Clear Sky Science · de
TransSiamUNet: transformer-unterstützte Siamese-U-Net für präzise Veränderungsdetektion in Satellitenbildern
Die Erde von oben beim Verändern beobachten
Jeden Tag fotografieren Flotten von Satelliten stillschweigend unseren Planeten und erfassen neue Straßen, Gebäude, Überschwemmungen, Brände und schrumpfende Wälder. Aus diesen Pixelmengen verlässliche Karten dessen zu machen, was sich am Boden tatsächlich verändert hat, ist für Stadtplaner, Einsatzkräfte bei Katastrophen und Umweltforscher entscheidend – und überraschend schwierig. Dieses Paper stellt TransSiamUNet vor, ein KI-System, das Paare von Satellitenbildern durchsucht und präzise hervorhebt, was wirklich verändert wurde, während Ablenkungen wie Wolken, Schatten und wechselndes Sonnenlicht ignoriert werden.
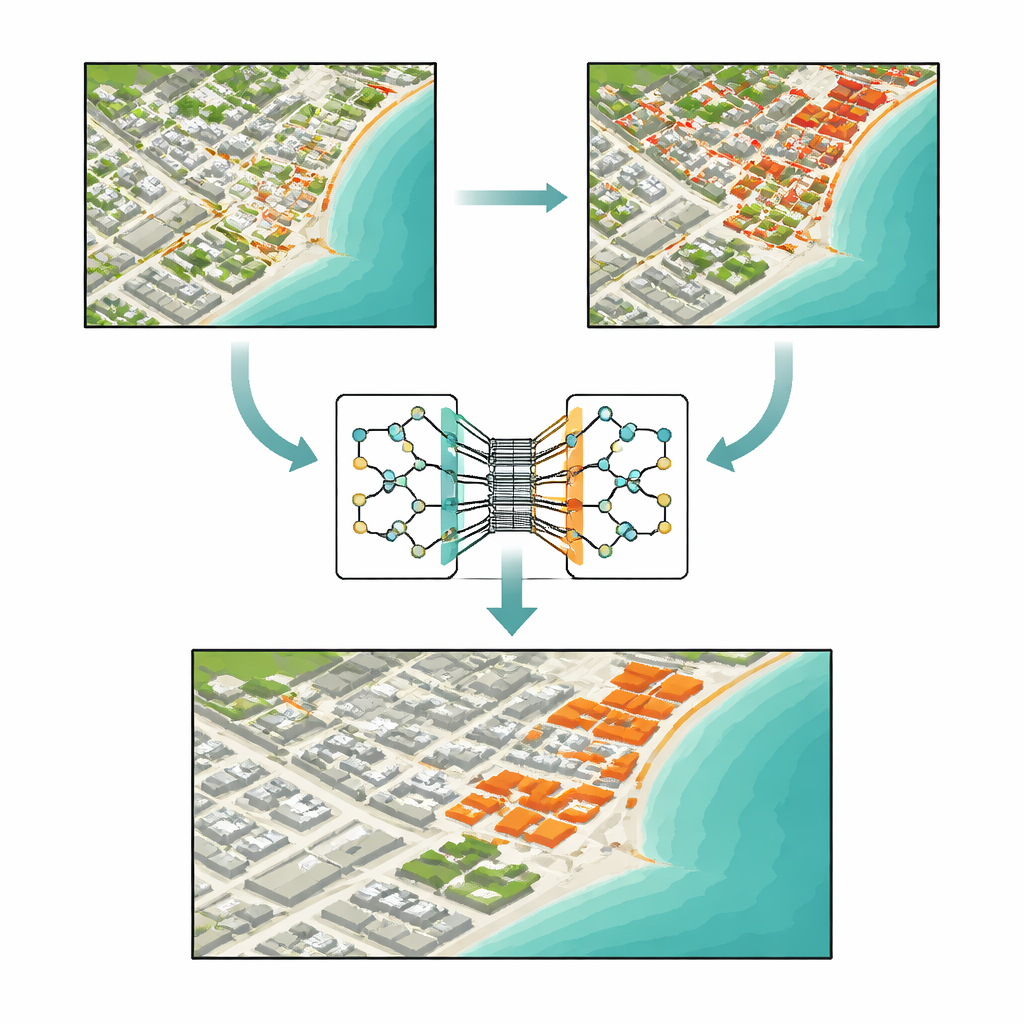
Warum echte Veränderungen so schwer zu finden sind
Auf den ersten Blick scheint es einfach zu sein, Veränderungen zwischen zwei Bildern zu erkennen: Man subtrahiert ein Bild vom anderen. Traditionelle Methoden tun genau das: Sie vergleichen Helligkeit, bilden Farbratios oder messen Abstände zwischen Pixelwerten. Diese Ansätze sind schnell und leicht zu implementieren, aber sie werden leicht getäuscht. Unterschiede in Beleuchtung, Dunst, Sensorrauschen oder leichte Fehlausrichtungen können wie echte Veränderungen aussehen, während kleine, aber wichtige Änderungen – etwa ein neues Haus oder eine schmale Straße – nur wenige Pixel umfassen und völlig übersehen werden können. Da Satellitenbilder immer reichhaltiger werden, mit vielen Spektralbändern und großen Flächen, tun sich diese älteren Werkzeuge schwer damit, bedeutsame Transformationen von Hintergrundrauschen zu trennen.
