Clear Sky Science · it
Un embedding multimodale parzialmente condiviso apprende una rappresentazione olistica dello stato cellulare
Perché questo studio è importante
Ogni cellula del nostro corpo è un piccolo universo, e gli strumenti moderni possono ora osservare quell’universo da molte angolazioni simultaneamente—leggendo i geni, mappando il confezionamento del DNA o visualizzando le proteine. Tuttavia la maggior parte dei metodi informatici fonde queste viste in modo che renda difficile capire quale misura sia responsabile di quale intuizione. Questo articolo presenta APOLLO, un nuovo modo di combinare dati cellulari diversi che tiene traccia di ciò che è condiviso tra le misure e di ciò che è unico per ciascuna, offrendo un quadro più chiaro e olistico del comportamento cellulare.
Vedere le cellule attraverso molte lenti
La biologia odierna misura di routine diversi tipi di informazioni dalla stessa cellula: quali geni sono attivi, quanto è compatto il DNA, quali proteine decorano la superficie o dove si trovano proteine specifiche all’interno della cellula. Ogni “modalità” cattura solo una parte del vero stato cellulare. Alcuni aspetti, come il tipo cellulare generale, possono emergere in tutte le modalità, mentre altri—come il confezionamento del DNA a risoluzione fine o la localizzazione di una proteina particolare—possono