Clear Sky Science · pl
Z-Calling: narzędzie do rozróżniania A/Z (2,6-diaminopuryna) i wykrywania dZ-DNA przy użyciu odczytów PacBio HiFi
Dlaczego nowy rodzaj DNA ma znaczenie
DNA często opisuje się jako uniwersalny plan życia, zbudowany z czterech dobrze znanych liter: A, T, C i G. Jednak niektóre wirusy łamią tę zasadę, zastępując literę A chemicznym odpowiednikiem zwanym Z, co wzmacnia ich DNA i utrudnia jego atakowanie. To odkrycie sugeruje istnienie ukrytej warstwy różnorodności genetycznej o dużych implikacjach dla biotechnologii, medycyny, a nawet przechowywania danych. Wyzwanie było proste do sformułowania, lecz trudne do rozwiązania: jak niezawodnie znaleźć i zmapować to nietypowe Z-DNA, zwłaszcza gdy jest zmieszane z zwykłym DNA? W tym badaniu przedstawiono Z-Calling — narzędzie obliczeniowe, które wreszcie to umożliwia, korzystając z dostępnej technologii sekwencjonowania długich odczytów.
Dziwna litera w alfabecie genetycznym
W większości organizmów zasada adenina (A) łączy się z tyminą (T) przez dwa wiązania wodorowe, co pomaga stabilizować klasyczną podwójną helisę DNA. Niektóre bakteriofagi — wirusy atakujące bakterie — wyewoluowały zastąpienie A przez 2,6-diaminopurynę, zwaną w skrócie Z. Z tworzy z T trzy wiązania wodorowe, co zwiększa stabilność helisy i zmienia jej właściwości fizyczne. Ta nietypowa chemia może dawać wirusom zawierającym Z przewagę nad mechanizmami obronnymi gospodarza i otwiera możliwości projektowania cząsteczek o lepszych właściwościach. Badacze wykazali już, że Z może zwiększać precyzję testów genetycznych, modulować reakcje edycji genów CRISPR i zmniejszać reakcje immunologiczne wobec eksperymentalnych leków opartych na RNA. Jednak bez sposobu dokładnego określenia, gdzie Z występuje w nici DNA, trudno było w pełni zrozumieć lub wykorzystać te korzyści.
Obecne narzędzia zawodzą
Standardowe technologie sekwencjonowania DNA zakładają, że sygnały wyglądające jak A rzeczywiście są adeninem, więc mają tendencję do błędnego odczytywania Z jako zwykłego A. Metody chemiczne, takie jak wysokosprawna chromatografia cieczowa, potrafią wykryć ilość Z w próbce masowej, ale nie powiedzą, gdzie każdy Z znajduje się w genomie, szczególnie w złożonych próbkach środowiskowych mieszających wiele gatunków. Niektóre platformy trzeciej generacji, np. urządzenia nanopore, teoretycznie są na tyle czułe, by wyczuć różnicę między zasadami, ale w praktyce ich sygnały bywają zaszumione i trudne do interpretacji przy obecności nietypowej chemii. Do tej pory brakowało wygodnego, wiarygodnego sposobu na skanowanie złożonych mieszanin DNA i jasne oddzielenie zwykłego DNA od DNA zawierającego Z, lub na rozróżnianie A i Z literę po literze.
Słuchając rytmu syntezy DNA
Autorzy skupili się na technologii PacBio Circular Consensus Sequencing, która wielokrotnie kopiuje tę samą cząsteczkę DNA i rejestruje nie tylko którą zasadę dodano, ale też tempo, w jakim następuje dodanie. Dwa pomiary czasowe — szerokość impulsu (jak długo polimeraza zajmuje się dodaniem zasady) oraz odstęp między impulsami (pauza między dodaniami) — tworzą coś w rodzaju ścieżki rytmicznej dla syntezy DNA. Porównując wiele starannie zaprojektowanych próbek DNA, w tym zwykłe DNA, całkowicie zastąpione DNA zawierające Z oraz hybrydowe molekuły, w których A i Z współistnieją, zespół wykazał, że zamiana A na Z powoduje subtelne, lecz spójne zmiany w czasie. Zmiany te zależą od sąsiedniego kontekstu sekwencji i głównie wpływają na szerokość impulsu w wąskim oknie wokół miejsca Z, przy jednoczesnym zachowaniu ogólnej dokładności sekwencjonowania niemal na poziomie DNA niemodyfikowanego.
