Clear Sky Science · pt
Incorporação multimodal parcialmente compartilhada aprende representação holística do estado celular
Por que este estudo importa
Cada célula do nosso corpo é um pequeno universo, e ferramentas modernas já conseguem observar esse universo por vários ângulos ao mesmo tempo — lendo genes, mapeando o empacotamento do DNA ou imageando proteínas. Ainda assim, a maioria dos métodos computacionais mistura essas visões de forma que fica difícil saber qual medição é responsável por cada insight. Este artigo apresenta o APOLLO, uma nova forma de combinar dados celulares diversos que rastreia o que é compartilhado entre as medições e o que é único a cada uma, oferecendo uma imagem mais clara e holística do comportamento celular.
Vendo células por muitas lentes
A biologia atual rotineiramente mede vários tipos de informação da mesma célula: quais genes estão ativados, quão compactado está o DNA, quais proteínas decoram a superfície ou onde proteínas específicas se localizam dentro da célula. Cada “modalidade” captura apenas parte do estado celular real. Alguns aspectos, como o tipo celular amplo, podem aparecer em todas as modalidades, enquanto outros — como o empacotamento fino da cromatina ou a localização de uma proteína específica — podem surgir apenas em uma. Métodos computacionais existentes ou analisam cada modalidade separadamente, ou as fundem numa única representação mista. Em ambos os casos, os cientistas têm dificuldade em distinguir quais características vêm de qual medição e em prever o que uma medição ausente teria mostrado.
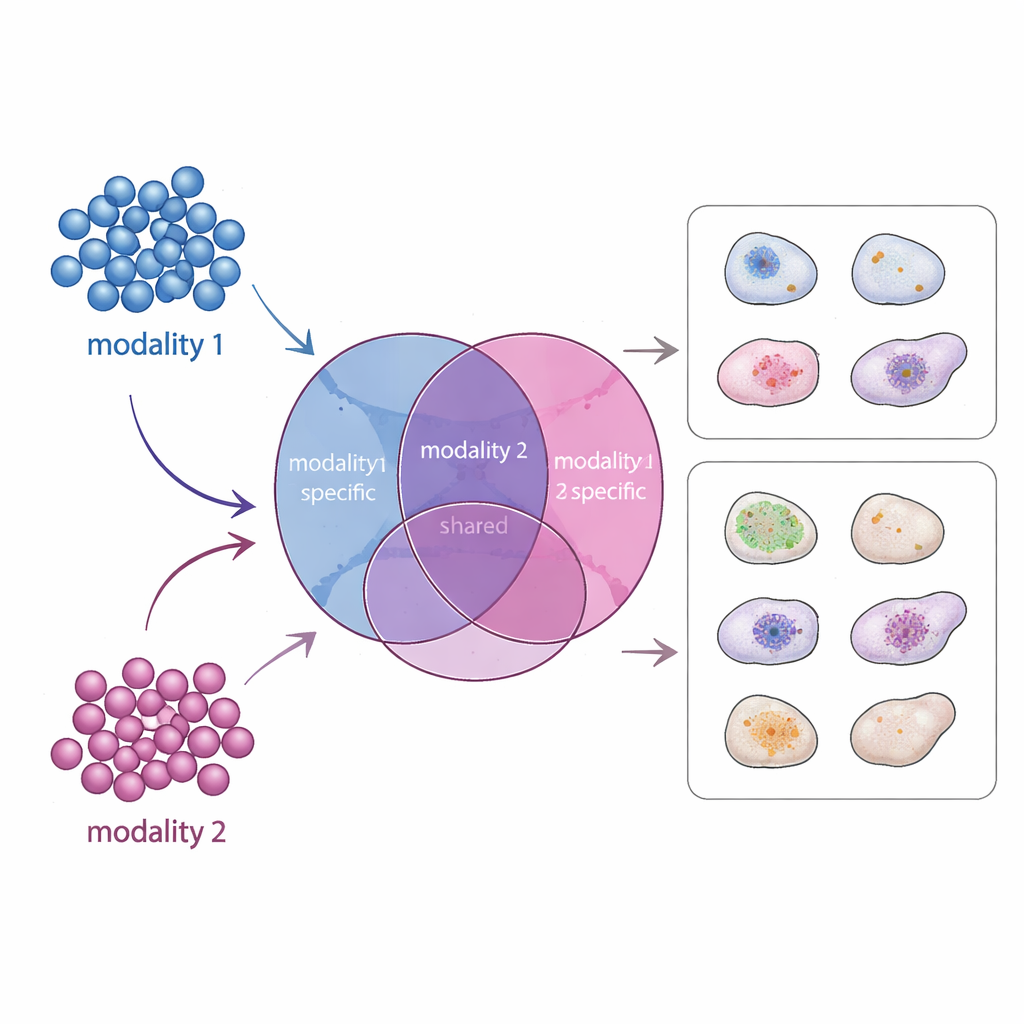
Um novo mapa de sinais compartilhados e únicos
APOLLO aborda esse problema aprendendo um mapa interno estruturado de cada célula. Em vez de um resumo indiferenciado, ele divide a informação em três partes: um componente compartilhado que reflete o que diferentes medições têm em comum, e dois componentes específicos de modalidade que capturam o que é único a cada tipo de dado. Por baixo do capô, o APOLLO usa uma família de redes neurais chamadas autoencoders. Numa primeira etapa de treinamento, trata a representação interna de cada célula como um conjunto de parâmetros ajustáveis e os afina conjuntamente com redes decodificadoras para que cada modalidade possa ser reconstruída com precisão. Numa segunda etapa, treina redes codificadoras que podem inferir essas mesmas representações internas a partir de novos dados, permitindo que o método generalize para células não vistas e realize predição entre modalidades.
