Clear Sky Science · es
Un incrustado multimodal parcialmente compartido aprende una representación holística del estado celular
Por qué importa este estudio
Cada célula de nuestro cuerpo es un pequeño universo, y las herramientas modernas ya pueden observar ese universo desde muchos ángulos a la vez—leyendo genes, mapeando la organización del ADN o capturando imágenes de proteínas. Sin embargo, la mayoría de los métodos computacionales combinan estas perspectivas de un modo que dificulta saber qué medición aporta cada hallazgo. Este artículo presenta APOLLO, una nueva forma de integrar datos celulares diversos que mantiene la pista de lo que se comparte entre mediciones y de lo que es exclusivo de cada una, ofreciendo una visión más clara y holística del comportamiento celular.
Ver las células a través de muchas lentes
La biología actual mide de forma rutinaria varios tipos de información de la misma célula: qué genes están activados, qué tan compactado está el ADN, qué proteínas decoran la superficie o dónde se localizan proteínas específicas dentro de la célula. Cada “modalidad” captura solo una parte del verdadero estado celular. Algunos aspectos, como el tipo celular amplio, pueden aparecer en todas las modalidades, mientras que otros—como el empaquetamiento fino de la cromatina o la localización de una proteína concreta—pueden manifestarse solo en una. Los métodos computacionales existentes o bien analizan cada modalidad por separado o las fusionan en una única representación mezclada. En ambos casos, los científicos tienen dificultades para determinar qué características provienen de qué medición y para predecir qué habría mostrado una medición faltante.
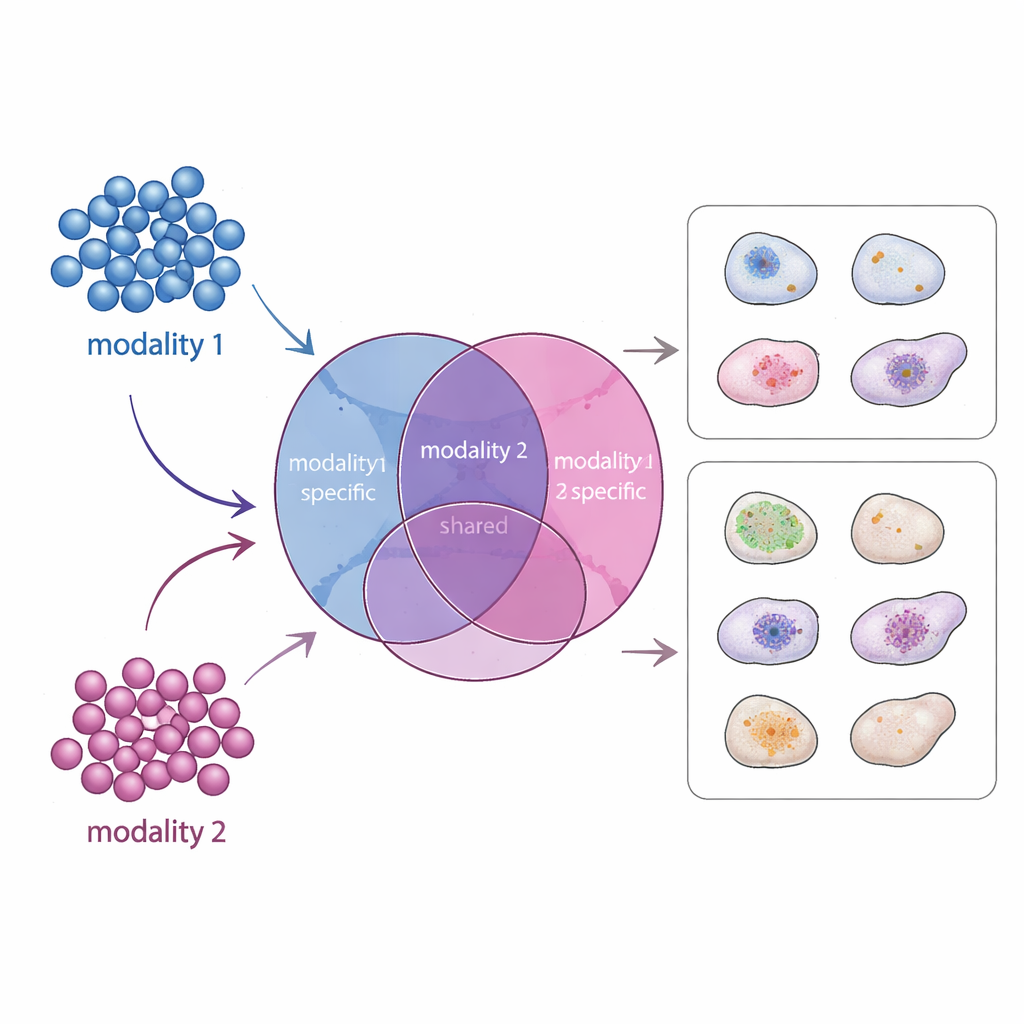
Un nuevo mapa de señales compartidas y únicas
APOLLO aborda este problema aprendiendo un mapa interno estructurado de cada célula. En lugar de un resumen indiferenciado, divide la información en tres partes: un componente compartido que refleja lo que las distintas mediciones tienen en común, y dos componentes específicos de modalidad que capturan lo que es único de cada tipo de datos. En el interior, APOLLO utiliza una familia de redes neuronales llamadas autoencoders. En un primer paso de entrenamiento, trata la representación interna de cada célula como un conjunto de parámetros ajustables y los optimiza conjuntamente con redes decodificadoras para que cada modalidad pueda reconstruirse con precisión. En un segundo paso, entrena redes codificadoras que pueden inferir esas mismas representaciones internas a partir de datos nuevos, lo que permite al método generalizar a células no vistas y realizar predicciones cruzadas entre modalidades.
