Clear Sky Science · pl
Bezpieczeństwo kodów QR: adaptacyjne przeuczanie dla wykrywania dynamicznych zagrożeń opartych na adresach URL
Dlaczego małe kwadraty mają znaczenie dla twojego bezpieczeństwa
Kody QR po cichu stały się bramami między światem fizycznym a internetem, pozwalając nam przejść do menu, stron płatności, aplikacji i innych zasobów za pomocą jednego skanu. Ale ta sama wygoda, która czyni je użytecznymi, sprawia też, że są atrakcyjnym narzędziem dla przestępców, którzy potrafią ukryć niebezpieczne linki w niewinnie wyglądających czarno-białych kwadratach. Artykuł bada, jak zaawansowany rodzaj sztucznej inteligencji może nauczyć się odróżniać bezpieczne linki z kodów QR od szkodliwych i ciągle się doskonalić, gdy pojawiają się nowe oszustwa.
Od przydatnych skrótów do ukrytych pułapek
W ciągu ostatniej dekady, a zwłaszcza podczas pandemii COVID-19, użycie kodów QR gwałtownie wzrosło, z dziesiątkami milionów skanów w krótkim czasie. Większość tych kodów prowadzi do rutynowych stron internetowych. Jednak napastnicy zauważyli, że ludzie rzadko sprawdzają, dokąd prowadzi kod przed jego zeskanowaniem, i często ufają każdemu kodowi umieszczonemu publicznie lub udostępnionemu przez usługę. Poprzez osadzanie złośliwych adresów internetowych w kodach QR, przestępcy mogą kierować użytkowników na strony phishingowe wykradające hasła lub na witryny, które potajemnie instalują malware. Badanie koncentruje się na tej niewidocznej warstwie — adresie internetowym, czyli URL-u ukrytym w każdym kodzie — ponieważ to on jest prawdziwym nośnikiem ataków, w przeciwieństwie do fizycznego manipulowania wydrukowanym wzorem.
Dlaczego starsze zabezpieczenia zawodzą
Tradycyjne zabezpieczenia próbują blokować szkodliwe linki na dwa główne sposoby. Niektóre polegają na listach znanych złych URL-i, które są proste, lecz łatwe do obejścia, gdy napastnicy zmieniają swoje adresy. Inne wykorzystują uczenie maszynowe trenowane na ręcznie skonstruowanych cechach, takich jak długość URL-a czy obecność określonych symboli lub słów. Metody te mogą działać całkiem dobrze, ale mają tendencję do sztywności i silnie zależą od wzorców widzianych w starych danych. Gdy przestępcy wymyślają nowe triki i różnicują wygląd swoich linków, te stałe modele mają problem z nadążeniem, co prowadzi albo do przeoczeń zagrożeń, albo do zbyt wielu fałszywych alarmów.
Inteligentniejszy czytnik adresów internetowych
Autorzy proponują nowy system oparty na BERT — potężnym modelu AI pierwotnie zaprojektowanym do rozumienia języka naturalnego. Zamiast zdań i akapitów podają BERT-owi ciągi znaków tworzące URL-e. Najpierw system skanuje kod QR i wyodrębnia osadzony w nim adres URL. Następnie URL jest rozbijany na tokeny i przekazywany przez kompaktową wersję BERT-a, która przekształca go w bogatą reprezentację numeryczną wychwytującą subtelne wzorce i relacje w obrębie ciągu. Na tej reprezentacji badacze dodają lekki klasyfikator statystyczny, który decyduje, czy link jest prawdopodobnie bezpieczny, czy złośliwy. Taka konstrukcja pozwala systemowi wyłapywać złożone wskazówki, których prostsze modele nie dostrzegają, mimo że URL-e nie są typowym językiem naturalnym.