Testando o método em dados simulados e reais
Os autores primeiro avaliaram o APOLLO em conjuntos de dados simulados cuidadosamente projetados, onde a estrutura subjacente verdadeira é conhecida. Em vários cenários, incluindo aqueles em que fatores compartilhados e específicos de modalidade estão estatisticamente entrelaçados, o APOLLO os separa com sucesso nos compartimentos pretendidos. Em seguida, aplicam o método a dados pareados de expressão gênica e acessibilidade da cromatina em pele de camundongo, a dados que emparelham expressão gênica com níveis de proteínas de superfície em células imunes, e a imagens celulares altamente multiplexadas. Nesses conjuntos de dados reais, o espaço compartilhado captura temas biológicos centrais, como reguladores-chave que definem o tipo celular, enquanto os espaços específicos de modalidade destacam camadas adicionais, como o estado do ciclo celular ou efeitos de lote que são únicos a uma medição.
Prevendo imagens faltantes e revelando a estrutura celular
Uma aplicação notável usa imagens de células imunes de pacientes com câncer. Ali, cada célula tem uma coloração de DNA e uma ou várias colorações de proteínas, mas nem todas as proteínas são medidas em cada célula. O APOLLO aprende como padrões na organização da cromatina se relacionam com a localização de proteínas e então pode prever como uma proteína não medida apareceria em uma célula dada, baseando-se apenas em sua imagem de cromatina. Essas imagens de proteína previstas são realistas o suficiente para que um classificador separado, treinado para distinguir diagnósticos de pacientes, tenha desempenho quase tão bom nelas quanto em imagens reais. Em outro grande recurso de imagens, o Human Protein Atlas, o APOLLO desvenda como as formas do núcleo, da rede de microtúbulos e do retículo endoplasmático estão ligadas aos locais onde as proteínas residem dentro da célula. Para algumas proteínas, a variação na textura nuclear é a mais informativa; para outras, predominam características do arcabouço celular circundante.