Probar el método con datos simulados y reales
Los autores primero evalúan APOLLO en conjuntos de datos simulados diseñados con cuidado, donde se conoce la estructura subyacente verdadera. En varios escenarios, incluidos aquellos en los que los factores compartidos y específicos de modalidad están estadísticamente entrelazados, APOLLO los separa con éxito en los compartimentos previstos. Luego aplican el método a datos emparejados de expresión génica y accesibilidad de la cromatina de piel de ratón, a datos que emparejan expresión génica con niveles de proteínas de superficie en células inmunes, y a imágenes celulares altamente multiplexadas. En estos conjuntos de datos reales, el espacio compartido captura temas biológicos centrales, como reguladores clave que definen el tipo celular, mientras que los espacios específicos de cada modalidad resaltan capas adicionales como el estado del ciclo celular o efectos de lote que son exclusivos de una medición.
Predecir imágenes faltantes y desvelar la estructura celular
Una aplicación llamativa utiliza imágenes de células inmunes de pacientes con cáncer. Aquí, cada célula tiene una tinción de ADN y una o varias tinciones de proteínas, pero no todas las proteínas se miden en cada célula. APOLLO aprende cómo los patrones de organización de la cromatina se relacionan con la localización de proteínas y puede entonces predecir cómo aparecería una proteína no medida en una célula dada, basándose solo en su imagen de cromatina. Estas imágenes de proteínas predichas son lo bastante realistas como para que un clasificador independiente, entrenado para distinguir el diagnóstico del paciente, rinda casi igual con ellas que con imágenes reales. En otro gran recurso de imágenes, el Human Protein Atlas, APOLLO separa cómo las formas del núcleo, la red de microtúbulos y el retículo endoplásmico se relacionan con el lugar donde las proteínas residen dentro de la célula. Para algunas proteínas, la variación en la textura nuclear es la más informativa; para otras, predominan rasgos del andamiaje celular circundante.
