Clear Sky Science · de
QR-Code-Sicherheit: ein adaptiver Retraining-Ansatz zur dynamischen Erkennung URL-basierter Bedrohungen
Warum winzige Quadrate für Ihre Sicherheit wichtig sind
QR-Codes sind still und leise zu Toren zwischen der physischen Welt und dem Internet geworden: Mit einem einzigen Scan gelangen wir zu Menüs, Bezahlseiten, Apps und mehr. Dieselbe Bequemlichkeit, die sie so nützlich macht, macht sie jedoch auch attraktiv für Kriminelle, die gefährliche Weblinks in harmlos aussehenden schwarz-weißen Quadraten verbergen können. Dieses Papier untersucht, wie eine fortgeschrittene Form künstlicher Intelligenz lernen kann, sichere QR-Code-Links von schädlichen zu unterscheiden und sich weiter zu verbessern, wenn neue Betrugsformen auftauchen.
Von praktischen Abkürzungen zu versteckten Fallen
In den letzten zehn Jahren, und besonders während der COVID-19-Pandemie, hat die Nutzung von QR-Codes explosionsartig zugenommen, mit zig Millionen Scans in kurzer Zeit. Die meisten dieser Codes verweisen lediglich auf alltägliche Websites. Angreifer haben jedoch erkannt, dass Nutzer selten prüfen, wohin ein Code führt, bevor sie ihn scannen, und oft jedem öffentlich geteilten Code vertrauen. Indem sie bösartige Webadressen in QR-Codes einbetten, können Kriminelle Nutzer auf Phishing-Seiten leiten, die Passwörter stehlen, oder auf Seiten, die heimlich Malware installieren. Diese Studie konzentriert sich auf jene unsichtbare Ebene — die Webadresse bzw. URL, die in jedem Code verborgen ist — denn sie ist das eigentliche Trägermaterial für Angriffe, anders als physische Manipulationen am gedruckten Muster.
Warum ältere Verteidigungen versagen
Traditionelle Abwehrmethoden versuchen, schädliche Links auf zwei Hauptwegen zu blockieren. Einige stützen sich auf Listen bekannter schadhafter URLs, die einfach sind, aber leicht umgangen werden, sobald Angreifer ihre Adressen ändern. Andere verwenden maschinelles Lernen, das auf handverlesenen Merkmalen trainiert wurde, etwa der Länge einer URL oder ob sie bestimmte Zeichen oder Wörter enthält. Diese Methoden können einigermaßen funktionieren, sind aber oft starr und stark von Mustern abhängig, die in historischen Daten vorkommen. Wenn Kriminelle neue Tricks erfinden und das Aussehen ihrer Links variieren, tun sich diese festen Modelle schwer, Schritt zu halten, was entweder zu übersehenen Bedrohungen oder zu vielen Fehlalarmen führt.
Ein schlauerer Leser für Webadressen
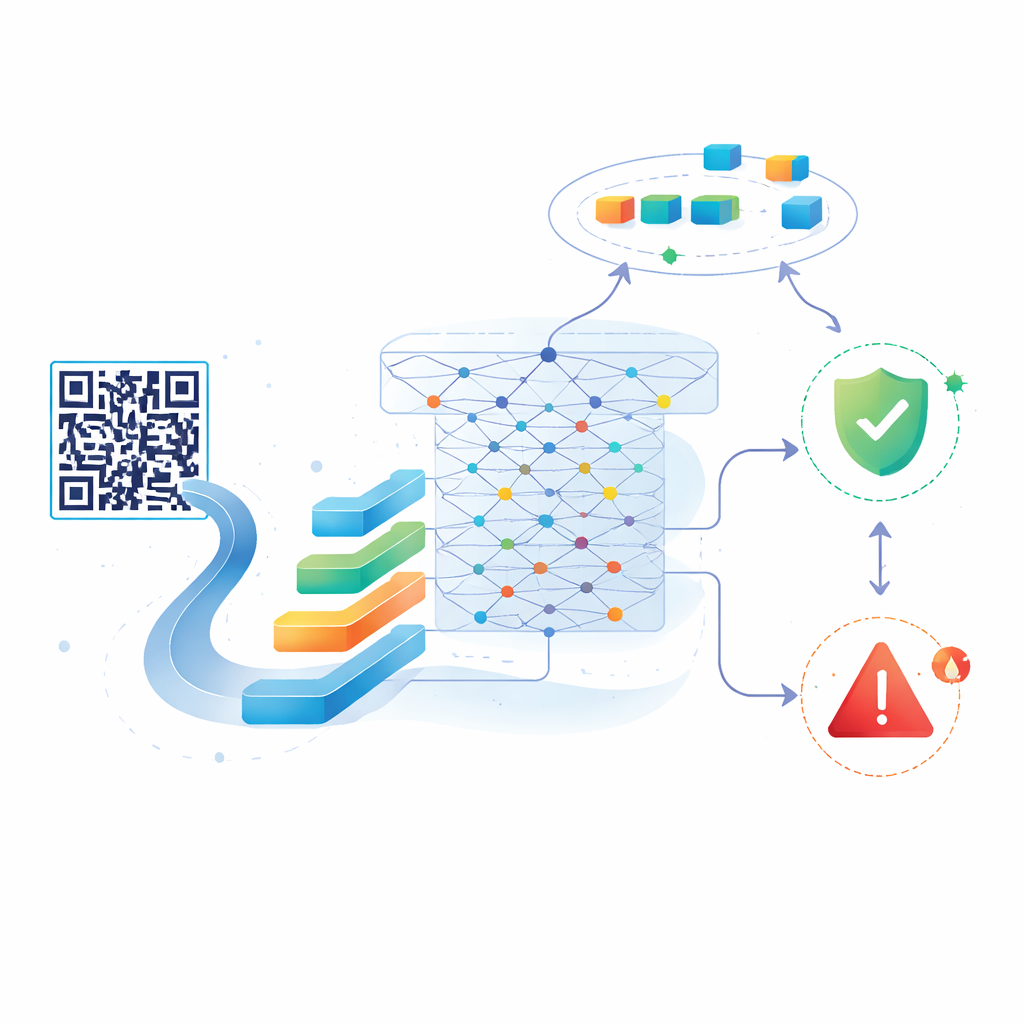
