Clear Sky Science · it
Sicurezza dei codici QR: un approccio di riaddestramento adattivo per il rilevamento dinamico delle minacce basate su URL
Perché i piccoli quadrati contano per la tua sicurezza
I codici QR sono diventati silenziosamente dei passaggi tra il mondo fisico e Internet, permettendoci di accedere a menu, pagine di pagamento, app e altro con una sola scansione. Ma la stessa comodità che li rende utili li rende anche un obiettivo attraente per i criminali, che possono nascondere link web pericolosi all’interno di quadrati in bianco e nero dall’aspetto innocuo. Questo articolo esplora come un tipo avanzato di intelligenza artificiale possa imparare a distinguere i link dei codici QR sicuri da quelli dannosi e a migliorare continuamente man mano che emergono nuove truffe.
Da scorciatoie pratiche a trappole nascoste
Negli ultimi dieci anni, e specialmente durante la pandemia di COVID-19, l’uso dei codici QR è esploso, con decine di milioni di scansioni registrate in breve tempo. La maggior parte di questi codici punta semplicemente a siti web di routine. Tuttavia, gli aggressori hanno capito che le persone raramente verificano dove porta un codice prima di scannerizzarlo e spesso si fidano di qualsiasi codice pubblicato in pubblico o condiviso da un servizio. Inserendo indirizzi web malevoli nei codici QR, i criminali possono indirizzare gli utenti verso pagine di phishing che sottraggono password o verso siti che installano silenziosamente malware. Questo studio si concentra su quello strato invisibile—l’indirizzo web, o URL, nascosto in ogni codice—perché è il vero veicolo degli attacchi, a differenza della manomissione fisica del pattern stampato.
Perché le difese più vecchie non bastano
Le difese tradizionali cercano di bloccare i link dannosi in due modi principali. Alcune si basano su elenchi di URL noti come malevoli, che sono semplici ma facilmente aggirabili non appena gli attaccanti cambiano i loro indirizzi. Altre utilizzano apprendimento automatico addestrato su caratteristiche costruite a mano, come la lunghezza di un URL o la presenza di certi simboli o parole. Questi metodi possono funzionare abbastanza bene, ma tendono a essere rigidi e dipendono fortemente da schemi osservati in dati vecchi. Man mano che i criminali inventano nuovi trucchi e variano l’aspetto dei loro link, questi modelli fissi faticano a stare al passo, portando o a minacce non rilevate o a troppe segnalazioni false.
Un lettore più intelligente per gli indirizzi web
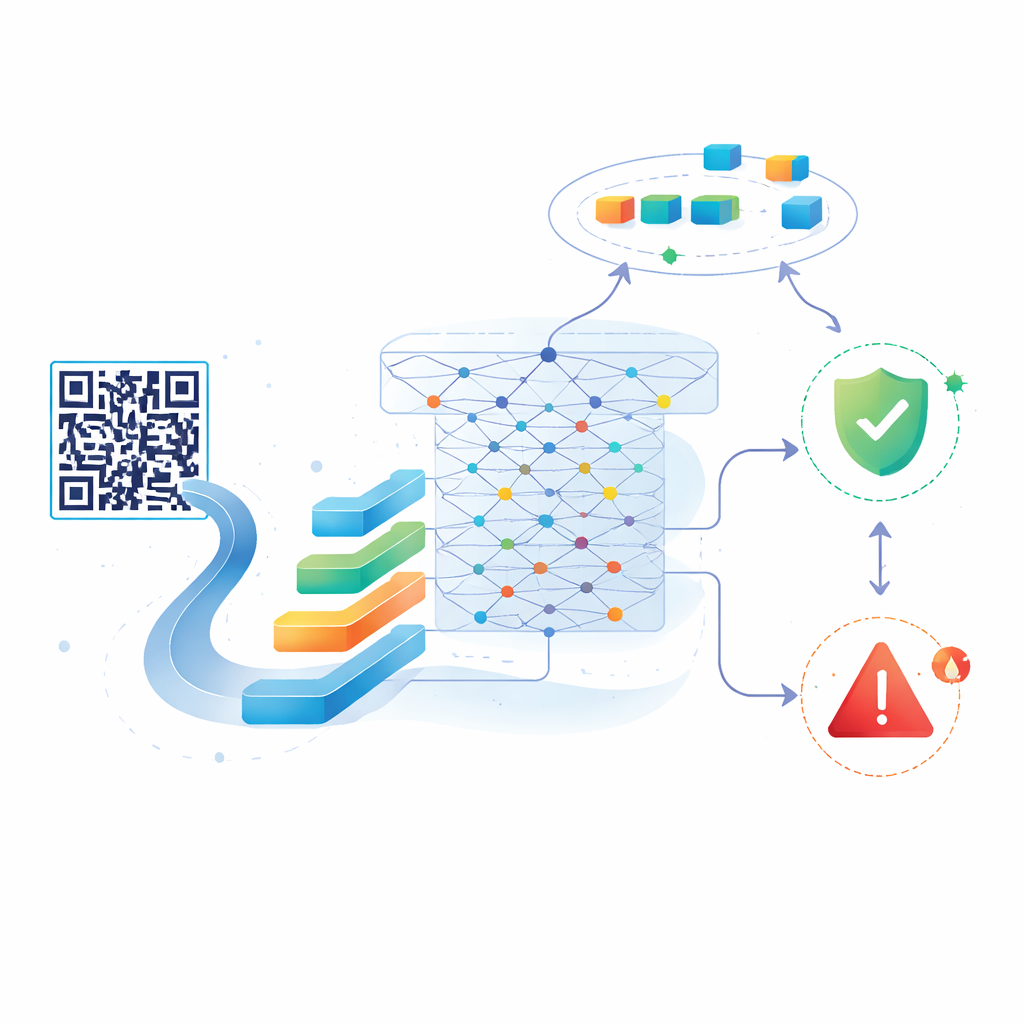
