Clear Sky Science · it
TransSiamUNet: transformer-augmentato Siamese-U-Net per un rilevamento preciso dei cambiamenti nelle immagini satellitari
Osservare l'evoluzione della Terra dall'alto
Ogni giorno flotte di satelliti fotografano silenziosamente il nostro pianeta, catturando nuove strade, edifici, alluvioni, incendi e foreste in diminuzione. Trasformare questi flussi di pixel in mappe chiare e affidabili di ciò che è cambiato sul terreno è cruciale per pianificatori urbani, soccorritori e scienziati ambientali—ma è anche sorprendentemente difficile. Questo articolo presenta TransSiamUNet, un sistema di intelligenza artificiale progettato per analizzare coppie di immagini satellitari e mettere in evidenza con precisione ciò che è effettivamente cambiato, ignorando distrazioni come nuvole, ombre e variazioni di illuminazione.
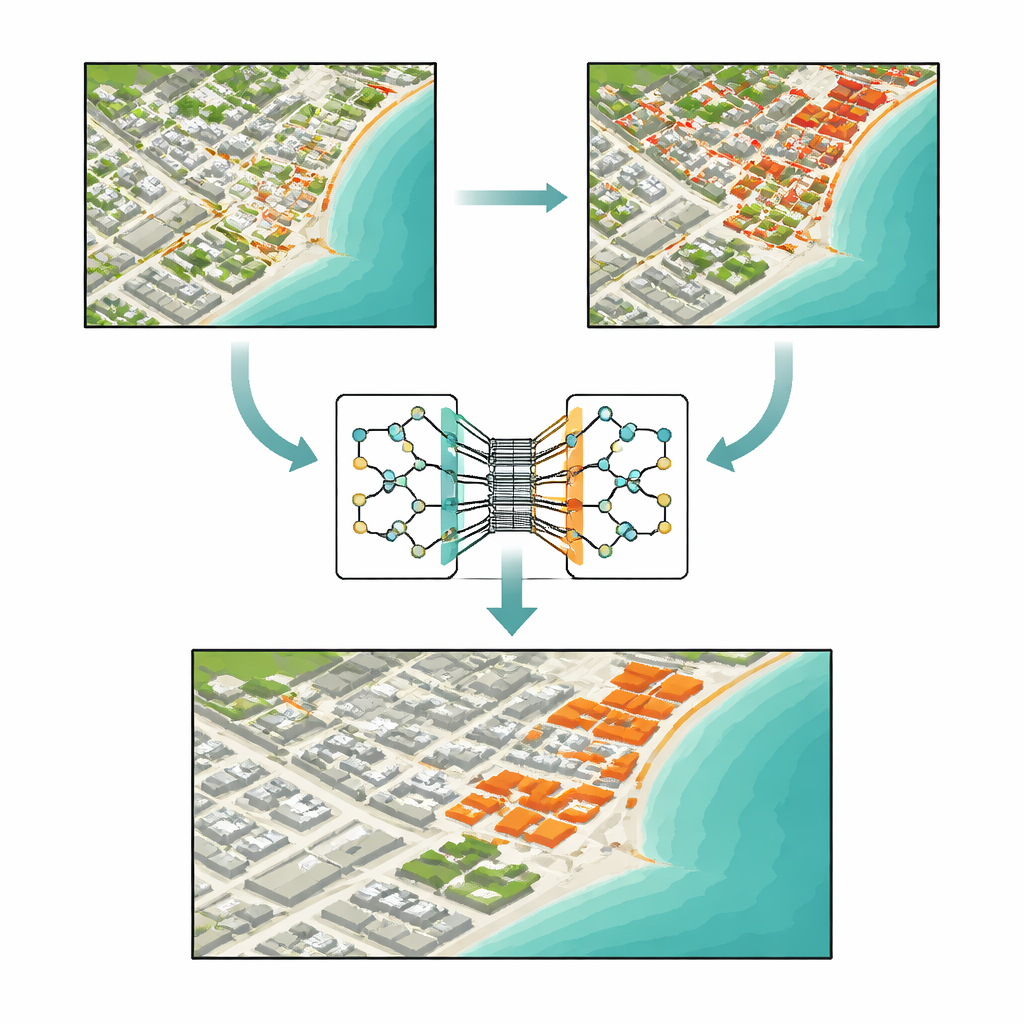
Perché trovare il cambiamento reale è così difficile
A prima vista, individuare il cambiamento tra due immagini sembra semplice come sottrarre un'immagine dall'altra. I metodi tradizionali fanno proprio questo: confrontano la luminosità, calcolano rapporti cromatici o misurano la distanza tra valori di pixel. Questi approcci sono veloci e facili da implementare, ma sono facilmente ingannati. Differenze di illuminazione, foschia, rumore del sensore o lievi disallineamenti possono sembrare cambiamenti genuini, mentre spostamenti piccoli ma importanti—come una nuova casa o una strada stretta—possono coprire solo pochi pixel e venire completamente persi. Con l'aumento della ricchezza delle immagini satellitari, con molte bande spettrali e vaste aree, questi strumenti più vecchi faticano a separare le trasformazioni significative dal rumore di fondo.
