Clear Sky Science · de
Teilweise geteilte multimodale Einbettung lernt eine ganzheitliche Repräsentation des Zellzustands
Warum diese Studie wichtig ist
Jede Zelle in unserem Körper ist ein winziges Universum, und moderne Werkzeuge können dieses Universum inzwischen gleichzeitig aus vielen Blickwinkeln beobachten — durch Ablesen von Genen, Kartierung der DNA-Paketierung oder Bildgebung von Proteinen. Die meisten rechnerischen Methoden vermischen diese Sichten jedoch so, dass es schwer wird nachzuvollziehen, welche Messung für welche Einsicht verantwortlich ist. Dieses Paper stellt APOLLO vor, eine neue Methode zur Kombination unterschiedlicher Zell‑Daten, die festhält, was zwischen Messungen geteilt wird und was jeweils einzigartig ist, und so ein klareres, ganzheitlicheres Bild des Zellverhaltens liefert.
Zellen durch viele Linsen sehen
Die heutige Biologie misst routinemäßig mehrere Informationsarten aus derselben Zelle: welche Gene aktiviert sind, wie dicht die DNA verpackt ist, welche Proteine die Oberfläche schmücken oder wo sich bestimmte Proteine innerhalb der Zelle befinden. Jede „Modalität“ erfasst nur einen Teil des wahren Zellzustands. Manche Aspekte, wie ein breiter Zelltyp, können in allen Modalitäten auftreten, andere — etwa feingranulare DNA‑Paketierung oder der Standort eines bestimmten Proteins — nur in einer. Bestehende rechnerische Ansätze analysieren Modalitäten entweder getrennt oder verschmelzen sie zu einer einzigen gemischten Repräsentation. In beiden Fällen haben Forschende Schwierigkeiten nachzuvollziehen, welche Merkmale aus welcher Messung stammen, und zu prognostizieren, was eine fehlende Messung gezeigt hätte.
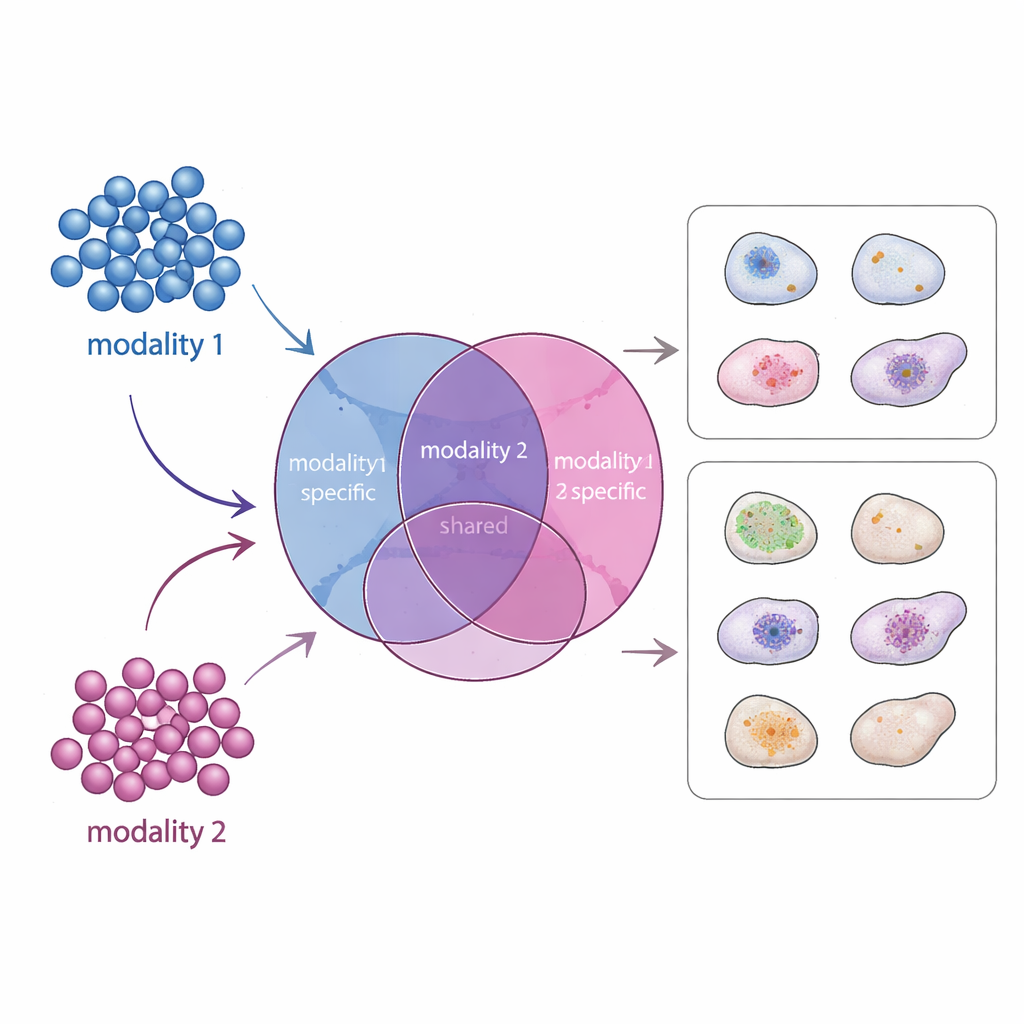
Eine neue Karte gemeinsamer und einzigartiger Signale
APOLLO geht dieses Problem an, indem es eine strukturierte interne Karte jeder Zelle lernt. Statt einer undifferenzierten Zusammenfassung teilt es Informationen in drei Teile: eine gemeinsame Komponente, die widerspiegelt, was verschiedene Messungen teilen, und zwei modalitätsspezifische Komponenten, die das erfassen, was für jeden Datentyp einzigartig ist. Im Hintergrund nutzt APOLLO eine Familie neuronaler Netze, sogenannte Autoencoder. In einem ersten Trainingsschritt behandelt es die interne Repräsentation jeder Zelle als eine Menge anpassbarer Parameter und stimmt diese gemeinsam mit den Decoder‑Netzen so ab, dass jede Modalität genau rekonstruiert werden kann. In einem zweiten Schritt trainiert es Encoder‑Netze, die diese internen Repräsentationen aus neuen Daten inferieren können, wodurch die Methode auf ungesehene Zellen verallgemeinert und Vorhersagen über Modalitäten hinweg gemacht werden können.
