Clear Sky Science · pt
TransSiamUNet: Transformer-augmentado Siamese-U-Net para detecção precisa de mudanças em imagens de satélite
Observando a Terra Evoluir Desde o Alto
Todos os dias, frotas de satélites fotografam silenciosamente nosso planeta, registrando novas estradas, edifícios, inundações, incêndios e florestas encolhendo. Transformar esse fluxo de pixels em mapas claros e confiáveis do que mudou no terreno é crucial para planejadores urbanos, equipes de resposta a desastres e cientistas ambientais — mas também é surpreendentemente difícil. Este artigo apresenta o TransSiamUNet, um sistema de inteligência artificial projetado para filtrar pares de imagens de satélite e destacar com precisão o que realmente mudou, enquanto ignora distrações como nuvens, sombras e variações de iluminação.
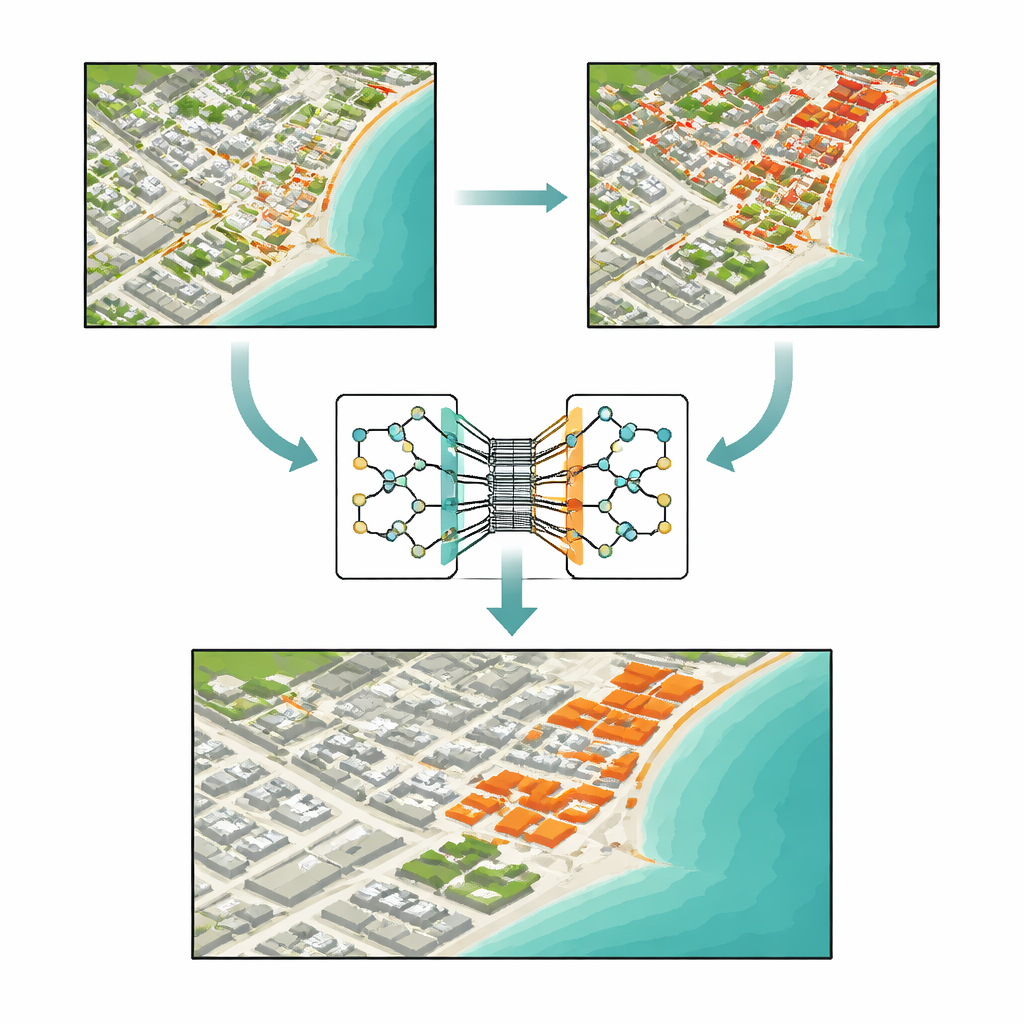
Por que Encontrar Mudanças Reais É Tão Difícil
À primeira vista, detectar mudanças entre duas imagens parece tão simples quanto subtrair uma imagem da outra. Métodos tradicionais fazem exatamente isso: comparam brilho, calculam razões de cor ou medem distâncias entre valores de pixel. Essas abordagens são rápidas e fáceis de implementar, mas são facilmente enganadas. Diferenças na iluminação, neblina, ruído do sensor ou pequeno desalinhamento podem parecer mudanças genuínas, enquanto alterações pequenas mas importantes — como uma casa nova ou uma estrada estreita — podem ocupar apenas alguns pixels e ser totalmente perdidas. À medida que as imagens de satélite ficam mais ricas, com muitas bandas espectrais e grandes áreas, essas ferramentas antigas têm dificuldade em separar transformações significativas do ruído de fundo.
