Clear Sky Science · fr
TransSiamUNet : transformer-augmenté Siamese-U-Net pour une détection précise des changements dans l’imagerie satellite
Observer l’évolution de la Terre depuis les hauteurs
Chaque jour, des flottes de satellites photographient discrètement notre planète, capturant de nouvelles routes, bâtiments, inondations, incendies et forêts qui rétrécissent. Transformer ces flux de pixels en cartes claires et fiables des changements au sol est crucial pour les urbanistes, les intervenants en cas de catastrophe et les scientifiques de l’environnement — mais c’est aussi étonnamment difficile. Cet article présente TransSiamUNet, un système d’intelligence artificielle conçu pour analyser des paires d’images satellite et mettre en évidence avec précision ce qui a réellement changé, tout en ignorant des distractions comme les nuages, les ombres et les variations d’éclairage.
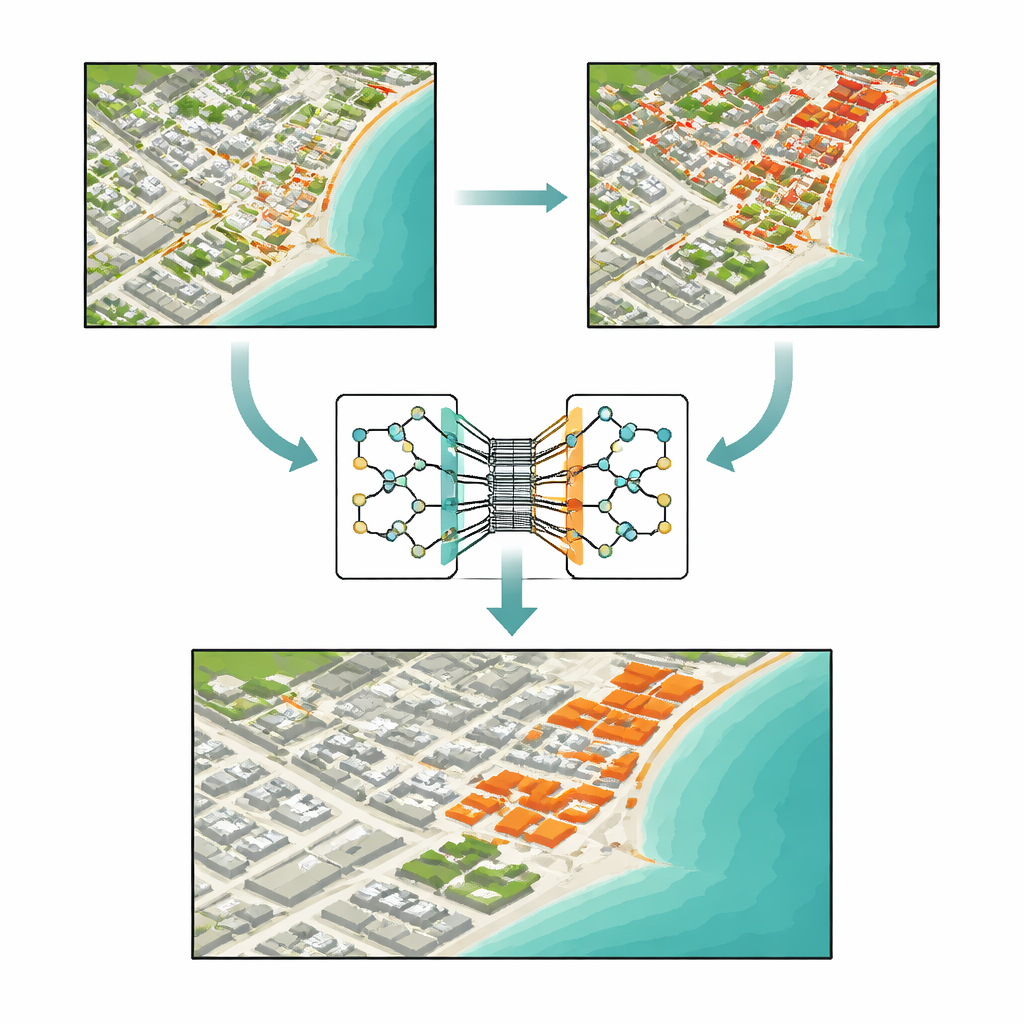
Pourquoi repérer le vrai changement est si difficile
À première vue, repérer un changement entre deux images semble aussi simple que de soustraire une image de l’autre. Les méthodes traditionnelles font justement cela : elles comparent la luminosité, calculent des rapports de couleurs ou mesurent la distance entre valeurs de pixels. Ces approches sont rapides et faciles à mettre en œuvre, mais elles se laissent facilement tromper. Des différences d’éclairage, la brume, le bruit du capteur ou un léger désalignement peuvent ressembler à des changements réels, tandis que des modifications petites mais importantes — comme une nouvelle maison ou une voie étroite — peuvent ne couvrir que quelques pixels et passer complètement inaperçues. À mesure que les images satellite deviennent plus riches, avec de nombreuses bandes spectrales et de vastes zones, ces outils anciens peinent à séparer les transformations significatives du bruit de fond.
