Clear Sky Science · fr
Sécurité des codes QR : une approche de réentraînement adaptatif pour la détection dynamique de menaces basées sur les URL
Pourquoi ces petits carrés comptent pour votre sécurité
Les codes QR sont devenus, discrètement, des passerelles entre le monde physique et Internet, nous permettant d’accéder à des menus, des pages de paiement, des applications et bien plus d’un seul scan. Mais la même commodité qui les rend utiles en fait aussi un outil attractif pour les criminels, qui peuvent dissimuler des liens Web dangereux dans ces carrés noir et blanc apparemment inoffensifs. Cet article explore comment une forme avancée d’intelligence artificielle peut apprendre à distinguer les liens de codes QR sûrs des liens malveillants, et continuer à s’améliorer au fur et à mesure que de nouvelles arnaques apparaissent.
Des raccourcis pratiques aux pièges dissimulés
Au cours de la dernière décennie, et particulièrement pendant la pandémie de COVID-19, l’utilisation des codes QR a explosé, avec des dizaines de millions de scans enregistrés en peu de temps. La plupart de ces codes renvoient à des sites Web routiniers. Cependant, les attaquants ont compris que les gens vérifient rarement la destination d’un code avant de le scanner et font souvent confiance à tout code affiché en public ou partagé par un service. En intégrant des adresses Web malveillantes dans des codes QR, les criminels peuvent diriger les utilisateurs vers des pages de phishing qui volent des mots de passe, ou vers des sites qui installent discrètement des logiciels malveillants. Cette étude se concentre sur cette couche invisible — l’adresse Web, ou URL, cachée dans chaque code — car c’est le véritable vecteur d’attaque, contrairement à la falsification physique du motif imprimé.
Pourquoi les défenses anciennes montrent leurs limites
Les défenses traditionnelles cherchent à bloquer les liens dangereux de deux façons principales. Certaines s’appuient sur des listes d’URL connues comme mauvaises, simples mais facilement contournées dès que les attaquants changent leurs adresses. D’autres utilisent des méthodes d’apprentissage automatique entraînées sur des caractéristiques conçues manuellement, comme la longueur d’une URL ou la présence de certains symboles ou mots. Ces méthodes peuvent fonctionner raisonnablement bien, mais elles tendent à être rigides et dépendent fortement de motifs vus dans des données anciennes. À mesure que les criminels inventent de nouvelles ruses et varient l’apparence de leurs liens, ces modèles fixes peinent à suivre, ce qui entraîne soit des menaces manquées soit trop de faux positifs.
Un lecteur plus intelligent pour les adresses Web
Les auteurs proposent un nouveau système construit sur BERT, un modèle d’IA puissant initialement conçu pour comprendre le langage naturel. Au lieu de phrases et de paragraphes, ils donnent à BERT les chaînes de caractères qui composent les URL. D’abord, le système scanne un code QR et extrait l’URL intégrée. Cette URL est ensuite découpée en tokens et passée à une version compacte de BERT, qui la convertit en une représentation numérique riche capturant des motifs et des relations subtiles à l’intérieur de la chaîne. Sur cette représentation, les chercheurs ajoutent un classifieur statistique léger qui décide si le lien est probablement bénin ou malveillant. Cette conception permet au système de repérer des indices complexes que des modèles plus simples manquent, même si les URL ne constituent pas un langage régulier.