O Papel do Deep Learning
Nos últimos anos, o deep learning transformou o sensoriamento remoto ao permitir que os computadores aprendam padrões diretamente dos dados em vez de depender de fórmulas manuais. Redes neurais convolucionais e pares "Siamese" de redes têm sido treinados para comparar duas imagens do mesmo local em tempos diferentes. Arquiteturas como U-Net podem converter essas características aprendidas em mapas detalhados que marcam cada pixel como "alterado" ou "inalterado". Mais recentemente, modelos transformer — originalmente desenvolvidos para linguagem — foram adaptados para imagens, onde se destacam em capturar relações de longo alcance através de uma cena, como a forma como edifícios distantes ou campos se relacionam entre si. No entanto, cada família de modelos tem fraquezas: redes Siamese podem perder a visão global, transformers puros podem suavizar detalhes finos, e muitos híbridos combinam partes sem explorar plenamente suas forças em conjunto.
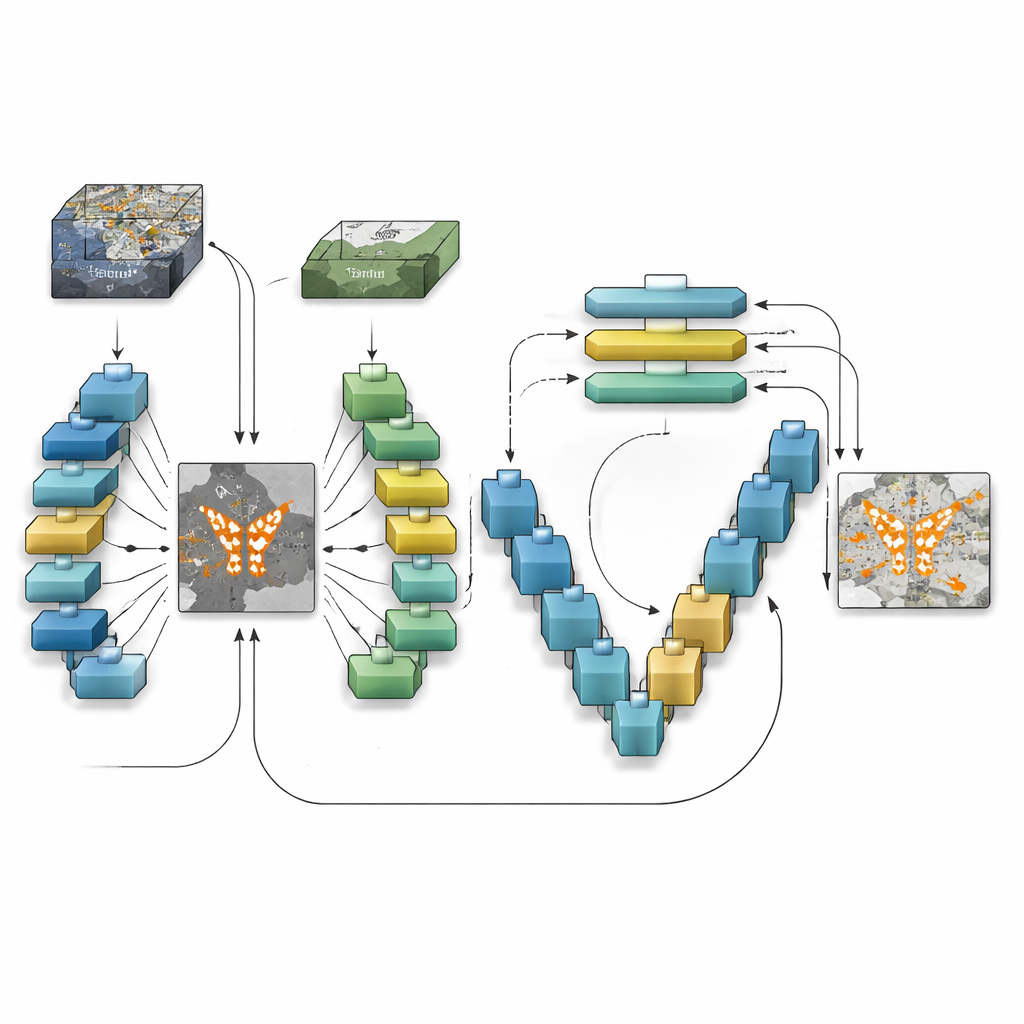
Como o Novo Modelo Enxerga Mudanças
O TransSiamUNet foi projetado para combinar as melhores qualidades dessas ideias em um único sistema coordenado. Ele começa com um encoder Siamese: dois ramos neurais idênticos que processam as imagens de "antes" e "depois" da mesma forma, garantindo que as diferenças não sejam causadas pelo próprio modelo. Suas saídas são então subtraídas para produzir um "mapa de diferenças" focado que enfatiza onde a cena pode ter mudado. Em vez de alimentar as imagens brutas em um transformer, os autores enviam apenas esse mapa de diferenças para um bloco Vision Transformer. Isso incentiva o transformer a concentrar seu orçamento de atenção nas estruturas que realmente estão mudando, em vez do fundo estático, ajudando-o a entender como regiões mudadas distantes se relacionam por toda a imagem.