Test der Methode an simulierten und realen Daten
Die Autoren benchmarken APOLLO zunächst an sorgfältig entworfenen simulierten Datensätzen, in denen die wahre zugrunde liegende Struktur bekannt ist. In mehreren Szenarien, auch solchen, in denen gemeinsame und modalitätsspezifische Faktoren statistisch verwoben sind, trennt APOLLO sie erfolgreich in die vorgesehenen Bereiche. Anschließend wenden sie die Methode auf gepaarte Genexpressions‑ und Chromatin‑Zugänglichkeitsdaten aus der Maus‑Haut, auf Daten, die Genexpression mit Oberflächenproteinleveln in Immunzellen koppeln, und auf hochmultiplexe Zellbilder an. In diesen realen Datensätzen erfasst der gemeinsame Raum zentrale biologische Themen, etwa Schlüsselfaktoren, die den Zelltyp definieren, während die modalitätsspezifischen Räume zusätzliche Ebenen hervorheben, wie Zellzyklusstatus oder Batch‑Effekte, die für eine Messung einzigartig sind.
Fehlende Bilder vorhersagen und Zellstruktur aufdecken
Eine eindrückliche Anwendung verwendet Bildgebung von Immunzellen aus Krebspatienten. Hier hat jede Zelle eine DNA‑Färbung und eine oder mehrere Protein‑Färbungen, aber nicht alle Proteine werden in jeder Zelle gemessen. APOLLO lernt, wie Muster in der Chromatinorganisation mit der Proteinlokalisierung zusammenhängen, und kann dann vorhersagen, wie ein nicht gemessenes Protein in einer gegebenen Zelle aussehen würde — allein auf Basis ihres Chromatinbildes. Diese vorhergesagten Proteinbilder sind so realistisch, dass ein separater Klassifikator, der auf die Unterscheidung von Patientendiagnosen trainiert wurde, mit ihnen fast genauso gut arbeitet wie mit echten Bildern. In einer weiteren großen Bilddatenbank, dem Human Protein Atlas, disentangled APOLLO, wie Form von Zellkern, Mikrotubuli‑Netzwerk und endoplasmatischem Retikulum damit zusammenhängen, wo Proteine innerhalb der Zelle lokalisiert sind. Für einige Proteine sind Variationen in der Kerntextur am aussagekräftigsten; für andere dominieren Merkmale des umgebenden Zellgerüsts.