Deep Learning greift ein
In den letzten Jahren hat Deep Learning die Fernerkundung verändert, indem Computer Muster direkt aus Daten lernen, statt sich auf handgefertigte Formeln zu stützen. Faltungsnetzwerke und „Siamese“-Paare von Netzwerken wurden darauf trainiert, zwei Aufnahmen derselben Stelle zu unterschiedlichen Zeiten zu vergleichen. Architekturen wie U-Net können diese gelernten Merkmale in detaillierte Karten übersetzen, die jedes Pixel als „verändert“ oder „unverändert“ kennzeichnen. Neuerdings wurden Transformer-Modelle – ursprünglich für Sprache entwickelt – auf Bilder adaptiert; sie sind besonders gut darin, langreichweitige Beziehungen in einer Szene zu erfassen, zum Beispiel wie entfernte Gebäude oder Felder zueinander stehen. Jede Modellfamilie hat jedoch Schwächen: Siamese-Netzwerke können das große Ganze übersehen, reine Transformer neigen dazu, feine Details zu verwischen, und viele Hybride kombinieren Teile, ohne ihre Stärken wirklich zusammen auszuschöpfen.
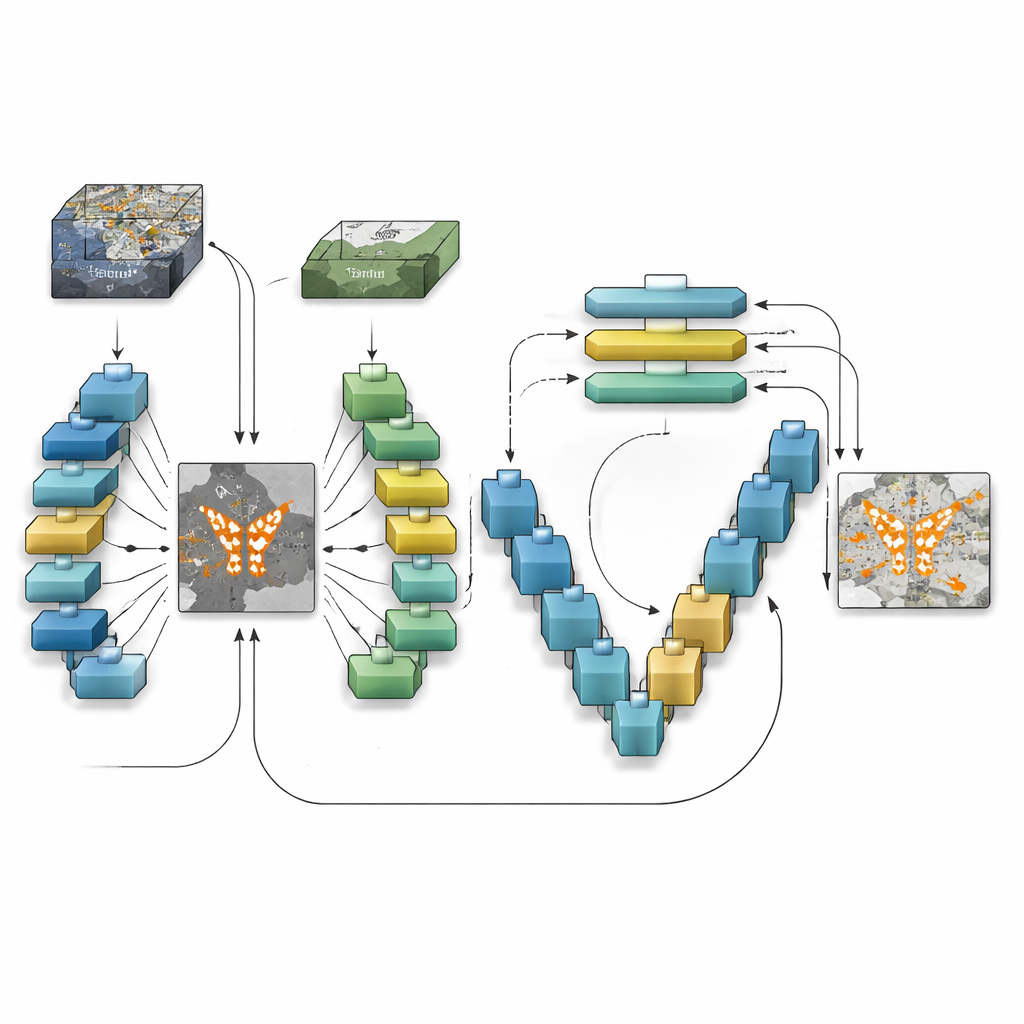
Wie das neue Modell Veränderungen erkennt
TransSiamUNet wurde entwickelt, um die besten Eigenschaften dieser Ideen in einem koordinierten System zu vereinen. Es beginnt mit einem Siamese-Encoder: zwei identische neuronale Zweige, die das „Vorher“- und das „Nachher“-Bild auf die gleiche Weise verarbeiten, sodass Unterschiede nicht vom Modell selbst verursacht werden. Deren Ausgaben werden anschließend subtrahiert, um eine fokussierte „Differenzkarte“ zu erzeugen, die betont, wo sich die Szene möglicherweise verändert hat. Statt die Rohbilder in einen Transformer zu speisen, geben die Autoren nur diese Differenzkarte in einen Vision-Transformer-Block. Das zwingt den Transformer dazu, sein Aufmerksamkeitsbudget auf die Strukturen zu konzentrieren, die tatsächlich im Wandel sind, statt auf den statischen Hintergrund, und hilft ihm zu verstehen, wie entfernte veränderte Regionen über das gesamte Bild zusammenhängen.