Aproximando de Volta ao Nível do Pixel
Uma vez que o transformer constrói uma compreensão global das mudanças candidatas, o TransSiamUNet passa essa informação para um decodificador em forma de U. Esse decodificador aumenta gradualmente as características comprimidas de volta à resolução total, ao mesmo tempo que incorpora detalhes de alta frequência de camadas anteriores por meio de conexões skip. Na prática, o modelo combina uma visão grande-angular de toda a cena com contornos locais e nítidos de estradas, edifícios e campos. Os autores também experimentam etapas simples de limpeza, como filtros morfológicos e suavização probabilística, para aparar os limites das áreas detectadas. Testes cuidadosos em três conjuntos de referência que abrangem diferentes cidades, resoluções e tipos de uso do solo mostram que a combinação completa — encoder Siamese, gargalo transformer e decodificador U-Net — supera versões que faltam qualquer uma dessas partes.
Comprovando em Cidades Reais
Usando um conjunto de dados padrão chamado OSCD, junto com duas grandes coleções focadas em mudanças de edifícios no Texas e na Nova Zelândia, os autores comparam o TransSiamUNet com métodos tradicionais e com técnicas avançadas de deep learning. Sob condições idênticas de treinamento e avaliação, o novo modelo alcança uma acurácia de cerca de 94% no OSCD, superando concorrentes fortes que incluem redes puramente convolucionais, sistemas baseados em transformer e modelos de sequência mais recentes. Estudos de caso detalhados de Beirute — uma cidade em rápido crescimento — e Valência — uma cidade relativamente estável — ilustram que o modelo pode tanto destacar construções intensas quanto relatar com confiança "sem mudança" quando a paisagem está estável. Experimentos de ablação, nos quais componentes são removidos ou alterados, mostram que o desempenho cai acentuadamente sem o desenho Siamese, o transformer ou o decodificador multiescala, confirmando que sua interação — não apenas o tamanho do modelo — impulsiona os ganhos.
O Que Isso Significa para Quem Está no Chão
Para não especialistas, o resultado principal é que agora dispomos de uma maneira mais confiável de transformar imagens brutas de satélite em mapas de mudança precisos no nível de pixel. O TransSiamUNet pode detectar novos edifícios, espaços verdes desaparecendo e a extensão de inundações ou outros desastres com maior confiança e menos alarmes falsos do que muitos sistemas anteriores. Isso o torna uma ferramenta promissora para agências e organizações que precisam de informações oportunas e confiáveis sobre como as cidades crescem, como a infraestrutura evolui e como o ambiente responde ao estresse climático. À medida que constelações de satélites se expandem e arquivos de imagens se aprofundam, abordagens como esta — que combinam detalhe local com contexto global — serão centrais para manter uma imagem clara e atualizada do nosso planeta em mudança.
Citação: Ali, F., Labib, S.S., Mahmoud, A. et al. TransSiamUNet based transformer-augmented Siamese-U-Net for precise change detection in satellite imagery. Sci Rep 16, 11689 (2026). https://doi.org/10.1038/s41598-026-43164-w
Palavras-chave: detecção de mudanças por satélite, sensoriamento remoto IA, monitoramento de crescimento urbano, modelos de deep learning, vision transformers