Clear Sky Science · ru
Безопасность QR-кодов: адаптивный подход к переобучению для динамического обнаружения угроз по URL
Почему эти крошечные квадраты важны для вашей безопасности
QR-коды незаметно стали мостом между физическим миром и интернетом, позволяя одним сканированием перейти к меню, страницам оплаты, приложениям и многому другому. Но та же удобство, которое делает их полезными, превращает их в привлекательный инструмент для преступников: в безобидно выглядящих черно‑белых квадратах можно скрыть опасные веб‑ссылки. В этой статье исследуется, как продвинутый искусственный интеллект может научиться отличать безопасные ссылки из QR‑кодов от вредоносных и продолжать улучшаться по мере появления новых мошеннических схем.
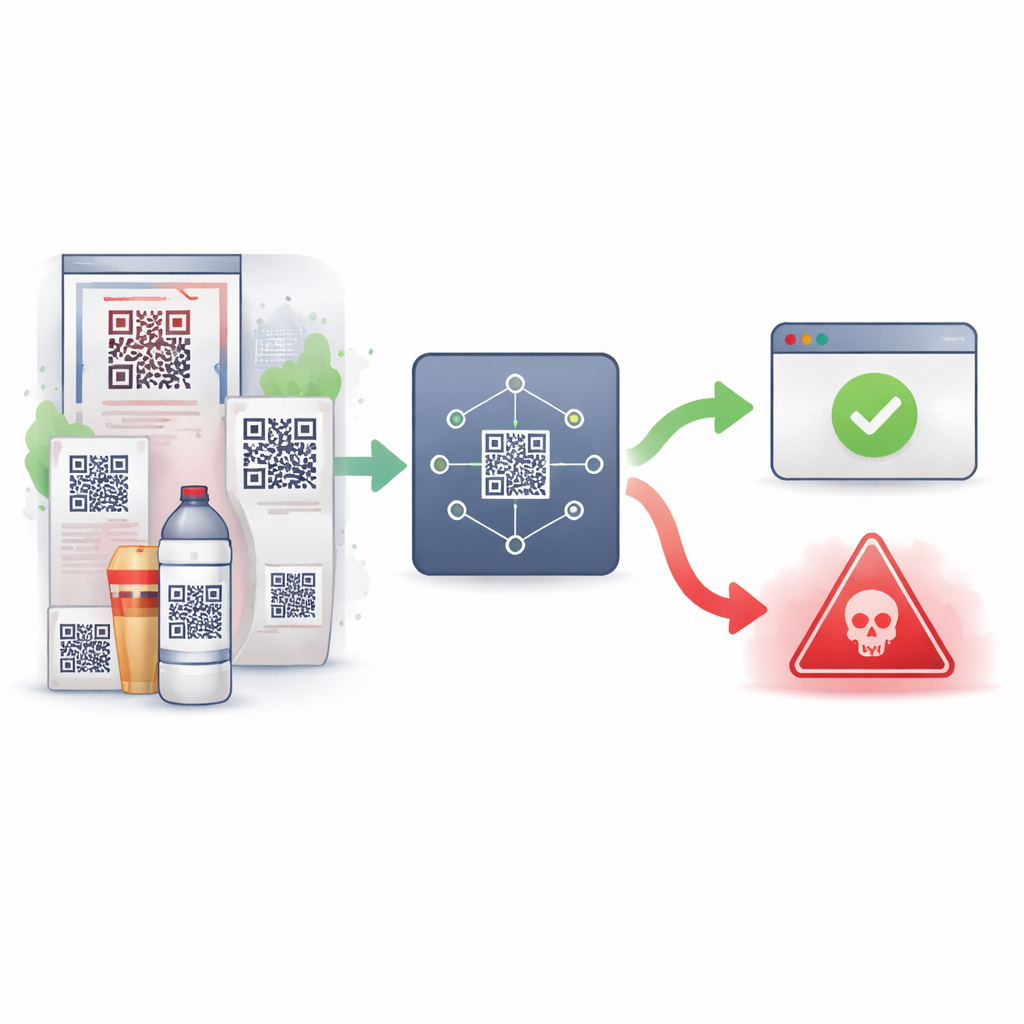
От удобных ярлыков до скрытых ловушек
За последнее десятилетие, а особенно во время пандемии COVID‑19, использование QR‑кодов резко возросло: за короткое время было зафиксировано десятки миллионов сканирований. Большинство этих кодов просто ведут на обычные веб‑страницы. Однако злоумышленники заметили, что люди редко проверяют, куда ведет код перед сканированием, и часто доверяют любому коду, размещенному публично или присланному сервисом. Встраивая в QR‑коды вредоносные веб‑адреса, преступники могут направлять пользователей на фишинговые страницы для кражи паролей или на сайты, которые тайно устанавливают вредоносное ПО. В этом исследовании внимание сосредоточено на невидимом слое — веб‑адресе, или URL, скрытом внутри каждого кода, поскольку именно он является реальным средством атаки, в отличие от физического вмешательства в напечатанный рисунок.
