Clear Sky Science · en
TransSiamUNet based transformer-augmented Siamese-U-Net for precise change detection in satellite imagery
Watching Earth Evolve from Above
Every day, fleets of satellites quietly photograph our planet, capturing new roads, buildings, floods, fires, and shrinking forests. Turning these floods of pixels into clear, trustworthy maps of what has changed on the ground is crucial for city planners, disaster responders, and environmental scientists—but it is also surprisingly hard. This paper presents TransSiamUNet, an artificial intelligence system designed to sift through pairs of satellite images and precisely highlight what has really changed, while ignoring distractions such as clouds, shadows, and shifting sunlight.
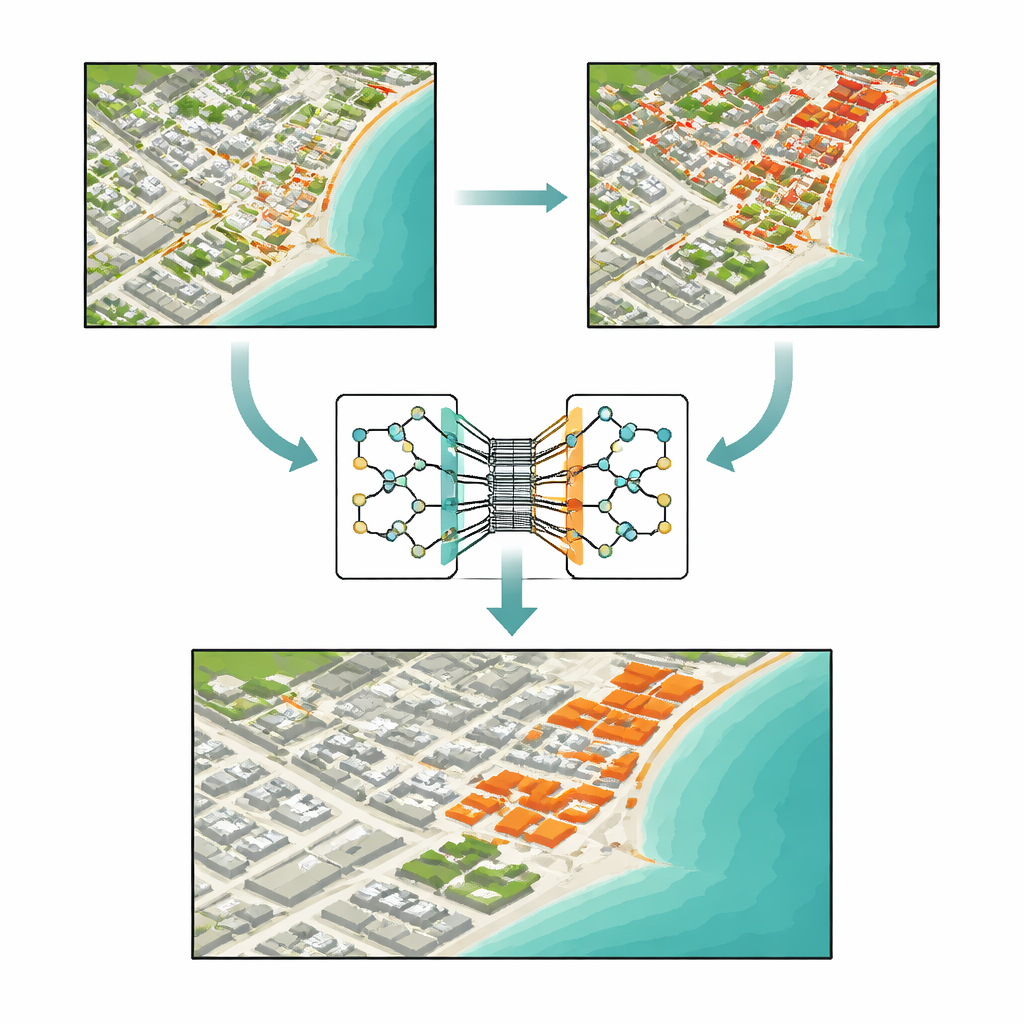
Why Finding Real Change Is So Difficult
At first glance, spotting change between two images seems as simple as subtracting one picture from another. Traditional methods do just that: they compare brightness, take ratios of colors, or measure distance between pixel values. These approaches are fast and easy to implement, but they are easily fooled. Differences in lighting, haze, sensor noise, or slight misalignment can look like genuine change, while small but important shifts—such as a new house or a narrow road—may span only a few pixels and be completely missed. As satellite images grow richer, with many spectral bands and large areas, these older tools struggle to separate meaningful transformations from background clutter.