L’apprentissage profond entre en jeu
Ces dernières années, l’apprentissage profond a transformé la télédétection en permettant aux ordinateurs d’apprendre des motifs directement à partir des données plutôt que de s’appuyer sur des formules manuelles. Les réseaux de neurones convolutionnels et les paires « siamese » de réseaux ont été entraînés pour comparer deux images du même lieu prises à des moments différents. Des architectures comme U-Net peuvent convertir ces caractéristiques apprises en cartes détaillées qui marquent chaque pixel comme « changé » ou « inchangé ». Plus récemment, les modèles transformer — initialement développés pour le langage — ont été adaptés aux images, où ils excellent à capturer des relations à longue portée à travers une scène, par exemple comment des bâtiments ou des champs éloignés se relient entre eux. Toutefois, chaque famille de modèles a ses faiblesses : les réseaux siamese peuvent manquer la vue d’ensemble, les transformers purs peuvent estomper les détails fins, et de nombreux hybrides assemblent des éléments sans exploiter pleinement leurs forces combinées.
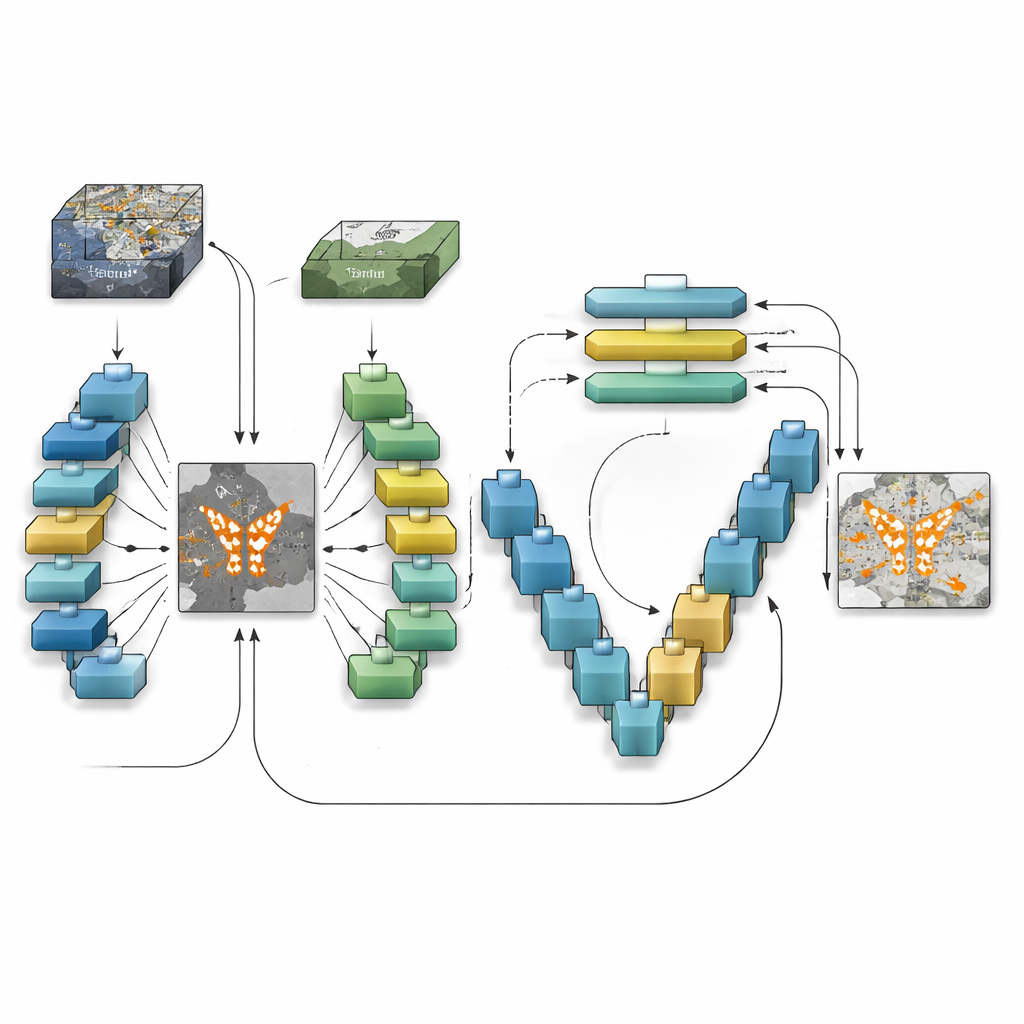
Comment le nouveau modèle perçoit le changement
TransSiamUNet a été conçu pour fusionner les meilleures qualités de ces approches en un système coordonné. Il commence par un encodeur siamese : deux branches neuronales identiques qui traitent les images « avant » et « après » de la même manière, garantissant que les différences ne proviennent pas du modèle lui‑même. Leurs sorties sont ensuite soustraites pour produire une « carte de différence » focalisée qui met en évidence les zones susceptibles d’avoir changé. Plutôt que d’alimenter les images brutes dans un transformer, les auteurs n’envoient que cette carte de différence dans un bloc Vision Transformer. Cela incite le transformer à concentrer son attention sur les structures réellement changeantes plutôt que sur l’arrière‑plan statique, ce qui l’aide à comprendre comment des régions modifiées distantes se rapportent entre elles à l’échelle de l’image.