Jak Z-Calling wykrywa ukryte zasady Z
Wykorzystując te wzorce czasowe, badacze wytrenowali modele uczenia maszynowego, by rozpoznawały kinetyczny „akcent” Z. Ich narzędzie, Z-Calling, pełni dwie główne funkcje. Po pierwsze klasyfikuje całe odczyty sekwencji jako zwykłe DNA lub DNA zawierające Z, nawet w sztucznych metagenomach mieszających wiele gatunków i chemii. Robi to, używając sieci neuronowej do ocenienia, jak prawdopodobne jest, że każda pozycja wyglądająca na A jest Z, a następnie wprowadzając rozkład tych ocen do maszyny wektorów nośnych, która decyduje, czy cały odczyt pochodzi z DNA-Z. Po drugie wykonuje dyskryminację na poziomie pojedynczej litery, przypisując każdą pozycję do A lub Z na podstawie lokalnego kontekstu sekwencji i sygnałów kinetycznych. W różnych zestawach danych pochodzących od bakterii, drożdży, roślin, zwierząt i naturalnie Z-zawierającego faga modele osiągnęły wysoką dokładność (wartości pola pod krzywą oscylujące w okolicach 0,94–0,98), porównywalną z czołowymi narzędziami wykrywającymi powszechne modyfikacje metylacji DNA.
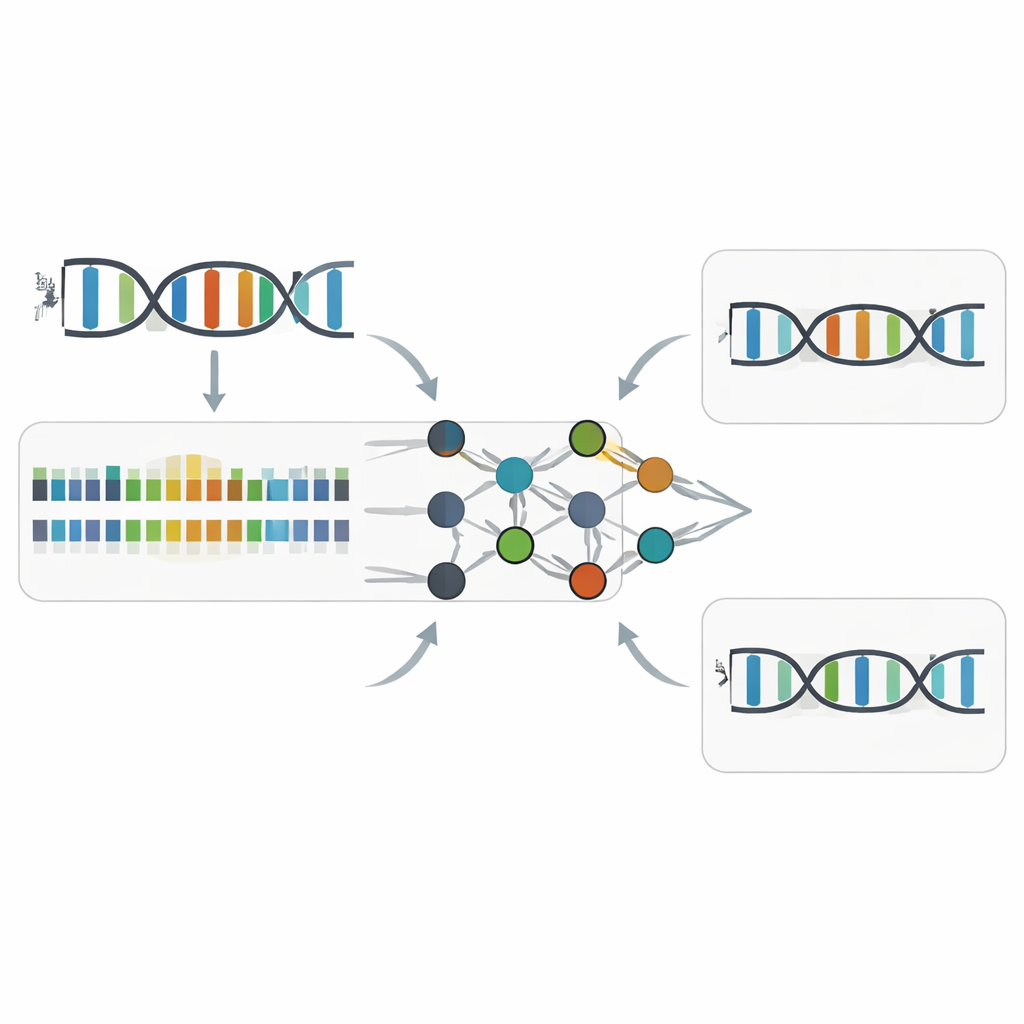
Testy w warunkach rzeczywistych
Aby pokazać, że Z-Calling działa poza czystymi konstrukcjami laboratoryjnymi, autorzy zastosowali je do inżynierskiego szczepu drożdży, który częściowo zastępuje adeniny Z w całym genomie. Analiza chemiczna wskazała, że około jedna czwarta wszystkich pozycji wyglądających na A stała się Z. Z-Calling niezależnie oszacowało podobny udział i zmapowało, jak Z był rozproszony w chromosomach drożdży i plazmidach, ukazując w przybliżeniu losowy rozkład. Narzędzie zeskanowało też mieszane zbiory