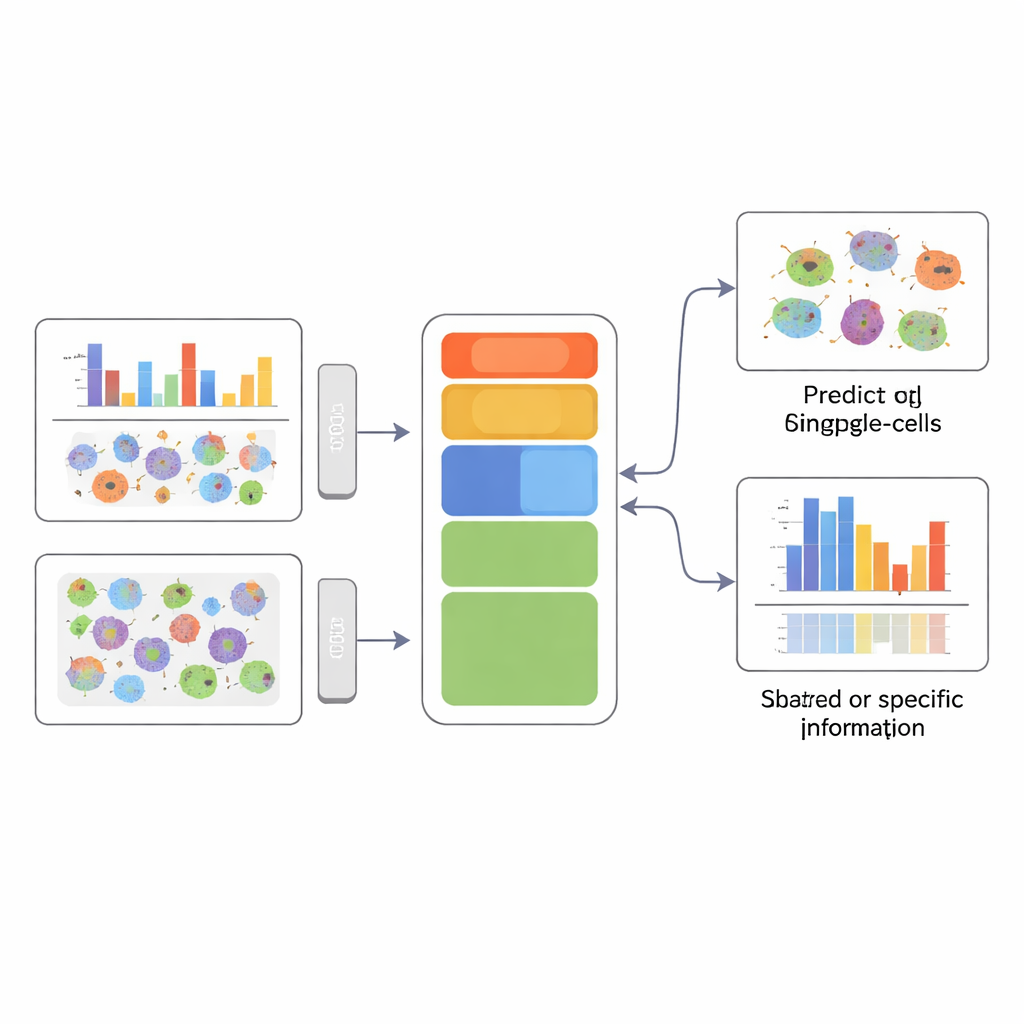
Una imagen más clara de la identidad celular
Para un público no especialista, el mensaje clave es que APOLLO permite a los científicos combinar muchas mediciones distintas de las mismas células sin perder de vista qué medición explica qué. Al separar explícitamente la información compartida de la específica de cada modalidad, el método puede tanto predecir datos faltantes—como imágenes de proteínas no medidas—como resaltar qué compartimento celular o tipo de dato está realmente vinculado a un fenotipo dado, como el estado de la enfermedad o la relocalización de una proteína. Esta capacidad de formar un resumen estructurado e interpretable de cada célula sienta las bases para diagnósticos más precisos y una comprensión mecanicista más profunda de cómo las distintas capas biológicas funcionan en conjunto.
Cita: Zhang, X., Shivashankar, G.V. & Uhler, C. Partially shared multi-modal embedding learns holistic representation of cell state. Nat Comput Sci 6, 285–300 (2026). https://doi.org/10.1038/s43588-025-00948-w
Palabras clave: multi-ómica unicelular, aprendizaje de representaciones, estado celular, localización de proteínas, imagen de la cromatina