Retour au niveau du pixel
Une fois que le transformer a construit une compréhension globale des changements candidats, TransSiamUNet transmet cette information à un décodeur en forme de U. Ce décodeur remonte progressivement les caractéristiques compressées jusqu’à la résolution complète, tout en réinjectant des détails fins depuis les couches antérieures via des connexions de saut. En pratique, le modèle combine une vue grand angle de l’ensemble de la scène avec des contours locaux et nets des routes, bâtiments et champs. Les auteurs expérimentent également des étapes simples de nettoyage, comme des filtres morphologiques et un lissage probabiliste, pour assainir les frontières des zones détectées. Des évaluations soignées sur trois jeux de référence couvrant différentes villes, résolutions et types d’usage des sols montrent que la combinaison complète — encodeur siamese, goulot transformer et décodeur U‑Net — surpasse les variantes auxquelles il manque l’un de ces éléments.
Validation dans des villes réelles
En utilisant un jeu de données standard nommé OSCD, ainsi que deux grandes collections centrées sur les changements de bâtiments au Texas et en Nouvelle‑Zélande, les auteurs comparent TransSiamUNet à la fois aux méthodes traditionnelles et aux approches d’apprentissage profond de pointe. Dans des conditions d’entraînement et d’évaluation identiques, le nouveau modèle atteint environ 94 % de précision sur OSCD, surpassant des concurrents solides incluant des réseaux convolutionnels purs, des systèmes à base de transformers et des modèles de séquence plus récents. Des études de cas détaillées sur Beyrouth — une ville en forte croissance — et Valence — une ville plutôt stable — illustrent que le modèle peut à la fois mettre en évidence une construction intense et déclarer avec assurance « pas de changement » lorsque le paysage est stable. Des expériences d’ablation, où des composants sont retirés ou modifiés, montrent que les performances chutent fortement sans le design siamese, le transformer ou le décodeur multi‑échelle, confirmant que c’est leur interaction — et pas seulement la taille du modèle — qui génère les gains.
Ce que cela signifie pour le terrain
Pour les non‑spécialistes, le principal résultat est que nous disposons désormais d’un moyen plus fiable de transformer des images satellite brutes en cartes de changement précises au niveau du pixel. TransSiamUNet peut détecter de nouveaux bâtiments, la disparition d’espaces verts et l’emprise d’inondations ou d’autres catastrophes avec plus de confiance et moins de faux positifs que de nombreux systèmes précédents. Cela en fait un outil prometteur pour les agences et organisations qui ont besoin d’informations opportunes et fiables sur la croissance des villes, l’évolution des infrastructures et la réponse de l’environnement au stress climatique. À mesure que les constellations de satellites s’étendent et que les archives d’images s’enrichissent, des approches de ce type — combinant détail local et contexte global — seront au cœur du maintien d’une image claire et à jour de notre planète en mutation.
Citation: Ali, F., Labib, S.S., Mahmoud, A. et al. TransSiamUNet based transformer-augmented Siamese-U-Net for precise change detection in satellite imagery. Sci Rep 16, 11689 (2026). https://doi.org/10.1038/s41598-026-43164-w
Mots-clés: détection de changements satellite, IA en télédétection, suivi de la croissance urbaine, modèles d’apprentissage profond, transformers visuels