Почему старые защиты не справляются
Традиционные средства защиты пытаются блокировать вредоносные ссылки двумя основными способами. Некоторые полагаются на списки известных плохих URL — это просто, но такие списки легко обходятся, когда злоумышленники меняют адреса. Другие используют машинное обучение, обученное на вручную сконструированных признаках, например длине URL или наличии определенных символов или слов. Эти методы могут работать сравнительно неплохо, но они жесткие и сильно зависят от шаблонов, встречавшихся в старых данных. По мере того как преступники изобретают новые приёмы и изменяют внешний вид своих ссылок, такие фиксированные модели начинают отставать, что приводит либо к пропущенным угрозам, либо к слишком большому числу ложных срабатываний.
Более умный «чтитель» веб‑адресов
Авторы предлагают новую систему, построенную на BERT — мощной модели ИИ, изначально разработанной для понимания естественного языка. Вместо предложений и абзацев они подают BERT символьные строки, составляющие URL. Сначала система сканирует QR‑код и извлекает встроенный URL. Этот URL затем разбивается на токены и прогоняется через компактную версию BERT, которая преобразует его в богатое числовое представление, улавливающее тонкие шаблоны и связи внутри строки. Поверх этого представления исследователи добавляют лёгкий статистический классификатор, который решает, вероятно ли ссылка безвредна или вредоносна. Такая архитектура позволяет системе улавливать сложные признаки, которые пропускают более простые модели, даже несмотря на то, что URL не являются обычным языком.
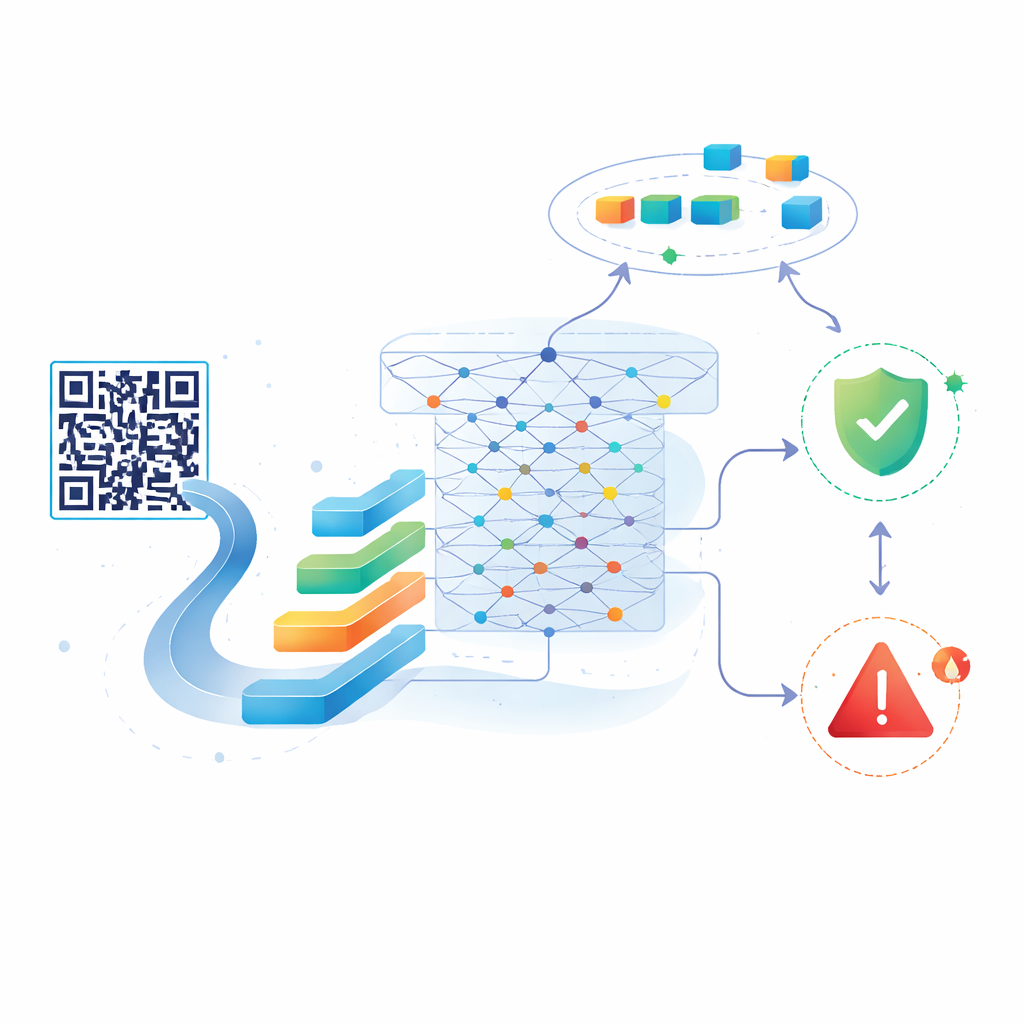
Обучение и переобучение по мере развития угроз