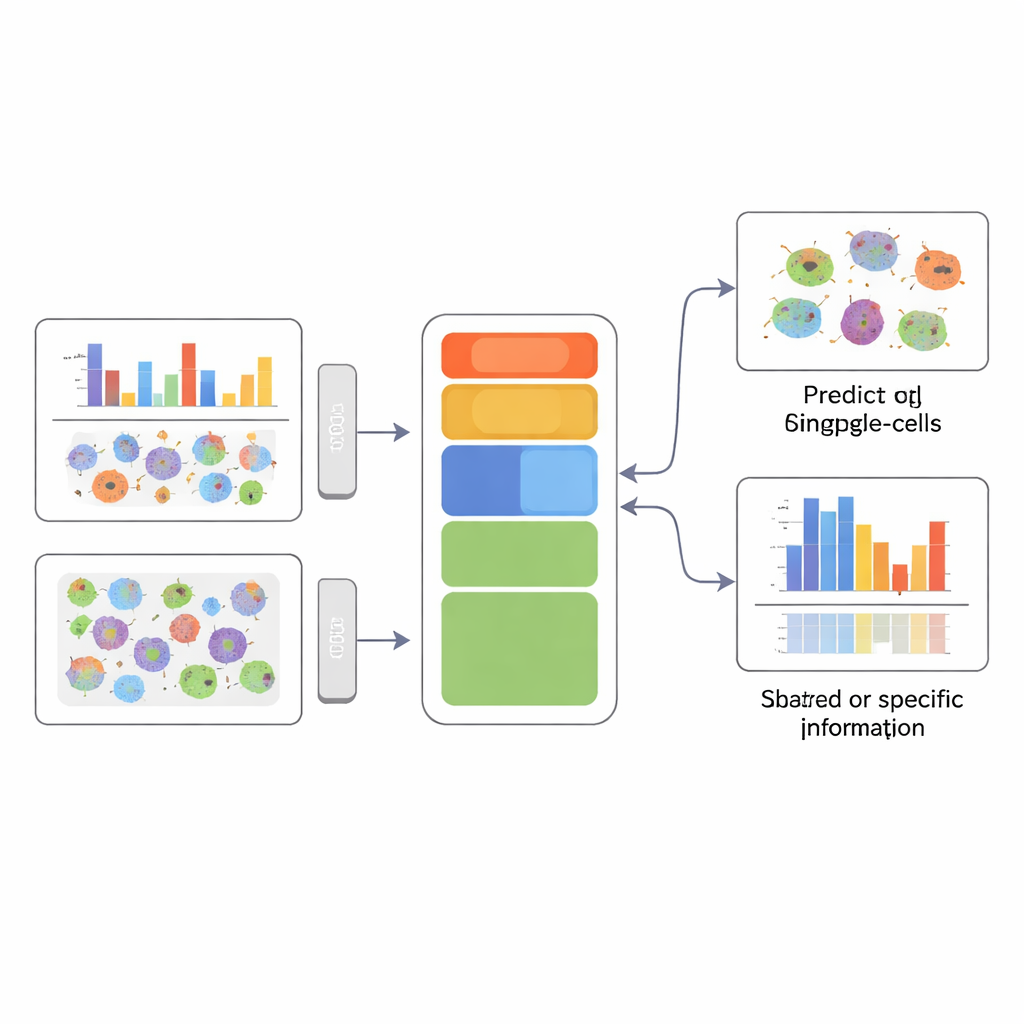
Uma imagem mais clara da identidade celular
Para um não especialista, a mensagem central é que o APOLLO permite aos cientistas combinar muitas medições diferentes das mesmas células sem perder de vista qual medição explica o quê. Ao separar explicitamente a informação compartilhada da específica da modalidade, o método pode tanto prever dados ausentes — como imagens de proteínas não medidas — quanto destacar qual compartimento celular ou tipo de dado está realmente ligado a um dado fenótipo, como estado de doença ou relocalização de proteína. Essa capacidade de formar um resumo estruturado e interpretável de cada célula estabelece bases para diagnósticos mais precisos e uma compreensão mecanicista mais profunda de como diferentes camadas da biologia atuam em conjunto.
Citação: Zhang, X., Shivashankar, G.V. & Uhler, C. Partially shared multi-modal embedding learns holistic representation of cell state. Nat Comput Sci 6, 285–300 (2026). https://doi.org/10.1038/s43588-025-00948-w
Palavras-chave: multi-ômica de célula única, aprendizado de representação, estado celular, localização de proteínas, imagem de cromatina