Deep Learning Steps In
In recent years, deep learning has reshaped remote sensing by letting computers learn patterns directly from data instead of relying on hand-crafted formulas. Convolutional neural networks and "Siamese" pairs of networks have been trained to compare two images of the same place taken at different times. Architectures like U-Net can turn those learned features into detailed maps that mark each pixel as "changed" or "unchanged." More recently, transformer models—originally developed for language—have been adapted to images, where they excel at capturing long-range relationships across a scene, such as how distant buildings or fields relate to each other. However, each family of models has weaknesses: Siamese networks may miss the big picture, pure transformers can blur fine details, and many hybrids combine parts without fully exploiting their strengths together.
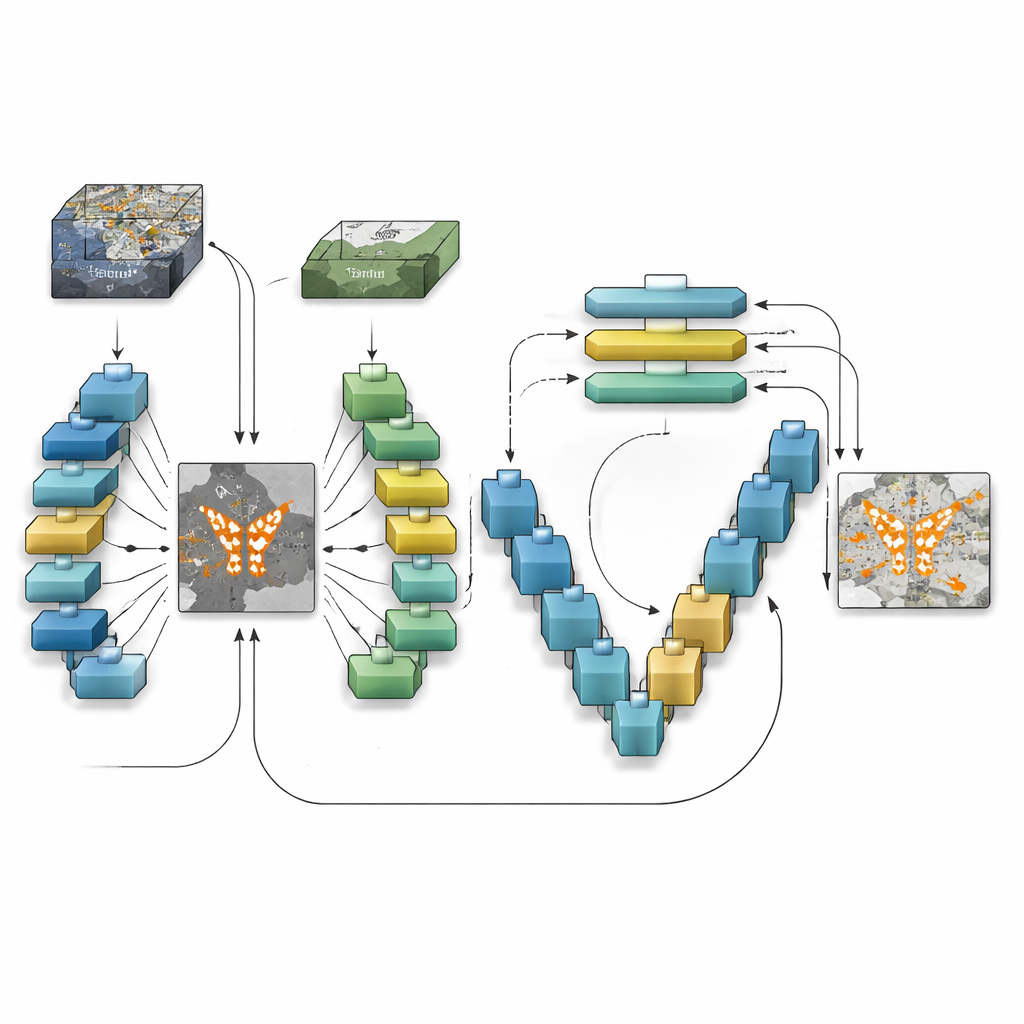
How the New Model Sees Change
TransSiamUNet was designed to blend the best qualities of these ideas into a single, coordinated system. It starts with a Siamese encoder: two identical neural branches that process the "before" and "after" images in the same way, ensuring that differences are not caused by the model itself. Their outputs are then subtracted to produce a focused "difference map" that emphasizes where the scene might have changed. Instead of feeding the raw images into a transformer, the authors send only this difference map into a Vision Transformer block. This encourages the transformer to spend its attention budget on the structures that are actually changing rather than on the static background, helping it understand how distant changed regions relate across the whole image.
Zooming Back In to the Pixel Level
Once the transformer has built a global understanding of the candidate changes, TransSiamUNet passes this information to a U-shaped decoder. This decoder gradually upsamples the compressed features back to full resolution, while pulling in fine-grained details from earlier layers through skip connections. In effect, the model combines a wide-angle view of the whole scene with local, sharp outlines of roads, buildings, and fields. The authors also experiment with simple clean-up steps, such as morphological filters and probabilistic smoothing, to tidy the boundaries of detected areas. Careful tests on three benchmark datasets that span different cities, resolutions, and types of land use show that the full combination—Siamese encoder, transformer bottleneck, and U-Net decoder—outperforms versions missing any one of these parts.
