Clear Sky Science · pl
TransSiamUNet — oparty na transformatorze, wzbogacony Siamese-U-Net do precyzyjnego wykrywania zmian na zdjęciach satelitarnych
Obserwowanie Ziemi z Lotu Ptaka
Codziennie floty satelitów w ciszy fotografują naszą planetę, rejestrując nowe drogi, budynki, powodzie, pożary i kurczące się lasy. Przekształcenie tych potoków pikseli w czytelne, wiarygodne mapy tego, co zmieniło się na ziemi, jest kluczowe dla planistów miejskich, służb ratowniczych i naukowców środowiskowych — ale jest też zaskakująco trudne. W artykule przedstawiono TransSiamUNet, system sztucznej inteligencji zaprojektowany do analizowania par zdjęć satelitarnych i precyzyjnego wskazywania rzeczywistych zmian, ignorując rozproszenia takie jak chmury, cienie czy zmienne oświetlenie.
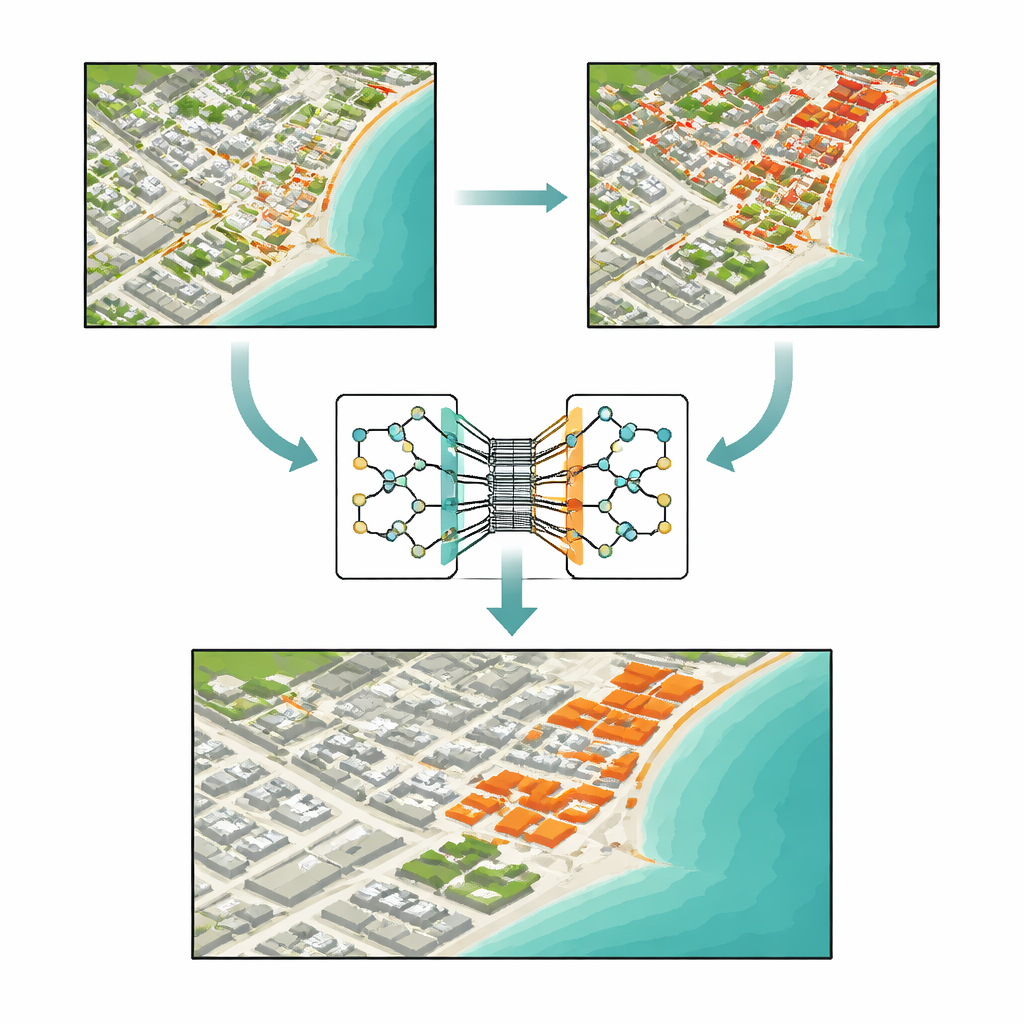
Dlaczego znalezienie prawdziwej zmiany jest tak trudne
Na pierwszy rzut oka wykrywanie zmiany między dwoma zdjęciami wydaje się tak proste jak odjęcie jednego obrazu od drugiego. Tradycyjne metody robią dokładnie to: porównują jasność, biorą stosunki kolorów lub mierzą odległość między wartościami pikseli. Podejścia te są szybkie i łatwe do wdrożenia, lecz łatwo je zmylić. Różnice w oświetleniu, mgła, szum sensora czy lekkie niedopasowanie mogą wyglądać jak rzeczywista zmiana, podczas gdy niewielkie, lecz istotne przesunięcia — na przykład nowy dom czy wąska droga — mogą obejmować tylko kilka pikseli i zostać całkowicie pominięte. Wraz z rosnącą złożonością obrazów satelitarnych, z wieloma pasmami spektralnymi i dużymi obszarami, starsze narzędzia mają trudności z oddzieleniem znaczących przekształceń od tła.