Il deep learning entra in gioco
Negli ultimi anni il deep learning ha trasformato il telerilevamento permettendo ai computer di apprendere pattern direttamente dai dati invece di fare affidamento su formule costruite a mano. Reti neurali convoluzionali e coppie “Siamese” di reti sono state addestrate a confrontare due immagini dello stesso luogo scattate in momenti diversi. Architetture come U-Net possono trasformare queste caratteristiche apprese in mappe dettagliate che etichettano ogni pixel come “cambiato” o “invariato”. Più recentemente, i modelli transformer—originariamente sviluppati per il linguaggio—sono stati adattati alle immagini, dove eccellono nel catturare relazioni a lungo raggio attraverso una scena, per esempio come edifici o campi distanti si relazionano tra loro. Tuttavia, ogni famiglia di modelli ha debolezze: le reti Siamese possono perdere la visione d'insieme, i transformer puri possono sfumare i dettagli fini, e molti ibridi combinano parti senza sfruttarne pienamente i punti di forza congiunti.
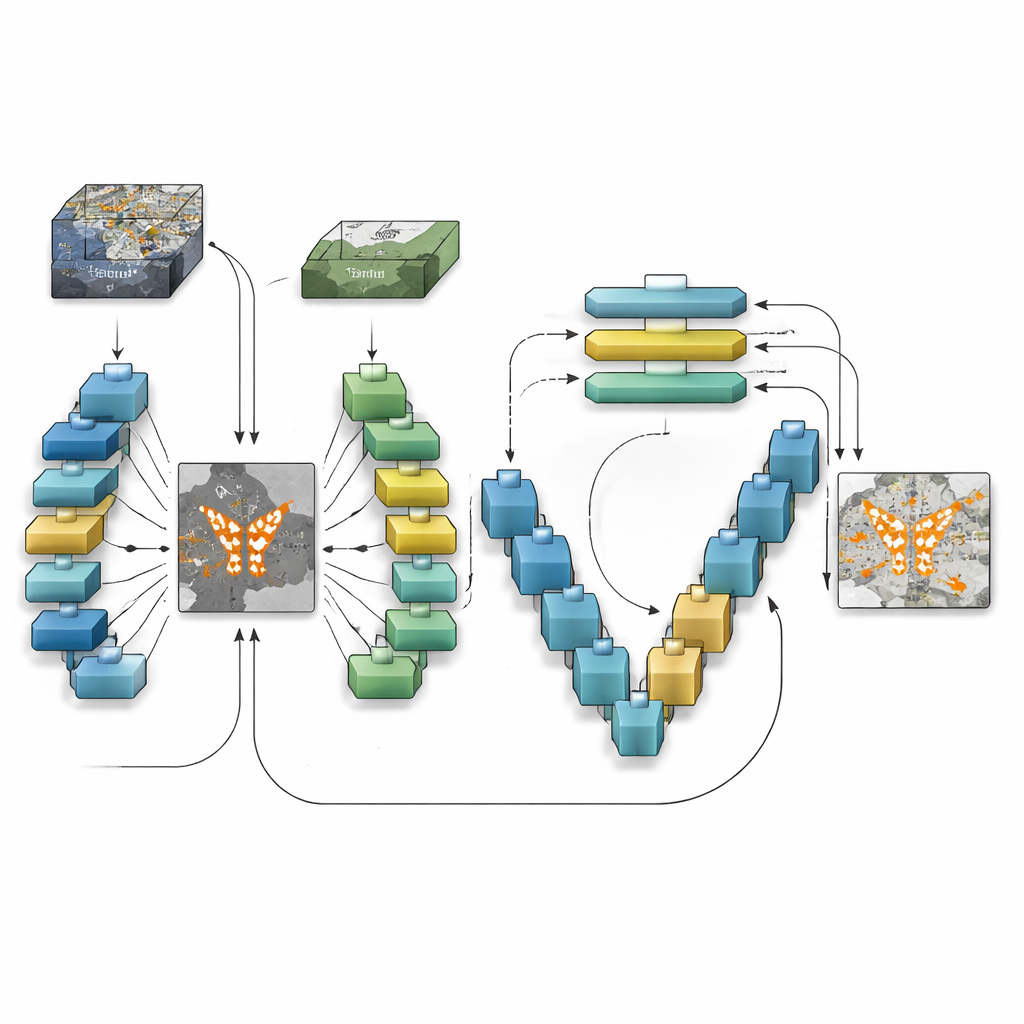
Come il nuovo modello vede il cambiamento
TransSiamUNet è stato progettato per fondere le migliori qualità di queste idee in un unico sistema coordinato. Inizia con un encoder Siamese: due rami neurali identici che elaborano le immagini “prima” e “dopo” nello stesso modo, assicurando che le differenze non siano causate dal modello stesso. I loro output vengono poi sottratti per produrre una mappa di differenza focalizzata che evidenzia dove la scena potrebbe essere cambiata. Invece di alimentare le immagini grezze in un transformer, gli autori inviano solo questa mappa di differenza in un blocco Vision Transformer. Ciò incoraggia il transformer a concentrare il suo budget di attenzione sulle strutture che stanno realmente cambiando piuttosto che sullo sfondo statico, aiutandolo a comprendere come regioni cambiate lontane tra loro si relazionano sull'intera immagine.
