Clear Sky Science · nl
Gedeeltelijk gedeelde multimodale embedding leert holistische representatie van celtoestand
Waarom deze studie ertoe doet
Elke cel in ons lichaam is een klein universum, en moderne instrumenten kunnen dat universum nu vanuit meerdere invalshoeken tegelijk observeren — door genexpressie te meten, de DNA-verpakking in kaart te brengen of eiwitten te fotograferen. Toch mengen de meeste computationele methoden deze gezichtspunten op een manier die het moeilijk maakt te achterhalen welke meting verantwoordelijk is voor welk inzicht. Dit artikel introduceert APOLLO, een nieuwe manier om uiteenlopende celdata te combineren die bijhoudt wat tussen metingen gedeeld is en wat uniek is voor elke modaliteit, en zo een helderder, meer holistisch beeld van celgedrag biedt.
Cellen bekijken met meerdere lenzen
De hedendaagse biologie meet routinematig verschillende soorten informatie van dezelfde cel: welke genen actief zijn, hoe strak DNA opgerold is, welke eiwitten het celoppervlak sieren, of waar specifieke eiwitten binnen de cel zitten. Elke “modaliteit” legt slechts een deel van de werkelijke celtoestand vast. Sommige aspecten, zoals de brede celsoort, kunnen in alle modaliteiten terugkomen, terwijl andere — zoals fijnmazige DNA-verpakking of de locatie van een bepaald eiwit — alleen in één modaliteit voorkomen. Bestaande computationele methoden analyseren ofwel elke modaliteit afzonderlijk, of ze fusen alles in één gemengde representatie. In beide gevallen worstelen wetenschappers ermee te bepalen welke kenmerken uit welke meting voortkomen en om te voorspellen wat een ontbrekende meting zou hebben laten zien.
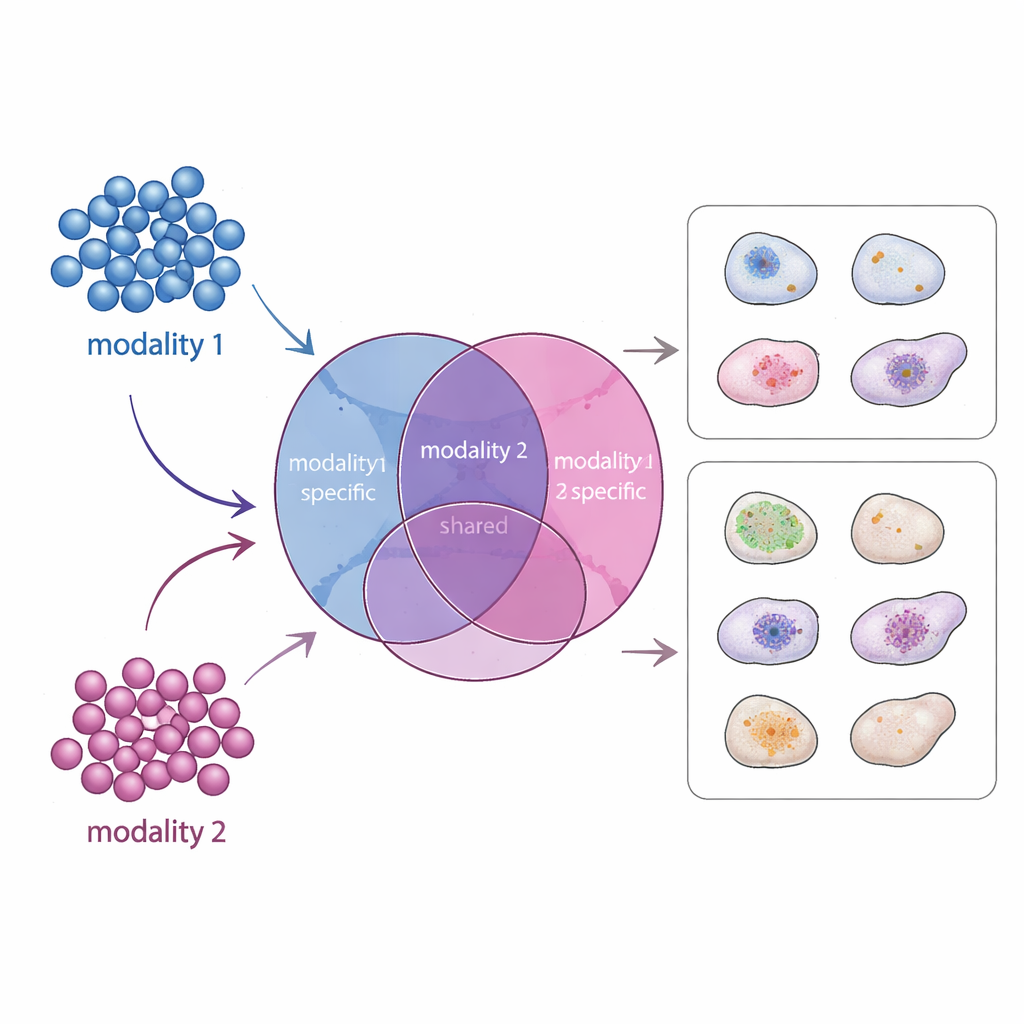
Een nieuwe kaart van gedeelde en unieke signalen
APOLLO pakt dit probleem aan door een gestructureerde interne kaart van elke cel te leren. In plaats van één ongenuanceerde samenvatting deelt het informatie op in drie onderdelen: een gedeeld component dat weerspiegelt wat verschillende metingen gemeen hebben, en twee modaliteit-specifieke componenten die vastleggen wat uniek is voor elk datatypes. Onder de motorkap gebruikt APOLLO een familie van neurale netwerken die auto-encoders worden genoemd. In een eerste trainingsstap behandelt het de interne representatie van elke