Ключевая особенность подхода в том, что он не остаётся замороженным после первоначального обучения. Авторы начинают с сбалансированного набора примерно из 20 000 промаркированных URL — часть безопасные, часть вредоносные — взятых из публичного датасета. После настройки модели на этих данных они подключают её к живому потоку недавно обнаруженных вредоносных URL от сервиса URLhaus и периодически смешивают эти свежие примеры с дополнительными безопасными ссылками. Каждый раунд переобучения обновляет модель, позволяя ей распознавать новые стили атак, сохраняя при этом ранее приобретённые знания. Тесты показывают, что даже после многократных обновлений точность остаётся очень высокой: около 98–99% на исходных данных и примерно 97% на больших обновлённых наборах, причём система улавливает почти все вредоносные ссылки и редко помечает безопасные как опасные.
Как это помогает обычным пользователям
Для обычного пользователя результат прост: когда вы сканируете QR‑код, работающий за кулисами ИИ быстро решает, кажется ли скрытая ссылка надёжной. Если ссылка выглядит безопасной, вас перенаправляют на сайт; если она кажется опасной, вам может быть показано предупреждение или доступ блокируется. Сочетая мощную модель в стиле обработки языка с непрерывным переобучением на реальных данных об атаках, эта работа предлагает гибкий щит, который адаптируется по мере смены тактик мошенников. Хотя подход требует серьёзных вычислительных ресурсов, он демонстрирует, что умные, развивающиеся фильтры могут сделать скромный QR‑код гораздо более безопасным входом в онлайн‑мир.
Цитирование: Almousa, H., Alsuhibany, S.A. QR code security: an adaptive retraining approach for dynamic URL-based threat detection. Sci Rep 16, 13143 (2026). https://doi.org/10.1038/s41598-026-43002-z
Ключевые слова: безопасность QR-кодов, обнаружение вредоносных URL, защита от фишинга, модель на основе BERT, адаптивное переобучение