Clear Sky Science · fr
Un embedding multimodal partiellement partagé apprend une représentation holistique de l’état cellulaire
Pourquoi cette étude est importante
Chaque cellule de notre corps est un petit univers, et les outils modernes peuvent désormais observer cet univers sous de multiples angles simultanément — en lisant les gènes, en cartographiant l’organisation de l’ADN ou en imaginant les protéines. Pourtant, la plupart des méthodes informatiques mélangent ces vues d’une manière qui rend difficile l’identification de la mesure responsable d’un certain insight. Cet article présente APOLLO, une nouvelle façon de combiner des données cellulaires diverses qui conserve la trace de ce qui est partagé entre les mesures et de ce qui est propre à chacune, offrant une image plus claire et plus holistique du comportement cellulaire.
Voir les cellules à travers plusieurs lentilles
La biologie moderne mesure couramment plusieurs types d’informations à partir d’une même cellule : quels gènes sont activés, à quel point l’ADN est condensé, quelles protéines ornent la surface, ou où se trouvent des protéines spécifiques à l’intérieur de la cellule. Chaque « modalité » capture une partie seulement du véritable état cellulaire. Certains aspects, comme le type cellulaire général, peuvent apparaître dans toutes les modalités, tandis que d’autres — comme l’organisation fine de la chromatine ou la localisation d’une protéine particulière — peuvent n’apparaître que dans une seule. Les méthodes computationnelles existantes analysent soit chaque modalité séparément, soit les fusionnent en une seule représentation mixte. Dans les deux cas, les scientifiques peinent à savoir quelles caractéristiques proviennent de quelle mesure et à prédire ce qu’aurait montré une mesure manquante.
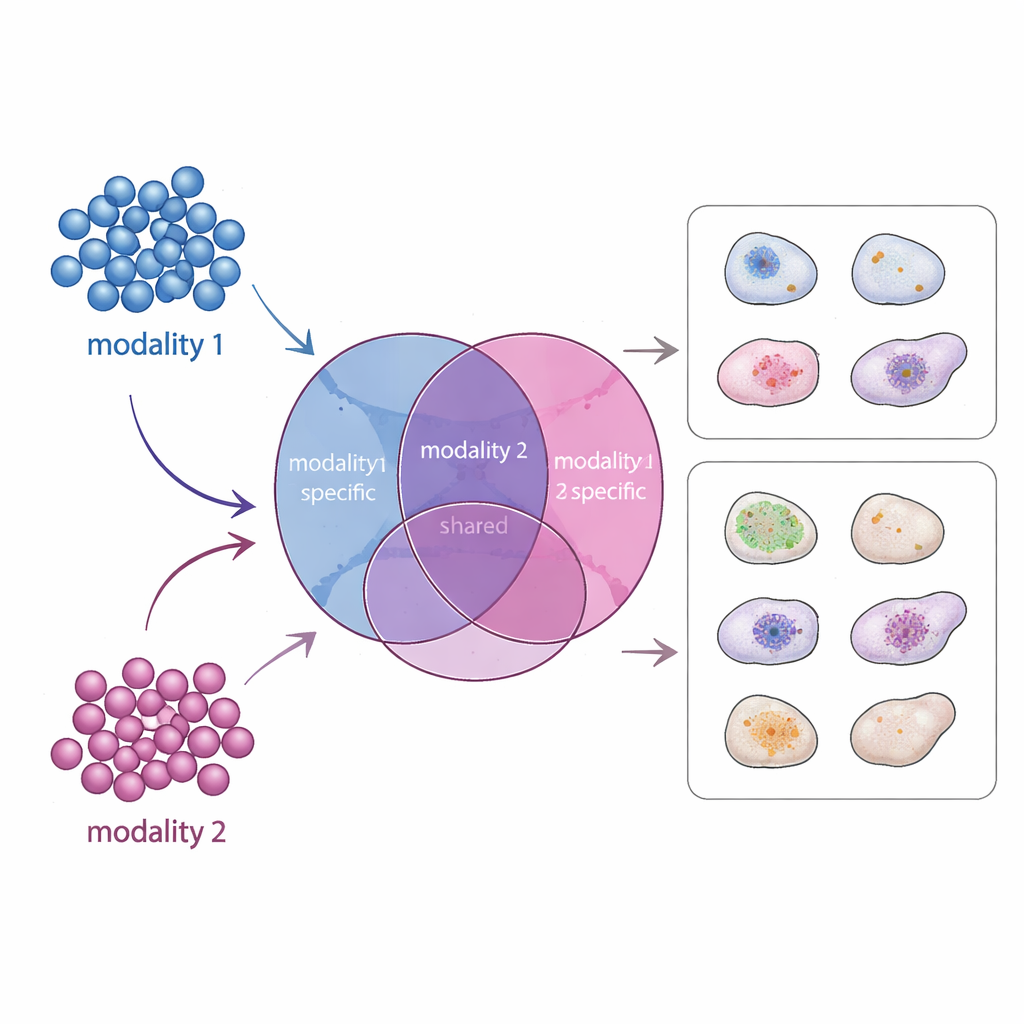
Une nouvelle carte des signaux partagés et spécifiques
APOLLO aborde ce problème en apprenant une carte interne structurée de chaque cellule. Plutôt que d’avoir un résumé indifférencié, il divise l’information en trois parties : une composante partagée qui reflète ce que les différentes mesures ont en commun, et deux composantes propres à chaque modalité qui capturent ce qui est unique à chaque type de données. Sous le capot, APOLLO utilise une famille de réseaux neuronaux appelés autoencodeurs. Lors d’une première étape d’entraînement, il considère la représentation interne de chaque cellule comme un ensemble de paramètres ajustables et les optimise conjointement avec des réseaux décodeurs afin que chaque modalité puisse être reconstituée avec précision. Dans une seconde étape, il entraîne des réseaux encodeurs capables d’inférer ces mêmes représentations internes à partir de nouvelles données, permettant à la méthode de généraliser à des cellules non vues et d’effectuer des prédictions inter-modales.