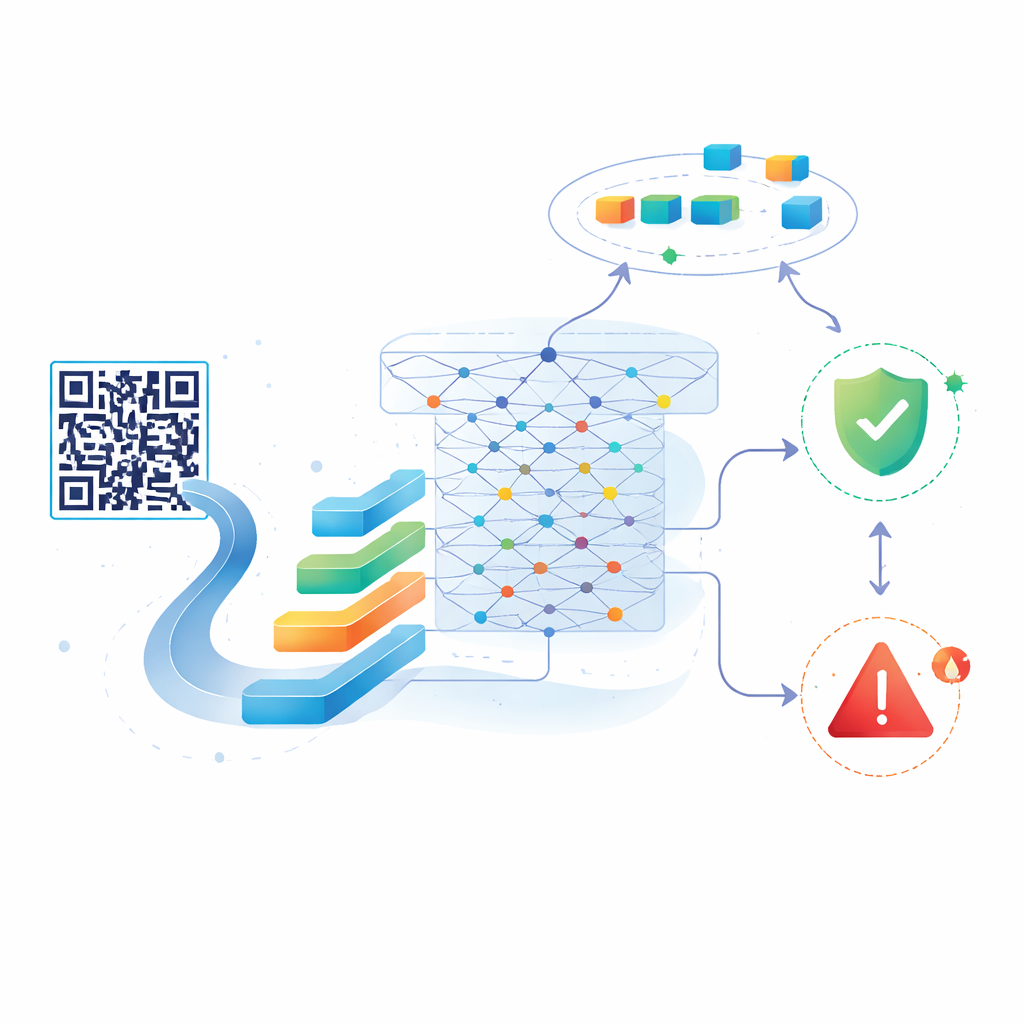
Apprendre et réapprendre à mesure que les menaces évoluent
Une caractéristique clé de l’approche est qu’elle ne reste pas figée après son premier entraînement. Les auteurs partent d’un ensemble équilibré d’environ 20 000 URL étiquetées — certaines sûres, d’autres malveillantes — provenant d’un jeu de données public. Une fois le modèle ajusté sur ces données, ils le connectent à un flux en direct d’URL malveillantes récemment découvertes via un service appelé URLhaus, et mélangent périodiquement ces exemples frais avec des liens sûrs supplémentaires. Chaque cycle de réentraînement met à jour le modèle pour qu’il puisse reconnaître les styles d’attaque émergents tout en préservant ce qu’il a déjà appris. Les tests montrent que même après des mises à jour répétées, la précision reste très élevée : autour de 98–99 % sur les données initiales et environ 97 % sur des ensembles plus grands et mis à jour, le système capturant presque toutes les URL malveillantes tout en signalant rarement par erreur des liens sûrs.
Comment cela aide les utilisateurs au quotidien
Pour un non-spécialiste, le résultat est simple : lorsque vous scannez un code QR, une IA en coulisses peut rapidement décider si le lien caché semble digne de confiance. S’il paraît sûr, vous êtes redirigé vers le site ; s’il paraît dangereux, vous pouvez recevoir une alerte ou être empêché d’y accéder. En combinant un modèle de style linguistique puissant avec un réentraînement continu sur des données d’attaque réelles, ce travail propose un bouclier flexible qui s’adapte au fur et à mesure que les arnaqueurs changent de tactique. Bien que cela exige des ressources de calcul conséquentes, l’approche montre que des filtres intelligents et évolutifs peuvent rendre le modeste code QR bien plus sûr comme porte d’accès au monde en ligne.
Citation: Almousa, H., Alsuhibany, S.A. QR code security: an adaptive retraining approach for dynamic URL-based threat detection. Sci Rep 16, 13143 (2026). https://doi.org/10.1038/s41598-026-43002-z
Mots-clés: Sécurité des codes QR, détection d’URL malveillantes, protection contre le phishing, modèle basé sur BERT, réentraînement adaptatif