Gli autori propongono un nuovo sistema costruito su BERT, un potente modello di IA originariamente progettato per comprendere il linguaggio naturale. Invece di frasi e paragrafi, alimentano BERT con le stringhe di caratteri che compongono gli URL. Prima, il sistema scansiona un codice QR ed estrae l’URL incorporato. Quell’URL viene quindi suddiviso in token e passato attraverso una versione compatta di BERT, che lo converte in una ricca rappresentazione numerica che cattura schemi e relazioni sottili all’interno della stringa. Sopra questa rappresentazione, i ricercatori aggiungono un classificatore statistico leggero che decide se il link è probabilmente benigno o dannoso. Questo progetto permette al sistema di cogliere segnali complessi che i modelli più semplici perdono, anche se gli URL non sono un linguaggio regolare.
Imparare e reimparare mentre le minacce evolvono
Una caratteristica chiave dell’approccio è che non rimane congelato dopo il primo addestramento. Gli autori partono da una raccolta bilanciata di circa 20.000 URL etichettati—alcuni sicuri, altri dannosi—provenienti da un dataset pubblico. Una volta che il modello è tarato su questi dati, lo collegano a un flusso live di nuovi URL dannosi scoperti da un servizio chiamato URLhaus e di tanto in tanto mescolano questi esempi freschi con link sicuri aggiuntivi. Ogni ciclo di riaddestramento aggiorna il modello per far sì che possa riconoscere stili di attacco emergenti preservando quanto già appreso. I test mostrano che anche dopo aggiornamenti ripetuti l’accuratezza rimane molto alta: circa 98–99% sui dati originali e circa 97% su set più ampi e aggiornati, con il sistema che rileva quasi tutti i link dannosi segnalando raramente quelli sicuri per errore.
Come questo aiuta gli utenti comuni
Per un non esperto, il risultato è semplice: quando scansionate un codice QR, un’IA dietro le quinte può decidere rapidamente se il link nascosto sembra affidabile. Se appare sicuro, verrete indirizzati al sito; se sembra pericoloso, potreste ricevere un avviso o essere bloccati dall’accesso. Combinando un robusto modello in stile linguistico con un continuo riaddestramento su dati di attacco reali, questo lavoro offre uno scudo flessibile che si adatta mentre i truffatori cambiano tattiche. Sebbene richieda risorse computazionali solide, l’approccio mostra che filtri intelligenti e in evoluzione possono rendere il modesto codice QR una porta molto più sicura verso il mondo online.
Citazione: Almousa, H., Alsuhibany, S.A. QR code security: an adaptive retraining approach for dynamic URL-based threat detection. Sci Rep 16, 13143 (2026). https://doi.org/10.1038/s41598-026-43002-z
Parole chiave: Sicurezza dei codici QR, rilevamento di URL dannosi, protezione dal phishing, modello basato su BERT, riaddestramento adattivo