apparire in una sola. I metodi computazionali esistenti o analizzano ogni modalità separatamente o le fondono in un’unica rappresentazione mista. In entrambi i casi, gli scienziati faticano a distinguere quali caratteristiche provengano da quale misura e a prevedere cosa avrebbe mostrato una misura mancante.
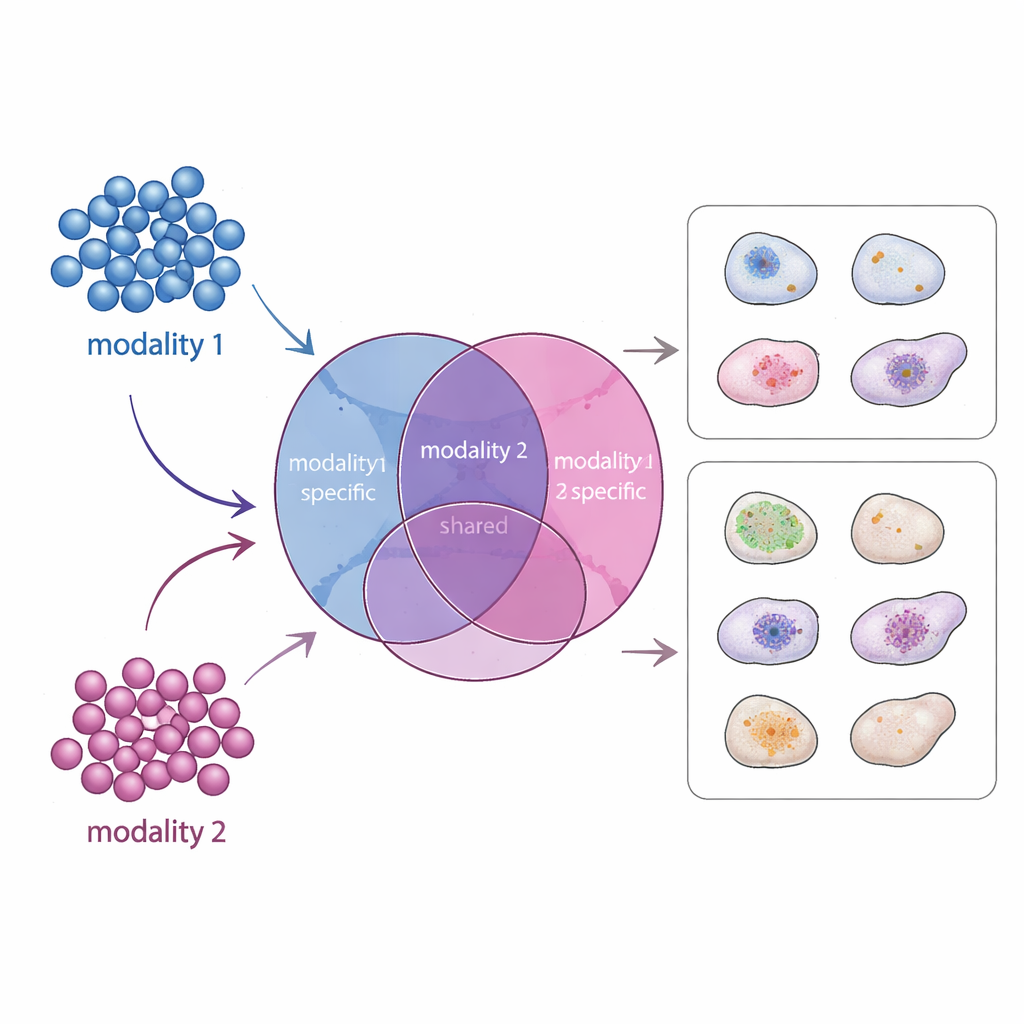
Una nuova mappa di segnali condivisi e specifici
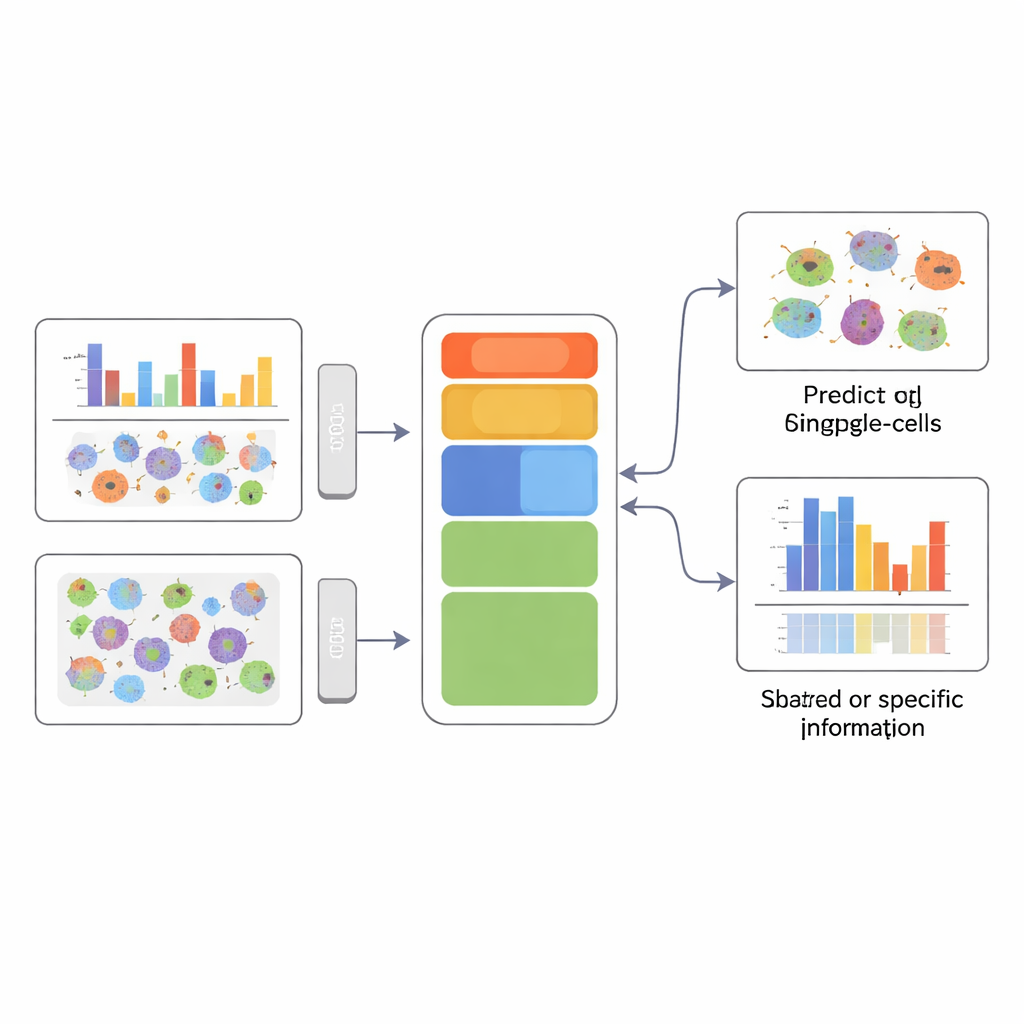
APOLLO affronta questo problema apprendendo una mappa interna strutturata di ogni cellula. Invece di un unico riassunto indistinto, suddivide l’informazione in tre parti: una componente condivisa che riflette ciò che le diverse misure hanno in comune e due componenti specifiche della modalità che catturano ciò che è unico per ciascun tipo di dato. Sotto il cofano, APOLLO utilizza una famiglia di reti neurali chiamate autoencoder. In una prima fase di addestramento tratta la rappresentazione interna di ogni cellula come un insieme di parametri regolabili e li ottimizza congiuntamente con reti decoder in modo che ciascuna modalità possa essere ricostruita accuratamente. In una seconda fase, allena reti encoder che possono inferire quelle stesse rappresentazioni interne a partire da nuovi dati, permettendo al metodo di generalizzare a cellule non viste e di eseguire predizioni cross-modality.
