Clear Sky Science · en
Partially shared multi-modal embedding learns holistic representation of cell state
Why this study matters
Every cell in our body is a tiny universe, and modern tools can now watch that universe from many angles at once—by reading genes, mapping DNA packaging, or imaging proteins. Yet most computer methods blend these views together in a way that makes it hard to tell which measurement is responsible for which insight. This paper introduces APOLLO, a new way of combining diverse cell data that keeps track of what is shared across measurements and what is unique to each, offering a clearer, more holistic picture of cell behavior.
Seeing cells through many lenses
Today’s biology routinely measures several kinds of information from the same cell: which genes are switched on, how tightly DNA is packed, which proteins decorate the surface, or where specific proteins sit inside the cell. Each “modality” captures only part of the true cell state. Some aspects, like broad cell type, may show up in all modalities, while others—such as fine-grained DNA packaging or a particular protein’s location—may appear in only one. Existing computational methods either analyze each modality separately or fuse them into a single mixed representation. In both cases, scientists struggle to tell which features come from which measurement and to predict what a missing measurement would have shown.
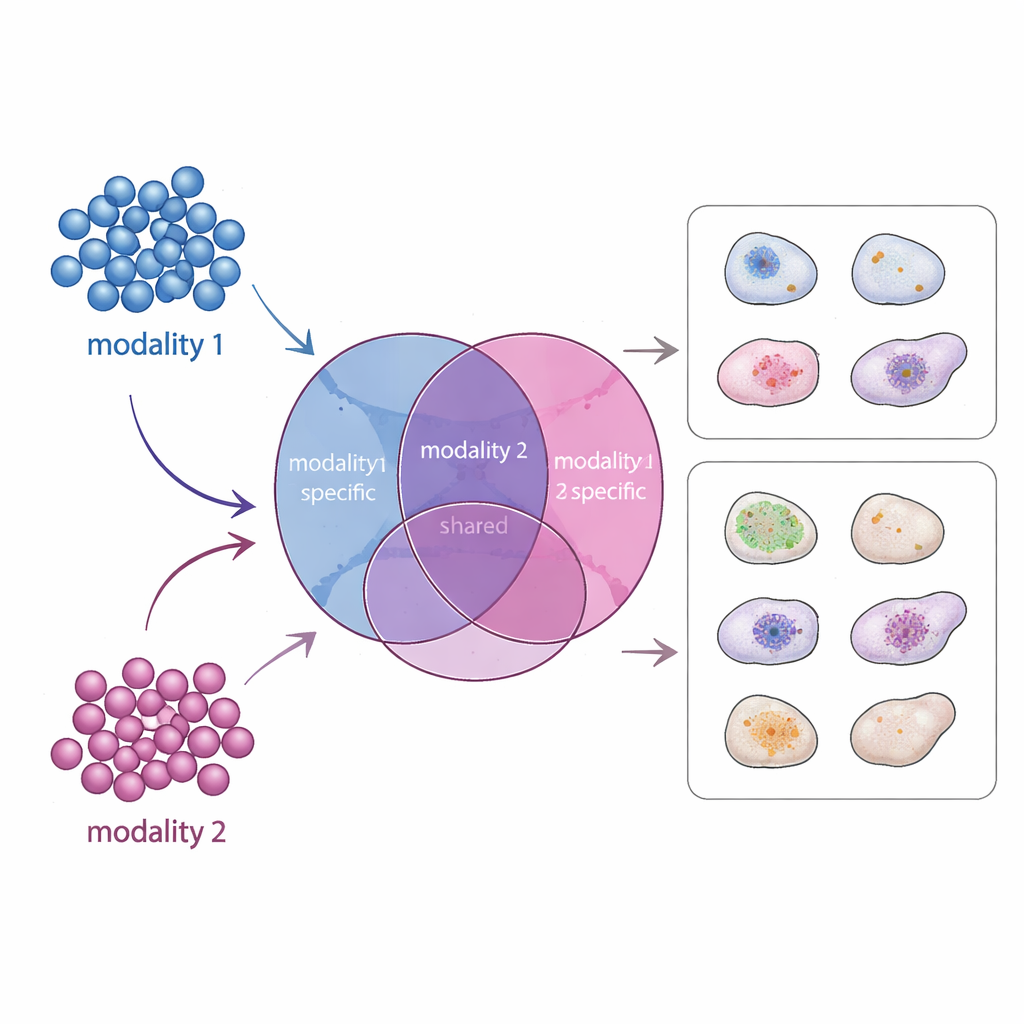
A new map of shared and unique signals
APOLLO tackles this problem by learning a structured internal map of each cell. Instead of one undifferentiated summary, it divides information into three parts: a shared component that reflects what different measurements have in common, and two modality-specific components that capture what is unique to each data type. Under the hood, APOLLO uses a family of neural networks called autoencoders. In a first training step, it treats the internal representation of every cell as a set of adjustable parameters and tunes them jointly with decoder networks so that each modality can be reconstructed accurately. In a second step, it trains encoder networks that can infer these same internal representations from new data, allowing the method to generalize to unseen cells and to perform cross-modality prediction.