danych, w których tylko niewielki ułamek odczytów należał do wirusów zawierających Z lub genów hybrydowych. Nawet gdy odczyty z Z-DNA stanowiły zaledwie około jednego procenta wszystkich, Z-Calling potrafiło nadal wykryć ich obecność z wysoką pewnością, przy jednoczesnym bardzo niskim odsetku fałszywych alarmów w wielu genomach kontrolnych bogatych w naturalne znaki epigenetyczne.
Co to oznacza na przyszłość
Przekształcając subtelne odchylenia czasowe w sekwencjonowaniu DNA w wyraźne sygnały, Z-Calling dostarcza pierwszego praktycznego sposobu systematycznego mapowania występowania zasad Z, literę po literze i genom po genomie. Dla szerokiego odbiorcy kluczowy wniosek jest taki, że nasz alfabet genetyczny jest bardziej elastyczny, niż wcześniej sądzono, i teraz mamy sposób, by odczytać jedną z jego najbardziej intrygujących alternatywnych liter z wysoką rozdzielczością. Ta możliwość pomoże naukowcom szukać kolejnych wirusów opartych na Z w przyrodzie, walidować organizmy inżynieryjne wykorzystujące Z dla zwiększenia stabilności lub nowych funkcji oraz badać egzotyczne polimery podobne do DNA do bezpiecznego przechowywania informacji i zaawansowanych terapii. Krótko mówiąc, Z-Calling przekształca mało znaną ciekawostkę chemiczną w cechę namierzalną w genomach świata rzeczywistego.
Cytowanie: Wu, B., Chen, Y., Zhou, Y. et al. Z-Calling: a tool for A/Z (2,6-diaminopurine) base calling and dZ-DNA detection using PacBio HiFi reads. Commun Biol 9, 594 (2026). https://doi.org/10.1038/s42003-026-09849-8
Słowa kluczowe: Z-DNA, niekanoniczne zasady, sekwencjonowanie PacBio, uczenie maszynowe w genomice, genomika fagów