cel als een set aanpasbare parameters en stelt deze samen met decoder-netwerken bij zodat elke modaliteit nauwkeurig kan worden gereconstrueerd. In een tweede stap traint het encoder-netwerken die deze interne representaties uit nieuwe data kunnen afleiden, waardoor de methode generaliseert naar ongeziene cellen en cross-modality voorspellingen kan doen.
De methode testen op gesimuleerde en echte data
De auteurs benchmarken APOLLO eerst op zorgvuldig ontworpen gesimuleerde datasets waarvan de onderliggende structuur bekend is. In meerdere scenario’s, waaronder gevallen waarin gedeelde en modaliteit-specifieke factoren statistisch in elkaar verstrengeld zijn, slaagt APOLLO erin ze te scheiden in de bedoelde compartimenten. Vervolgens passen ze de methode toe op gekoppelde genexpressie- en chromatietoegankelijkheidsdata uit muishuid, op data die genexpressie koppelen aan oppervlakteeiwitniveaus in immuuncellen, en op zeer gemultiplexte celbeelden. In deze echte datasets vangt de gedeelde ruimte kernbiologische thema’s, zoals sleutelregulatoren die celtype definiëren, terwijl de modaliteit-specifieke ruimtes extra lagen belichten zoals de celcyclusstatus of batch-effecten die uniek zijn voor één meting.
Ontbrekende beelden voorspellen en celstructuur ontrafelen
Een aansprekende toepassing gebruikt beeldvorming van immuuncellen van kankerpatiënten. Hier heeft elke cel een DNA-kleurstof en één of meerdere eiwitkleuringen, maar niet alle eiwitten zijn in elke cel gemeten. APOLLO leert hoe patronen in chromatineorganisatie samenhangen met proteïnelokalisatie en kan vervolgens voorspellen hoe een niet-gemeten eiwit eruit zou zien in een gegeven cel, uitsluitend op basis van diens chromatinebeeld. Deze voorspelde proteïnebeelden zijn zo realistisch dat een afzonderlijke classifier, getraind om patiëntdiagnose te onderscheiden, bijna even goed presteert op hen als op echte beelden. In een andere grote beeldbron, de Human Protein Atlas, maakt APOLLO onderscheid in hoe de vormen van de kern, het microtubuli-netwerk en het endoplasmatisch reticulum samenhangen met waar eiwitten zich binnen de cel bevinden. Voor sommige eiwitten is variatie in kerntextuur het meest informatief; voor andere domineren kenmerken van het omliggende celraamwerk.
