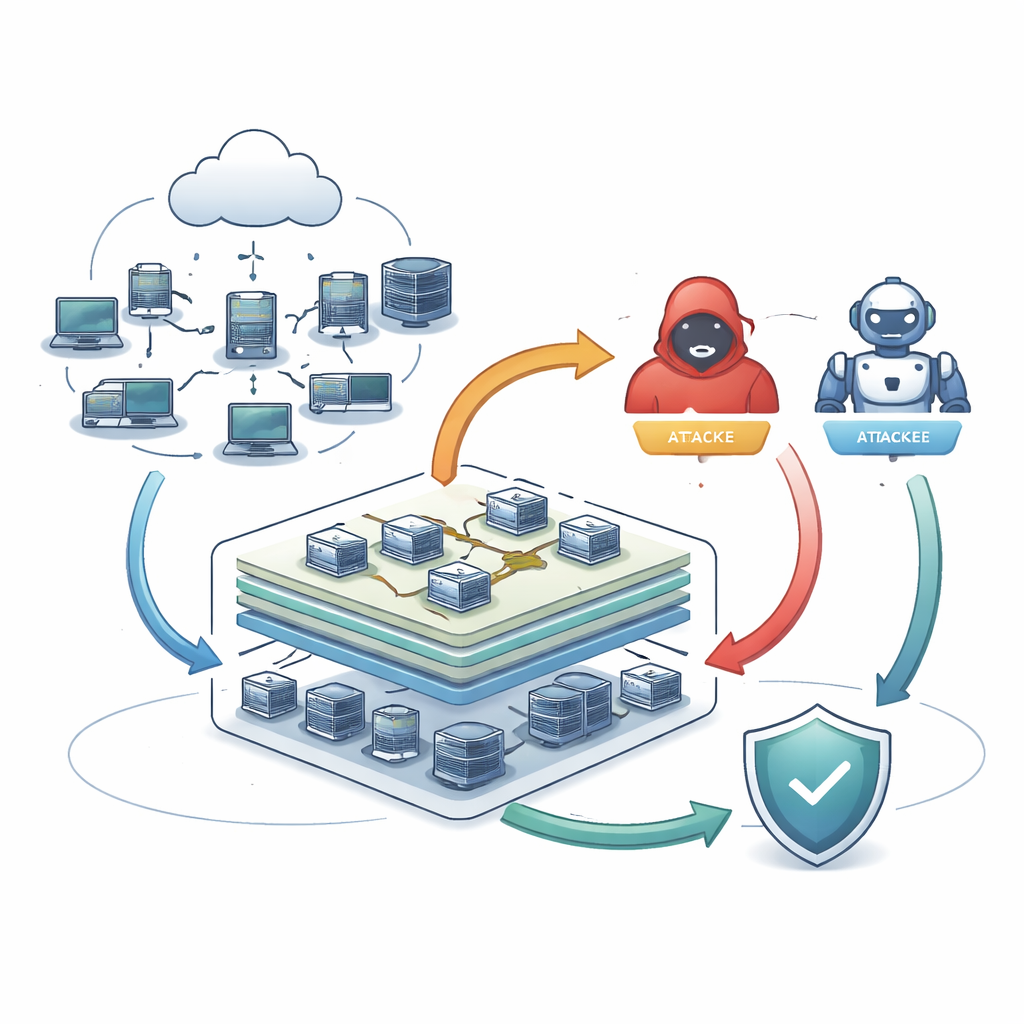
Opbouw en bekabeling van de testomgeving
Het team integreert deze agenten in CyDER 2.0, een cloudgebaseerde cyber range die verschillende soorten bedrijfsachtige netwerken kan opzetten, van kleine omgevingen met enkele tientallen machines tot grote netwerken met honderden hosts. Voor de training maken ze de onderliggende data zorgvuldig schoon en houden ze die in balans zodat zeldzame aanvallen niet worden overstemd door alledaags verkeer. De aanvalleragent gebruikt deep learning om meerstapssequenties te verkennen zoals scannen op kwetsbare machines, het exploiteren van een systeem, privilege-escalatie en daarna verspreiden of gegevens stelen, terwijl hij probeert onopgemerkt te blijven. Verdedigeragenten combineren twee complementaire benaderingen: een traditionele classifier getraind op gelabelde aanvallen en een autoencoder die leert wat “normaal” is en afwijkingen markeert, inclusief eerder niet geziene trucs.
Hoe de slimme range presteert in de praktijk
De onderzoekers zetten hun AI-gedreven agenten af tegen twee veelgebruikte alternatieven: vaste scripts en een regelgebaseerde multi-agentopstelling waarvan het gedrag nooit echt verandert. In kleine, middelgrote en grote testnetwerken detecteren de lerende agenten aanvallen nauwkeuriger en met minder missers. In het meest veeleisende gemengde-aanvalsscenario op het grootste netwerk behoudt het nieuwe systeem een sterke balans tussen het onderscheppen van bedreigingen en het vermijden van valse alarmen, terwijl statische benaderingen sterk verslechteren. Even belangrijk is dat de geautomatiseerde reacties enkele seconden sneller worden getriggerd dan de referentiesystemen, een marge die de schade bij snel voortschrijdende inbraken aanzienlijk kan beperken. De aanvalleragenten zelf worden tijdens de training capabeler en knopen langere, complexere aanvalsketens aan elkaar, terwijl het middelengebruik voor alle agenten binnen bescheiden grenzen blijft.