Testare il metodo su dati simulati e reali
Gli autori valutano per primo APOLLO su dataset simulati progettati con cura, dove la struttura sottostante vera è nota. In diversi scenari, inclusi quelli in cui fattori condivisi e specifici di modalità sono statisticamente intrecciati, APOLLO li separa con successo nei compartimenti previsti. Poi applicano il metodo a dati accoppiati di espressione genica e accessibilità della cromatina dalla pelle di topo, a dati che associano espressione genica e livelli di proteine di superficie nelle cellule immunitarie, e ad immagini cellulari altamente multiplexate. In questi dataset reali, lo spazio condiviso cattura temi biologici fondamentali, come i regolatori chiave che definiscono il tipo cellulare, mentre gli spazi specifici per modalità evidenziano livelli aggiuntivi come lo stato del ciclo cellulare o effetti di batch che sono unici per una misura.
Prevedere immagini mancanti e svelare la struttura cellulare
Una applicazione notevole utilizza l’imaging di cellule immunitarie provenienti da pazienti oncologici. Qui, ogni cellula ha una colorazione del DNA e una o più colorazioni proteiche, ma non tutte le proteine sono misurate in ogni cellula. APOLLO apprende come i modelli nell’organizzazione della cromatina si relazionano alla localizzazione delle proteine e può quindi prevedere come apparirebbe una proteina non misurata in una data cellula basandosi solo sulla sua immagine della cromatina. Queste immagini proteiche previste sono abbastanza realistiche che un classificatore separato, addestrato a distinguere la diagnosi del paziente, ottiene prestazioni quasi pari su di esse rispetto alle immagini reali. In un’altra grande risorsa di imaging, l’Human Protein Atlas, APOLLO discrimina come le forme del nucleo, la rete di microtubuli e il reticolo endoplasmatico siano legate al luogo in cui le proteine risiedono all’interno della cellula. Per alcune proteine, la variazione nella texture nucleare è la più informativa; per altre, predominano caratteristiche dell’impalcatura cellulare circostante.
Un quadro più nitido dell’identità cellulare
Per un non specialista, il messaggio chiave è che APOLLO permette agli scienziati di combinare molte misure diverse delle stesse cellule senza perdere traccia di quale misura spieghi cosa. Separando esplicitamente l’informazione condivisa da quella specifica di modalità, il metodo può sia prevedere dati mancanti—come immagini proteiche non misurate—sia evidenziare quale compartimento cellulare o tipo di dato sia realmente legato a un dato fenotipo, come lo stato di malattia o la relocalizzazione di una proteina. Questa capacità di formare un riassunto strutturato e interpretabile di ogni cellula pone le basi per diagnosi più precise e una comprensione meccanicistica più profonda di come diversi strati biologici lavorino insieme.
Citazione: Zhang, X., Shivashankar, G.V. & Uhler, C. Partially shared multi-modal embedding learns holistic representation of cell state. Nat Comput Sci 6, 285–300 (2026). https://doi.org/10.1038/s43588-025-00948-w
Parole chiave: multi-omica a singola cellula, apprendimento delle rappresentazioni, stato cellulare, localizzazione delle proteine, imaging della cromatina