Ritornare a livello di pixel
Una volta che il transformer ha costruito una comprensione globale dei cambiamenti candidati, TransSiamUNet trasferisce queste informazioni a un decoder a forma di U. Questo decoder ricampiona gradualmente le caratteristiche compresse fino alla risoluzione piena, attingendo dettagli fini da strati precedenti tramite connessioni skip. In effetti, il modello combina una visione grandangolare dell'intera scena con contorni locali nitidi di strade, edifici e campi. Gli autori sperimentano anche semplici passaggi di pulizia, come filtri morfologici e lisciamento probabilistico, per rifinire i confini delle aree rilevate. Test accurati su tre dataset di riferimento che coprono diverse città, risoluzioni e tipi di uso del suolo mostrano che la combinazione completa—encoder Siamese, collo transformer e decoder U-Net—supera le versioni cui manca una di queste parti.
Dimostrare l'efficacia nelle città reali
Utilizzando un dataset standard chiamato OSCD, insieme a due grandi raccolte focalizzate sui cambiamenti edilizi in Texas e Nuova Zelanda, gli autori confrontano TransSiamUNet con metodi tradizionali e all'avanguardia basati su deep learning. A parità di condizioni di addestramento e valutazione, il nuovo modello raggiunge un'accuratezza di circa il 94% su OSCD, superando forti concorrenti che includono reti puramente convoluzionali, sistemi basati su transformer e modelli di sequenza più recenti. Studi di caso dettagliati su Beirut—una città in rapida crescita—e Valencia—per lo più stabile—illustrano che il modello può sia mettere in luce intense attività edilizie sia segnalare con fiducia “nessun cambiamento” quando il paesaggio è stabile. Esperimenti di ablazione, in cui componenti sono rimossi o modificati, mostrano che le prestazioni calano drasticamente senza il design Siamese, il transformer o il decoder multi-scala, confermando che è l'interazione tra le parti—non solo la dimensione del modello—a guidare i miglioramenti.
Cosa significa per la vita sul terreno
Per i non specialisti, il risultato chiave è che ora disponiamo di un modo più affidabile per trasformare immagini satellitari grezze in mappe di cambiamento precise a livello di pixel. TransSiamUNet può rilevare nuovi edifici, la scomparsa di aree verdi e l'impronta di alluvioni o altre catastrofi con maggiore fiducia e meno falsi allarmi rispetto a molti sistemi precedenti. Questo lo rende uno strumento promettente per agenzie e organizzazioni che hanno bisogno di informazioni tempestive e affidabili su come le città crescono, come evolve l'infrastruttura e come l'ambiente risponde allo stress climatico. Con l'espansione delle costellazioni satellitari e l'approfondirsi degli archivi di immagini, approcci come questo—che combinano dettaglio locale e contesto globale—saranno centrali per mantenere un quadro chiaro e aggiornato del nostro pianeta in cambiamento.
Citazione: Ali, F., Labib, S.S., Mahmoud, A. et al. TransSiamUNet based transformer-augmented Siamese-U-Net for precise change detection in satellite imagery. Sci Rep 16, 11689 (2026). https://doi.org/10.1038/s41598-026-43164-w
Parole chiave: rilevamento dei cambiamenti satellitari, AI telerilevamento, monitoraggio della crescita urbana, modelli di deep learning, vision transformer