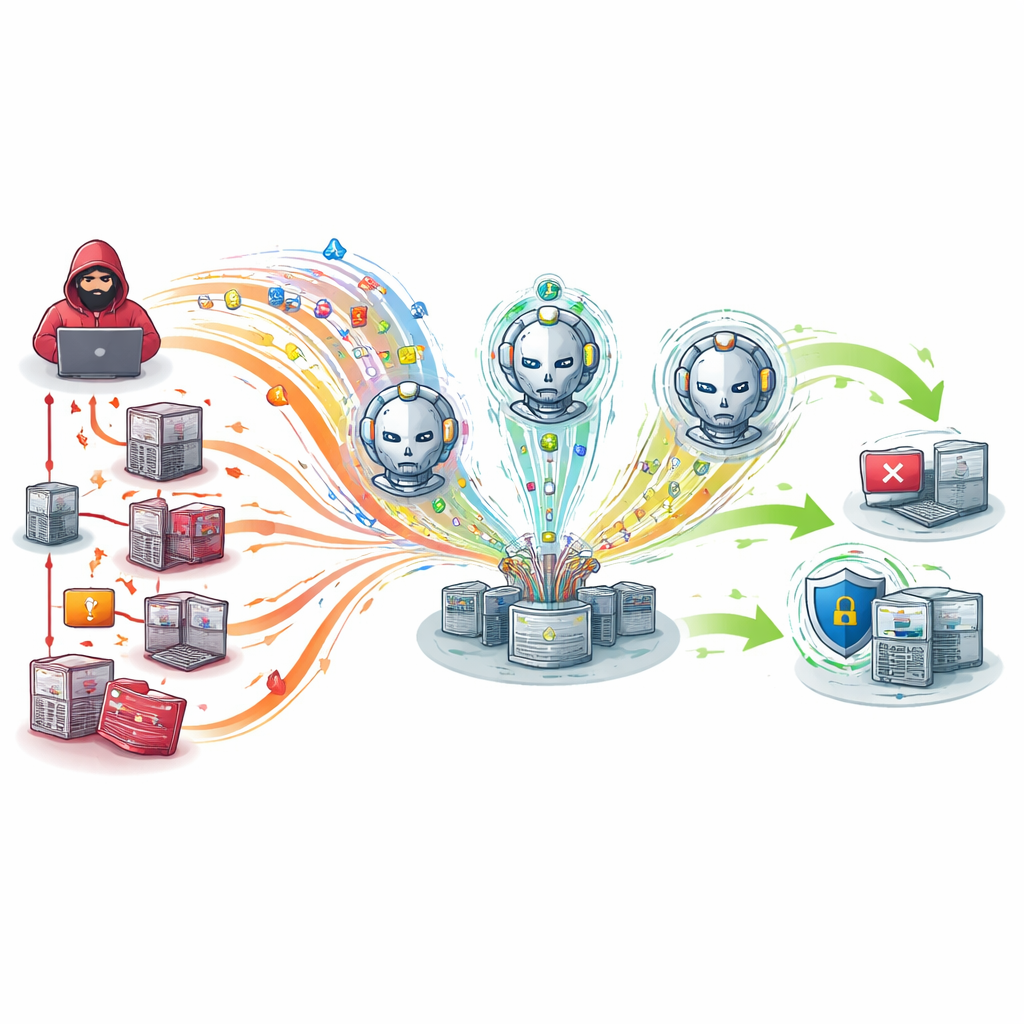
Wat dit betekent voor gereedheid in de echte wereld
Voor leken laat de studie zien dat cyberveiligheidsoefeningen kunnen worden opgewaardeerd van kant-en-klare oefeningen naar levende oorlogsspelen waarin beide partijen zelfstandig denken. Door lerende aanvallers en verdedigers aan te sluiten op realistische oefennetwerken en ze echte verkeersregistraties voor te leggen, produceert het kader scenario’s die veel dichter bij daadwerkelijke incidenten staan. In tests leidt dit tot scherpere detectie, snellere reacties en het vermogen op te schalen naar complexere omgevingen zonder het systeem te overweldigen. De auteurs bepleiten dat zulke intelligente ranges beveiligingsteams beter kunnen voorbereiden op toekomstige aanvallen en een basis bieden voor meer autonome digitale verdedigingen, terwijl toekomstig werk zich zal richten op het versmallen van deze krachtige agenten zodat ze ook op kleinere, minder krachtige apparaten kunnen draaien.
Bronvermelding: Agrawal, A., Nadeem, M., Al Nuaim, A. et al. Artificial intelligence driven multi agent framework for adaptive cyber attack simulation and automated incident response in cyber range environments. Sci Rep 16, 11673 (2026). https://doi.org/10.1038/s41598-026-45937-9
Trefwoorden: cyber range, adaptieve cyberaanvallen, multi-agentsystemen, AI-gedreven verdediging, incidentrespons