Testing the method on simulated and real data
The authors first benchmark APOLLO on carefully designed simulated datasets where the true underlying structure is known. Across several scenarios, including ones where shared and modality-specific factors are statistically entangled, APOLLO successfully separates them into the intended compartments. They then apply the method to paired gene-expression and chromatin-accessibility data from mouse skin, to data that pair gene expression with surface protein levels in immune cells, and to highly multiplexed cell images. In these real datasets, the shared space captures core biological themes, such as key regulators that define cell type, while modality-specific spaces highlight additional layers like cell-cycle status or batch effects that are unique to one measurement.
Predicting missing images and uncovering cell structure
One striking application uses imaging of immune cells from cancer patients. Here, every cell has a DNA stain and one or several protein stains, but not all proteins are measured in each cell. APOLLO learns how patterns in chromatin organization relate to protein localization and can then predict how an unmeasured protein would appear in a given cell, based only on its chromatin image. These predicted protein images are realistic enough that a separate classifier, trained to distinguish patient diagnosis, performs almost as well on them as on real images. In another large imaging resource, the Human Protein Atlas, APOLLO disentangles how the shapes of the nucleus, the microtubule network, and the endoplasmic reticulum are tied to where proteins reside inside the cell. For some proteins, variation in nuclear texture is most informative; for others, features of the surrounding cell scaffolding dominate.
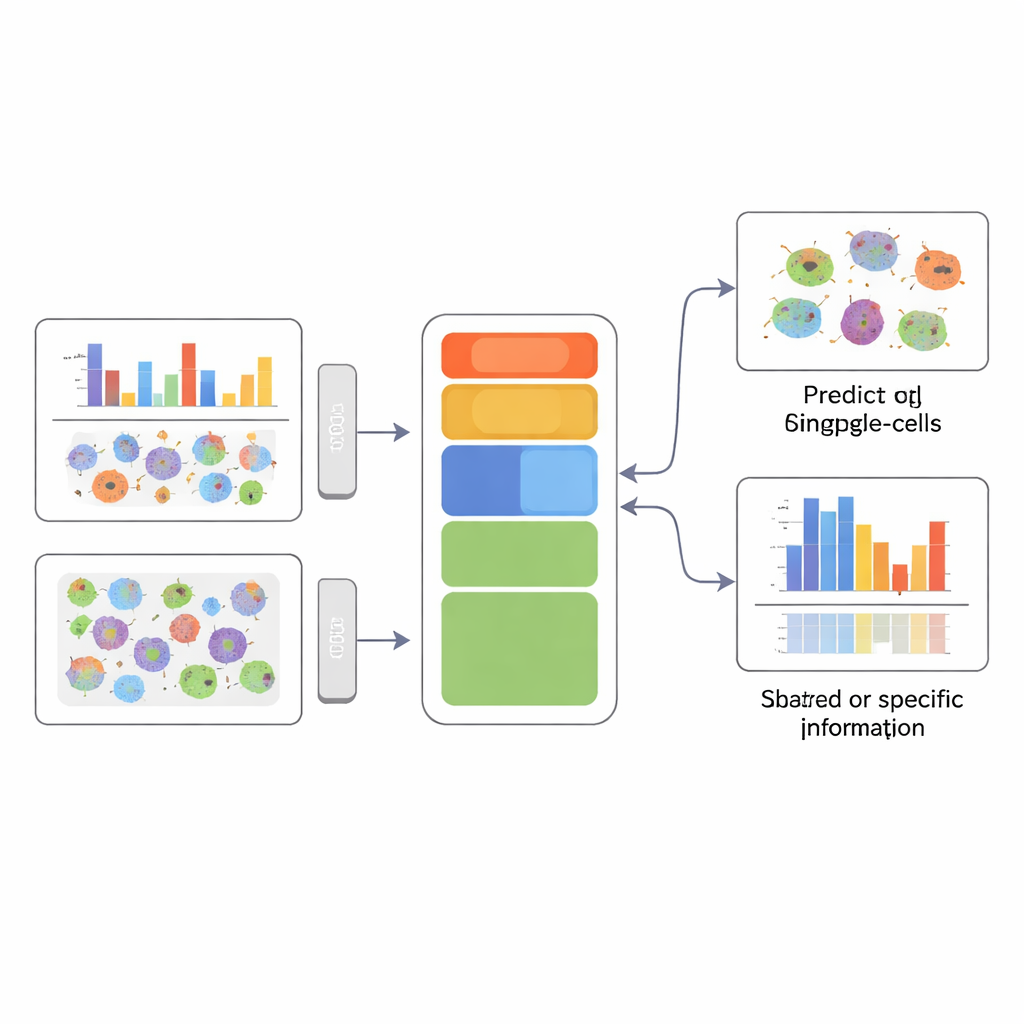
A clearer picture of cell identity
To a non-specialist, the key message is that APOLLO lets scientists combine many different measurements of the same cells without losing track of which measurement explains what. By explicitly separating shared from modality-specific information, the method can both predict missing data—such as unmeasured protein images—and highlight which cellular compartment or data type is truly linked to a given phenotype, like disease status or protein relocalization. This ability to form a structured, interpretable summary of each cell lays groundwork for more precise diagnostics and a deeper mechanistic understanding of how different layers of biology work together.
Citation: Zhang, X., Shivashankar, G.V. & Uhler, C. Partially shared multi-modal embedding learns holistic representation of cell state. Nat Comput Sci 6, 285–300 (2026). https://doi.org/10.1038/s43588-025-00948-w
Keywords: single-cell multi-omics, representation learning, cell state, protein localization, chromatin imaging