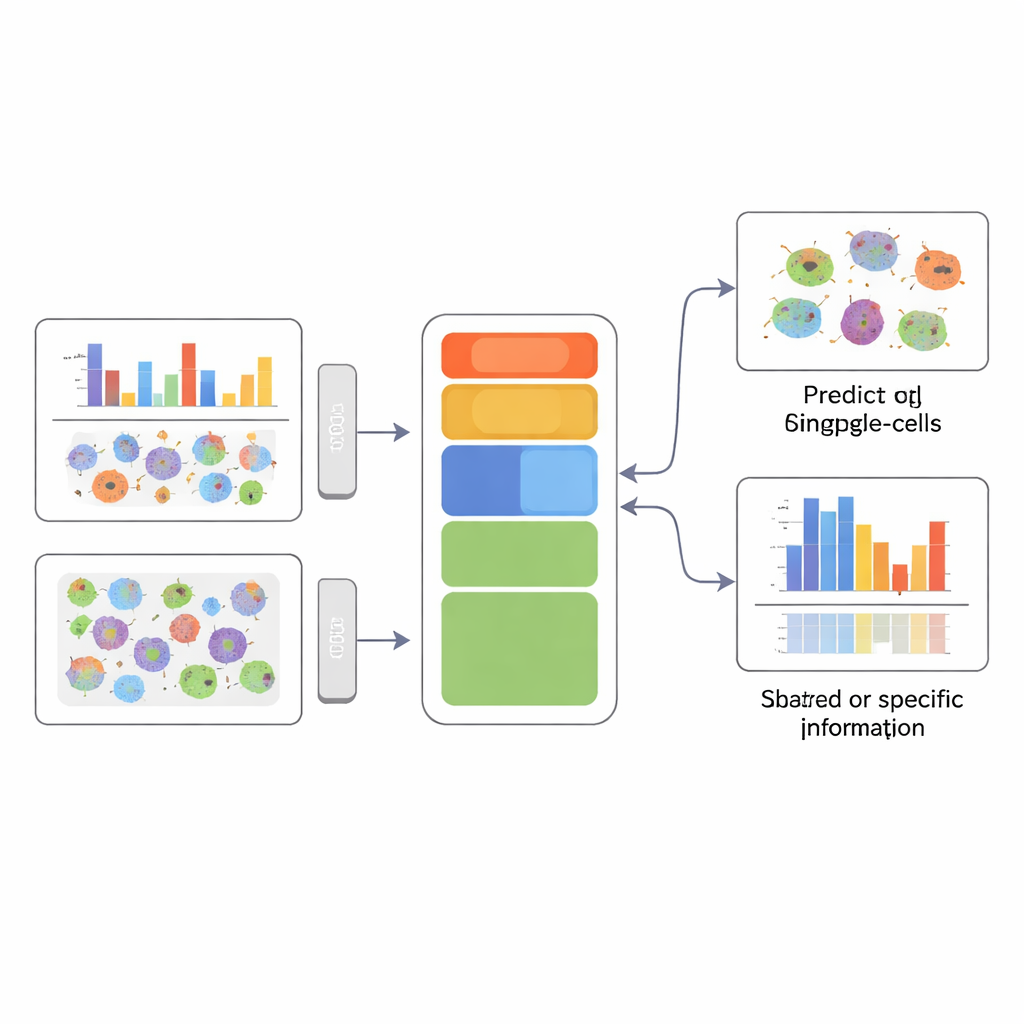
Een duidelijker beeld van celidentiteit
Voor niet-specialisten is de kernboodschap dat APOLLO wetenschappers in staat stelt veel verschillende metingen van dezelfde cellen te combineren zonder het overzicht te verliezen welke meting wat verklaart. Door expliciet gedeelde en modaliteit-specifieke informatie te scheiden, kan de methode zowel ontbrekende gegevens voorspellen — zoals niet-gemeten eiwitbeelden — als benadrukken welke cellulaire compartimenten of datatypes daadwerkelijk gekoppeld zijn aan een bepaald fenotype, zoals ziektestatus of eiwitrelocalisatie. Dit vermogen om een gestructureerde, interpreteerbare samenvatting van elke cel te vormen, legt de basis voor nauwkeurigere diagnostiek en een dieper mechanistisch begrip van hoe verschillende lagen van biologie samenwerken.
Bronvermelding: Zhang, X., Shivashankar, G.V. & Uhler, C. Partially shared multi-modal embedding learns holistic representation of cell state. Nat Comput Sci 6, 285–300 (2026). https://doi.org/10.1038/s43588-025-00948-w
Trefwoorden: single-cell multi-omics, representatie-leren, celtoestand, proteïnelokalisatie, chromatinebeeldvorming