Test de la méthode sur des données simulées et réelles
Les auteurs commencent par évaluer APOLLO sur des jeux de données simulés soigneusement conçus où la structure sous-jacente vraie est connue. Dans plusieurs scénarios, y compris des cas où les facteurs partagés et spécifiques aux modalités sont statistiquement intriqués, APOLLO parvient à les séparer dans les compartiments prévus. Ils appliquent ensuite la méthode à des données appariées d’expression génique et d’accessibilité de la chromatine provenant de peau de souris, à des données appariant expression génique et niveaux de protéines de surface dans des cellules immunitaires, et à des images cellulaires hautement multiplexées. Dans ces jeux de données réels, l’espace partagé capture les thèmes biologiques centraux, comme les régulateurs clés définissant le type cellulaire, tandis que les espaces spécifiques aux modalités mettent en évidence des couches additionnelles comme le statut du cycle cellulaire ou des effets de lot propres à une mesure.
Prédire des images manquantes et dévoiler la structure cellulaire
Une application frappante utilise l’imagerie de cellules immunitaires de patients atteints de cancer. Ici, chaque cellule a une coloration de l’ADN et une ou plusieurs colorations protéiques, mais toutes les protéines ne sont pas mesurées dans chaque cellule. APOLLO apprend comment les motifs d’organisation de la chromatine se rapportent à la localisation des protéines et peut ensuite prédire à quoi ressemblerait une protéine non mesurée dans une cellule donnée, à partir de son image de chromatine uniquement. Ces images protéiques prédites sont suffisamment réalistes pour qu’un classifieur distinct, entraîné pour distinguer le diagnostic des patients, obtienne presque les mêmes performances sur ces images que sur des images réelles. Dans une autre grande ressource d’imagerie, l’Atlas de protéines humaines, APOLLO dissocie comment les formes du noyau, du réseau de microtubules et du réticulum endoplasmique sont liées à l’emplacement des protéines à l’intérieur de la cellule. Pour certaines protéines, la variation de la texture nucléaire est la plus informative ; pour d’autres, ce sont des caractéristiques de l’échafaudage cellulaire environnant qui dominent.