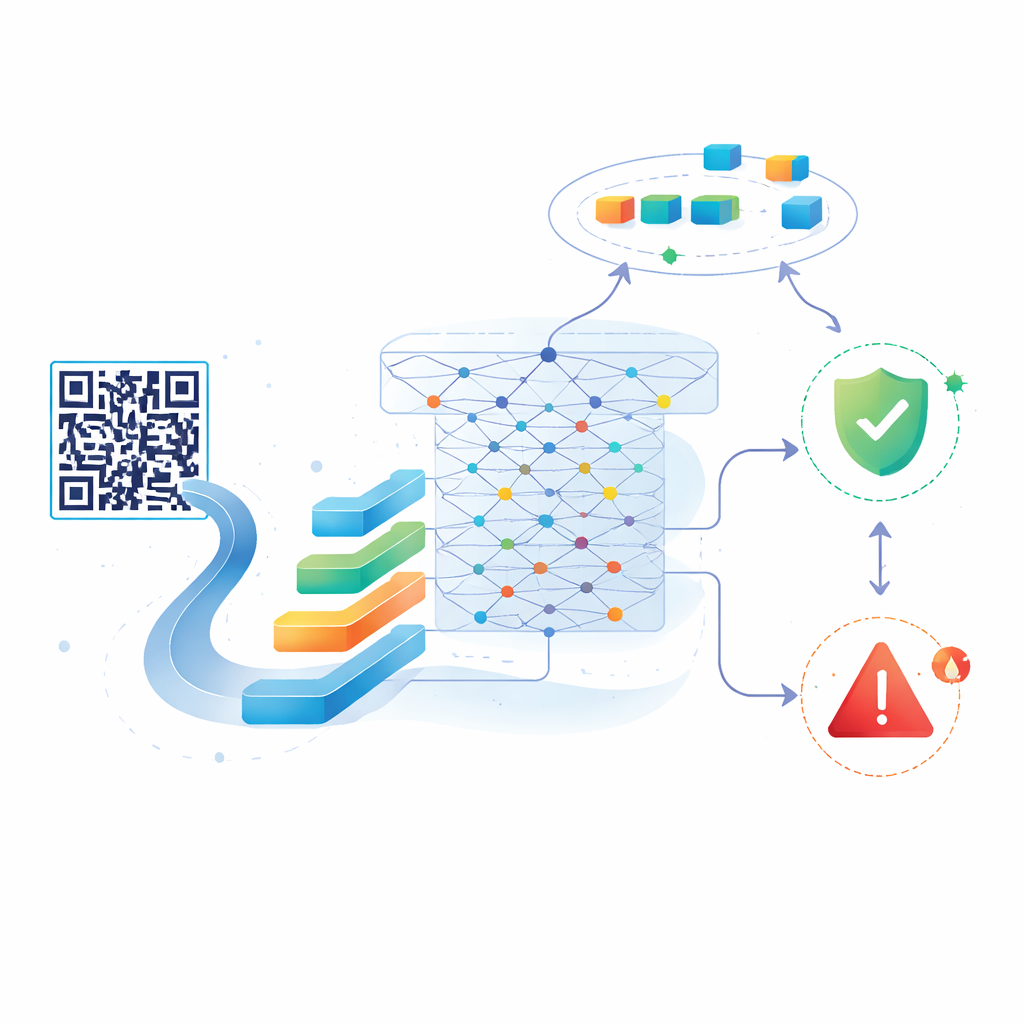
Nauka i ponowna nauka w miarę ewolucji zagrożeń
Kluczową cechą podejścia jest to, że nie pozostaje ono zamrożone po początkowym treningu. Autorzy zaczynają od zrównoważonego zbioru około 20 000 oznaczonych URL-i — część bezpiecznych, część złośliwych — pochodzących z publicznego zbioru danych. Gdy model zostanie dostrojony na tych danych, łączą go z na żywo zasilanym strumieniem nowo odkrywanych złośliwych URL-i z serwisu o nazwie URLhaus i okresowo mieszają te świeże przykłady z dodatkowymi bezpiecznymi linkami. Każda runda ponownego trenowania aktualizuje model tak, by rozpoznawał pojawiające się style ataków, jednocześnie zachowując dotychczasową wiedzę. Testy pokazują, że nawet po wielokrotnych aktualizacjach dokładność pozostaje bardzo wysoka: około 98–99% na oryginalnych danych i około 97% na większych, zaktualizowanych zestawach, a system wykrywa niemal wszystkie złośliwe linki, rzadko oznaczając przypadkowo bezpieczne jako niebezpieczne.
Jak to pomaga zwykłym użytkownikom
Dla laika rezultat jest prosty: kiedy skanujesz kod QR, działająca w tle sztuczna inteligencja może szybko ocenić, czy ukryty link wydaje się godny zaufania. Jeśli wygląda na bezpieczny, zostaniesz przekierowany na stronę; jeśli wydaje się niebezpieczny, możesz otrzymać ostrzeżenie lub zostać zablokowany przed wejściem. Łącząc silny model w stylu językowym z ciągłym przeuczaniem na danych o rzeczywistych atakach, praca ta oferuje elastyczną tarczę, która dostosowuje się, gdy oszuści zmieniają taktykę. Chociaż wymaga to solidnych zasobów obliczeniowych, podejście pokazuje, że inteligentne, ewoluujące filtry mogą uczynić skromny kod QR znacznie bezpieczniejszym wejściem do świata online.
Cytowanie: Almousa, H., Alsuhibany, S.A. QR code security: an adaptive retraining approach for dynamic URL-based threat detection. Sci Rep 16, 13143 (2026). https://doi.org/10.1038/s41598-026-43002-z
Słowa kluczowe: bezpieczeństwo kodów QR, wykrywanie złośliwych adresów URL, ochrona przed phishingiem, model oparty na BERT, adaptacyjne przeuczanie