Wejście głębokiego uczenia
W ostatnich latach głębokie uczenie zmieniło zdalne wykrywanie, pozwalając komputerom uczyć się wzorców bezpośrednio z danych zamiast polegać na ręcznie zaprojektowanych formułach. Sieci konwolucyjne i pary sieci „siamskich” były trenowane do porównywania dwóch zdjęć tego samego miejsca wykonanych w różnych momentach. Architektury takie jak U-Net potrafią przekształcić wyuczone cechy w szczegółowe mapy, oznaczające każdy piksel jako „zmieniony” lub „niezmieniony”. Ostatnio modele transformatorowe — początkowo rozwinięte dla języka — zostały zaadaptowane do obrazów, gdzie doskonale wychwytują zależności na dużych odległościach w scenie, na przykład relacje między odległymi budynkami czy polami. Każda z tych rodzin modeli ma jednak słabości: sieci siamskie mogą nie uchwycić szerszego kontekstu, czyste transformatory mogą rozmywać drobne detale, a wiele hybryd łączy komponenty bez pełnego wykorzystania ich zalet.
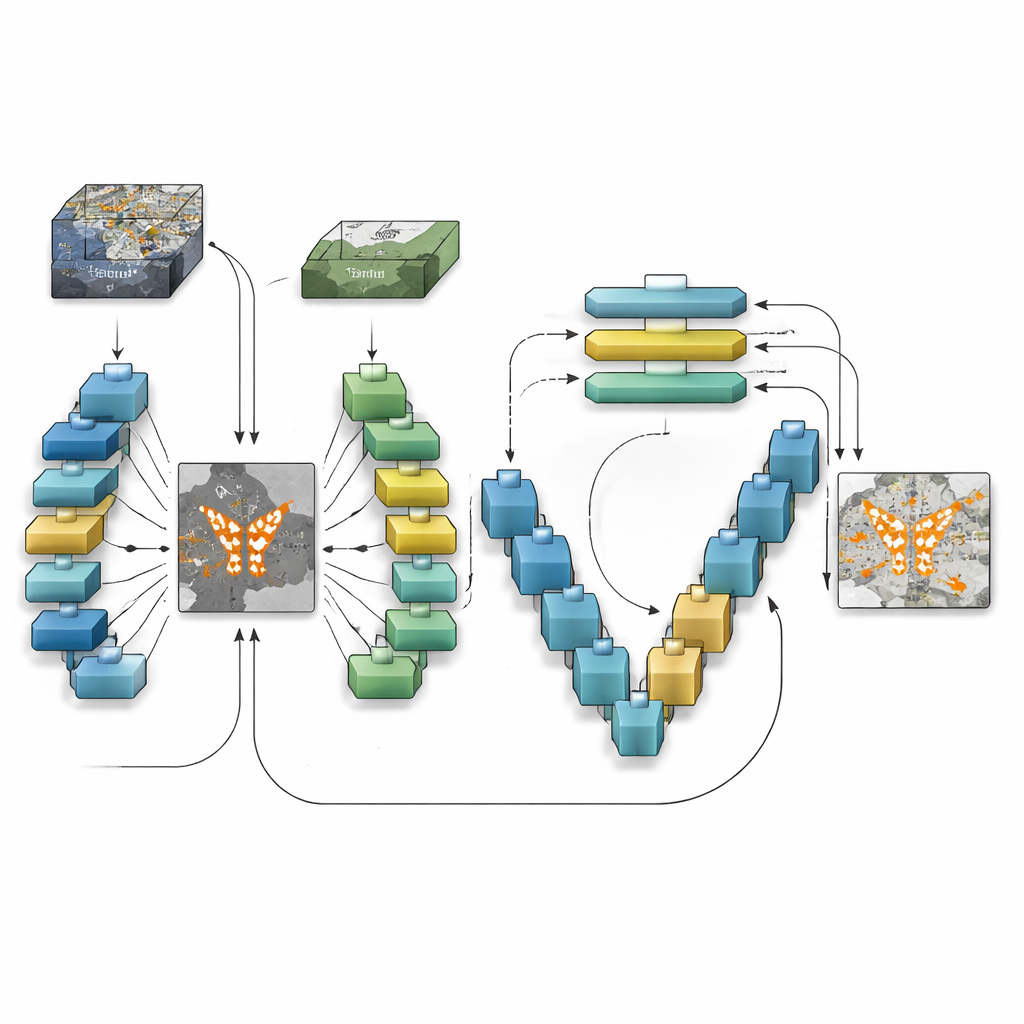
Jak nowy model widzi zmianę
TransSiamUNet został zaprojektowany tak, by połączyć najlepsze cechy tych podejść w jednym, skoordynowanym systemie. Zaczyna się od siamskiego enkodera: dwóch identycznych gałęzi sieciowych, które przetwarzają obrazy „przed” i „po” w ten sam sposób, zapewniając, że różnice nie wynikają z samego modelu. Ich wyjścia są następnie odejmowane, tworząc skoncentrowaną „mapę różnic”, która uwydatnia miejsca, gdzie scena mogła się zmienić. Zamiast podawać surowe obrazy do transformatora, autorzy przesyłają tylko tę mapę różnic do bloku Vision Transformer. Zachęca to transformator, by skierował swój budżet uwagi na struktury, które rzeczywiście się zmieniają, zamiast na statyczne tło, pomagając mu zrozumieć, jak odległe zmienione regiony odnoszą się do siebie w całym obrazie.