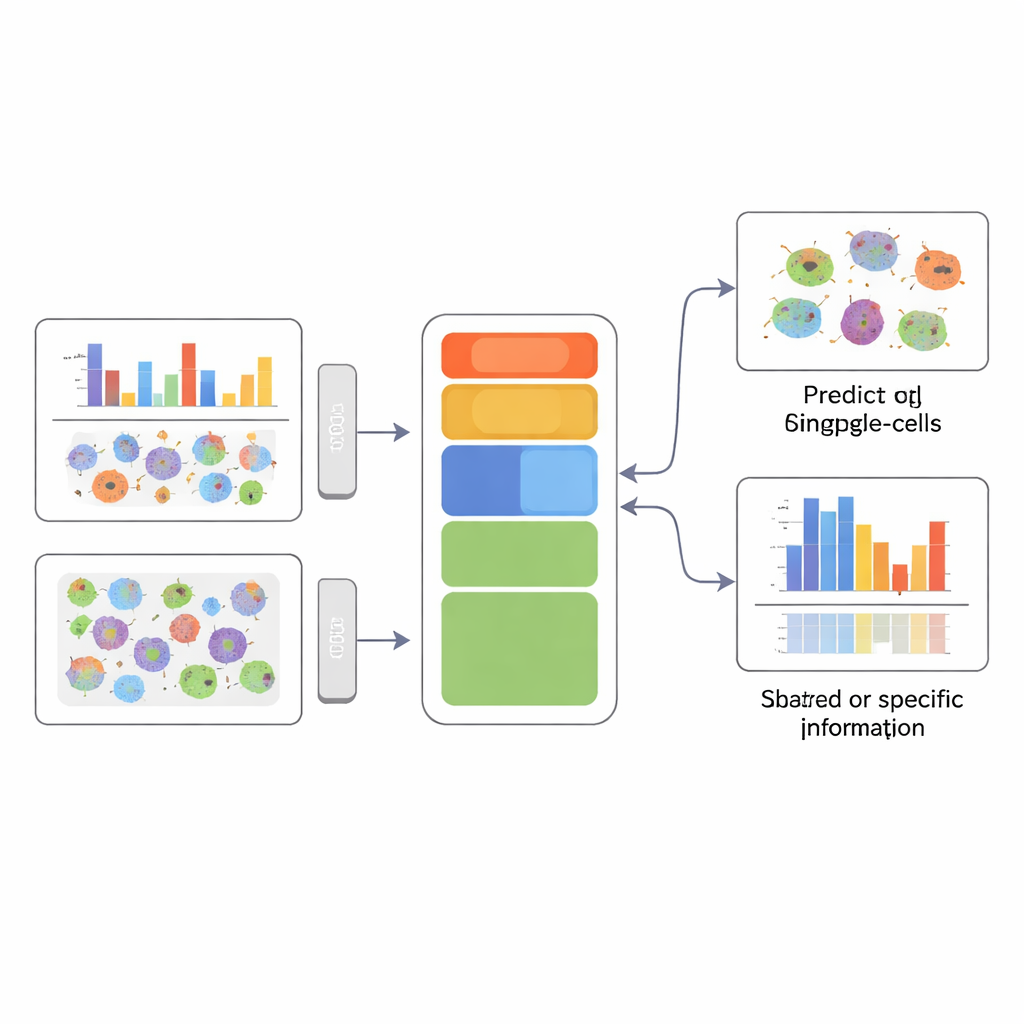
Ein klareres Bild der Zellidentität
Für Nicht‑Spezialisten lautet die Kernbotschaft: APOLLO ermöglicht es Forschenden, viele verschiedene Messungen derselben Zellen zu kombinieren, ohne die Nachverfolgbarkeit zu verlieren, welche Messung was erklärt. Durch die explizite Trennung von gemeinsamen und modalitätsspezifischen Informationen kann die Methode sowohl fehlende Daten vorhersagen — etwa nicht gemessene Proteinbilder — als auch hervorheben, welcher zelluläre Kompartiment oder Datentyp wirklich mit einem bestimmten Phänotyp verbunden ist, etwa Krankheitsstatus oder Proteinumlokalisierung. Diese Fähigkeit, eine strukturierte, interpretierbare Zusammenfassung jeder Zelle zu bilden, legt die Grundlage für präzisere Diagnostik und ein tieferes mechanistisches Verständnis dafür, wie verschiedene biologischen Ebenen zusammenwirken.
Zitation: Zhang, X., Shivashankar, G.V. & Uhler, C. Partially shared multi-modal embedding learns holistic representation of cell state. Nat Comput Sci 6, 285–300 (2026). https://doi.org/10.1038/s43588-025-00948-w
Schlüsselwörter: Single-Cell-Multi-Omics, Repräsentationslernen, Zellzustand, Proteinlokalisierung, Chromatinbildgebung