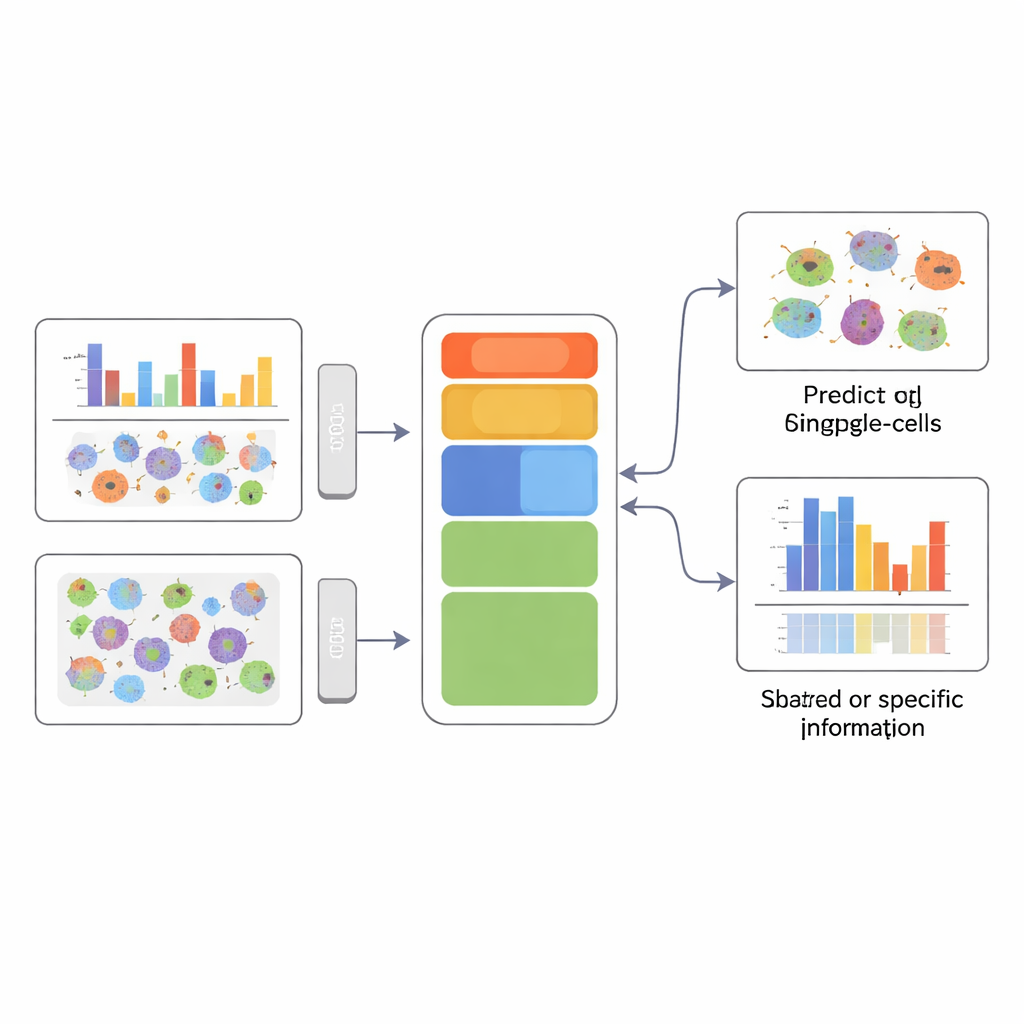
Une image plus claire de l’identité cellulaire
Pour un non-spécialiste, le message clé est qu’APOLLO permet aux scientifiques de combiner de nombreuses mesures différentes des mêmes cellules sans perdre de vue quelle mesure explique quoi. En séparant explicitement l’information partagée de l’information spécifique à une modalité, la méthode peut à la fois prédire des données manquantes — comme des images protéiques non mesurées — et mettre en évidence quel compartiment cellulaire ou quel type de données est véritablement lié à un phénotype donné, comme l’état de la maladie ou la relocalisation d’une protéine. Cette capacité à former un résumé structuré et interprétable de chaque cellule jette les bases de diagnostics plus précis et d’une compréhension mécanistique approfondie de la façon dont différentes couches de la biologie interagissent.
Citation: Zhang, X., Shivashankar, G.V. & Uhler, C. Partially shared multi-modal embedding learns holistic representation of cell state. Nat Comput Sci 6, 285–300 (2026). https://doi.org/10.1038/s43588-025-00948-w
Mots-clés: multi-omique unicellulaire, apprentissage de représentation, état cellulaire, localisation des protéines, imagerie de la chromatine