Die Autoren schlagen ein neues System vor, das auf BERT aufbaut, einem mächtigen KI-Modell, das ursprünglich zur Verarbeitung natürlicher Sprache entwickelt wurde. Statt Sätzen und Absätzen füttern sie BERT mit den Zeichenfolgen, die URLs bilden. Zunächst scannt das System einen QR-Code und extrahiert die darin eingebettete URL. Diese URL wird dann in Token zerlegt und durch eine kompakte Version von BERT geleitet, die sie in eine dichte numerische Repräsentation umwandelt, welche subtile Muster und Beziehungen innerhalb der Zeichenfolge erfasst. Auf dieser Repräsentation bauen die Forschenden einen leichten statistischen Klassifikator auf, der entscheidet, ob der Link wahrscheinlich harmlos oder bösartig ist. Dieses Design erlaubt es dem System, komplexe Hinweise zu erkennen, die einfachere Modelle übersehen, obwohl URLs keine reguläre Sprache sind.
Lernen und Wiederlernen, während sich Bedrohungen entwickeln
Ein Schlüsselfeature des Ansatzes ist, dass er nach dem ersten Training nicht eingefroren bleibt. Die Autoren beginnen mit einer ausgewogenen Sammlung von etwa 20.000 gelabelten URLs — einige sicher, einige bösartig — aus einem öffentlichen Datensatz. Nachdem das Modell an diesen Daten feinabgestimmt wurde, koppeln sie es an einen Live-Feed neu entdeckter schädlicher URLs von einem Dienst namens URLhaus und mischen diese frischen Beispiele periodisch mit zusätzlichen sicheren Links. Jede Retraining-Runde aktualisiert das Modell, sodass es aufkommende Angriffsarten erkennen kann, während bereits erlerntes Wissen erhalten bleibt. Tests zeigen, dass die Genauigkeit auch nach wiederholten Aktualisierungen sehr hoch bleibt: rund 98–99 % auf den Originaldaten und etwa 97 % auf größeren, aktualisierten Sets, wobei das System fast alle bösartigen Links erkennt und nur selten harmlose fälschlicherweise als gefährlich einstuft.
Wie das dem Alltag der Nutzer hilft
Für Laien ist das Ergebnis einfach: Wenn Sie einen QR-Code scannen, kann eine im Hintergrund arbeitende KI schnell entscheiden, ob der versteckte Link vertrauenswürdig wirkt. Wirkt er sicher, werden Sie zur Website weitergeleitet; wirkt er gefährlich, können Sie gewarnt oder am Besuch gehindert werden. Durch die Kombination eines leistungsfähigen, sprachähnlichen Modells mit kontinuierlichem Retraining auf realen Angriffsdatensätzen bietet diese Arbeit einen flexiblen Schutz, der sich anpasst, wenn Betrüger ihre Taktiken ändern. Obwohl der Ansatz solide Rechenressourcen verlangt, zeigt er, dass intelligente, sich entwickelnde Filter den unscheinbaren QR-Code zu einer deutlich sichereren Pforte in die Online-Welt machen können.
Zitation: Almousa, H., Alsuhibany, S.A. QR code security: an adaptive retraining approach for dynamic URL-based threat detection. Sci Rep 16, 13143 (2026). https://doi.org/10.1038/s41598-026-43002-z
Schlüsselwörter: QR-Code-Sicherheit, Erkennung bösartiger URLs, Phishing-Schutz, BERT-basiertes Modell, adaptives Retraining