Powrót do poziomu piksela
Gdy transformer zbuduje globalne rozumienie kandydatów na zmiany, TransSiamUNet przekazuje te informacje do U-kształtnego dekodera. Dekoder stopniowo zwiększa rozdzielczość skompresowanych cech z powrotem do pełnej rozdzielczości, jednocześnie pobierając drobne szczegóły z wcześniejszych warstw poprzez połączenia skip. W praktyce model łączy szerokokątny obraz całej sceny z lokalnymi, ostrymi krawędziami dróg, budynków i pól. Autorzy eksperymentują też z prostymi krokami porządkującymi, takimi jak filtry morfologiczne i wygładzanie probabilistyczne, aby uporządkować granice wykrytych obszarów. Starannie przeprowadzone testy na trzech zestawach referencyjnych obejmujących różne miasta, rozdzielczości i typy użytkowania gruntów pokazują, że pełne połączenie — siamski enkoder, transformatorowy „wąskie gardło” i dekoder U-Net — przewyższa wersje pozbawione któregokolwiek z tych elementów.
Dowód działania w rzeczywistych miastach
Korzystając ze standardowego zbioru danych OSCD oraz dwóch dużych kolekcji skupionych na zmianach budynków w Teksasie i Nowej Zelandii, autorzy porównują TransSiamUNet z tradycyjnymi i najnowocześniejszymi metodami głębokiego uczenia. W identycznych warunkach treningowych i ewaluacyjnych nowy model osiąga około 94% dokładności na OSCD, pokonując silnych konkurentów, w tym czyste sieci konwolucyjne, systemy oparte na transformatorach i nowsze modele sekwencyjne. Szczegółowe studia przypadków z Bejrutu — szybko rozwijającego się miasta — i Walencji — stosunkowo stabilnego — pokazują, że model potrafi zarówno uwidocznić intensywne prace budowlane, jak i pewnie zgłosić „brak zmian”, gdy krajobraz pozostaje stabilny. Eksperymenty ablacyjne, w których komponenty są usuwane lub modyfikowane, pokazują znaczny spadek wydajności bez projektu siamskiego, transformatora czy wieloskalowego dekodera, potwierdzając, że to ich współdziałanie — nie tylko rozmiar modelu — napędza poprawę wyników.
Co to oznacza dla życia na Ziemi
Dla osób niebędących specjalistami kluczowy wniosek jest taki, że dysponujemy teraz bardziej niezawodnym sposobem przekształcania surowych zdjęć satelitarnych w precyzyjne mapy zmian na poziomie piksela. TransSiamUNet potrafi wykrywać nowe budynki, znikające tereny zielone oraz zasięg powodzi czy innych katastrof z większą pewnością i mniejszą liczbą fałszywych alarmów niż wiele wcześniejszych systemów. To czyni go obiecującym narzędziem dla agencji i organizacji potrzebujących terminowych, wiarygodnych informacji o rozwoju miast, ewolucji infrastruktury i reakcji środowiska na stres klimatyczny. W miarę jak konstelacje satelitów się powiększają, a archiwa zdjęć pogłębiają, podejścia tego typu — łączące lokalne detale z globalnym kontekstem — będą kluczowe dla utrzymania jasnego, aktualnego obrazu naszej zmieniającej się planety.
Cytowanie: Ali, F., Labib, S.S., Mahmoud, A. et al. TransSiamUNet based transformer-augmented Siamese-U-Net for precise change detection in satellite imagery. Sci Rep 16, 11689 (2026). https://doi.org/10.1038/s41598-026-43164-w
Słowa kluczowe: wykrywanie zmian satelitarnych, zdalne wykrywanie AI, monitorowanie rozrostu miast, modele głębokiego uczenia, vision transformers