Proving It Works in Real Cities
Using a standard dataset called OSCD, along with two large collections focused on building changes in Texas and New Zealand, the authors compare TransSiamUNet against both traditional and cutting-edge deep learning methods. Under identical training and evaluation conditions, the new model reaches an accuracy of about 94% on OSCD, beating strong competitors that include pure convolutional networks, transformer-based systems, and newer sequence models. Detailed case studies of Beirut—a rapidly growing city—and Valencia—a largely stable one—illustrate that the model can both highlight intense construction and confidently report "no change" when the landscape is steady. Ablation experiments, where components are removed or altered, show that performance drops sharply without the Siamese design, the transformer, or the multi-scale decoder, confirming that their interaction—not just model size—drives the gains.
What This Means for Life on the Ground
For non-specialists, the key outcome is that we now have a more reliable way to turn raw satellite images into precise, pixel-level change maps. TransSiamUNet can detect new buildings, disappearing green spaces, and the footprint of floods or other disasters with greater confidence and fewer false alarms than many earlier systems. That makes it a promising tool for agencies and organizations that need timely, trustworthy information about how cities grow, how infrastructure evolves, and how the environment responds to climate stress. As satellite constellations expand and image archives deepen, approaches like this—combining local detail with global context—will be central to keeping a clear, up-to-date picture of our changing planet.
Citation: Ali, F., Labib, S.S., Mahmoud, A. et al. TransSiamUNet based transformer-augmented Siamese-U-Net for precise change detection in satellite imagery. Sci Rep 16, 11689 (2026). https://doi.org/10.1038/s41598-026-43164-w
Keywords: satellite change detection, remote sensing AI, urban growth monitoring, deep learning models, vision transformers