Wieder heranzoomen auf Pixel-Ebene
Sobald der Transformer ein globales Verständnis der Kandidaten für Veränderungen aufgebaut hat, übergibt TransSiamUNet diese Information an einen U-förmigen Decoder. Dieser Decoder sampelt die komprimierten Merkmale schrittweise wieder auf volle Auflösung hoch und zieht dabei feinkörnige Details aus früheren Schichten über Skip-Verbindungen heran. Effektiv kombiniert das Modell eine Weitwinkelansicht der gesamten Szene mit lokalen, scharfen Konturen von Straßen, Gebäuden und Feldern. Die Autoren experimentieren außerdem mit einfachen Aufräumschritten wie morphologischen Filtern und probabilistischer Glättung, um die Ränder der detektierten Flächen zu säubern. Sorgfältige Tests an drei Benchmark-Datensätzen, die verschiedene Städte, Auflösungen und Nutzungsarten abdecken, zeigen, dass die vollständige Kombination – Siamese-Encoder, Transformer-Bottleneck und U-Net-Decoder – Versionen ohne einen dieser Teile übertrifft.
Der Nachweis in realen Städten
Mithilfe eines Standarddatensatzes namens OSCD sowie zweier großer Sammlungen, die sich auf Gebäudeveränderungen in Texas und Neuseeland konzentrieren, vergleichen die Autoren TransSiamUNet mit traditionellen und modernen Deep-Learning-Methoden. Unter identischen Trainings- und Evaluierungsbedingungen erreicht das neue Modell auf OSCD eine Genauigkeit von etwa 94 % und schlägt damit starke Konkurrenz, zu der reine Faltungsnetze, transformerbasierte Systeme und neuere Sequenzmodelle gehören. Detaillierte Fallstudien zu Beirut – einer schnell wachsenden Stadt – und Valencia – einer weitgehend stabilen Stadt – zeigen, dass das Modell sowohl intensive Bautätigkeit hervorheben als auch bei ruhiger Landschaft zuverlässig „keine Veränderung“ melden kann. Ablationsstudien, bei denen Komponenten entfernt oder verändert werden, zeigen, dass die Leistung stark abfällt ohne das Siamese-Design, den Transformer oder den multiskaligen Decoder, was bestätigt, dass ihr Zusammenspiel – und nicht nur die Modellgröße – die Verbesserungen antreibt.
Was das für das Leben am Boden bedeutet
Für Nicht-Spezialisten ist das zentrale Ergebnis, dass wir jetzt eine verlässlichere Methode haben, rohe Satellitenbilder in präzise, pixelgenaue Veränderungskarten zu verwandeln. TransSiamUNet kann neue Gebäude, verschwindende Grünflächen und die Ausdehnung von Überschwemmungen oder anderen Katastrophen mit größerer Sicherheit und weniger Fehlalarmen erkennen als viele frühere Systeme. Das macht es zu einem vielversprechenden Werkzeug für Behörden und Organisationen, die zeitnahe, vertrauenswürdige Informationen darüber benötigen, wie Städte wachsen, wie Infrastruktur sich entwickelt und wie die Umwelt auf Klimastress reagiert. Mit der Ausweitung von Satellitenkonstellationen und dem Wachsen von Bildarchiven werden Ansätze wie dieser – die lokale Details mit globalem Kontext verbinden – zentral dafür sein, ein klares, aktuelles Bild unseres sich verändernden Planeten zu behalten.
Zitation: Ali, F., Labib, S.S., Mahmoud, A. et al. TransSiamUNet based transformer-augmented Siamese-U-Net for precise change detection in satellite imagery. Sci Rep 16, 11689 (2026). https://doi.org/10.1038/s41598-026-43164-w
Schlüsselwörter: Veränderungsdetektion in Satellitenbildern, Fernerkundungs-KI, Überwachung des Stadtwachstums, Deep-Learning-Modelle, Vision-Transformer